You are here
python 网络爬虫入门(一)———第一个python爬虫实例 python网络爬虫入门(二)———模拟登陆知乎 python网络爬虫入门(三)———多线程
python 网络爬虫入门(一)———第一个python爬虫实例
最近两天学习了一下python,并自己写了一个网络爬虫的例子。
python版本: 3.5
IDE : pycharm 5.0.4
要用到的包可以用pycharm下载:
File->Default Settings->Default Project->Project Interpreter
选择python版本并点右边的加号安装想要的包 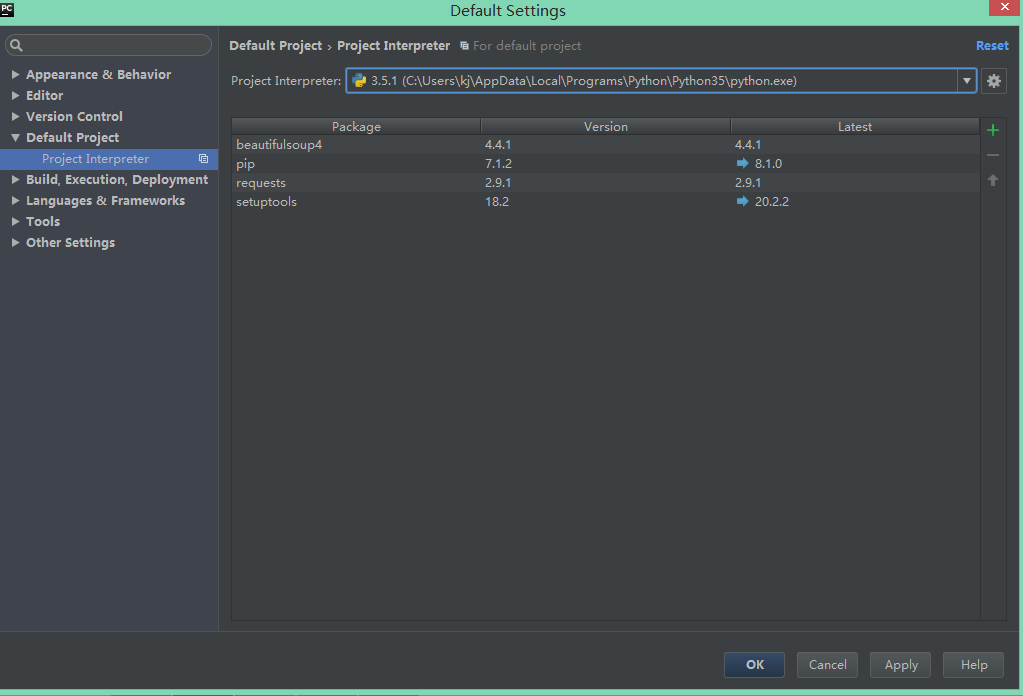
我选择的网站是中国天气网中的苏州天气,准备抓取最近7天的天气以及最高/最低气温
http://www.weather.com.cn/weather/101190401.shtml 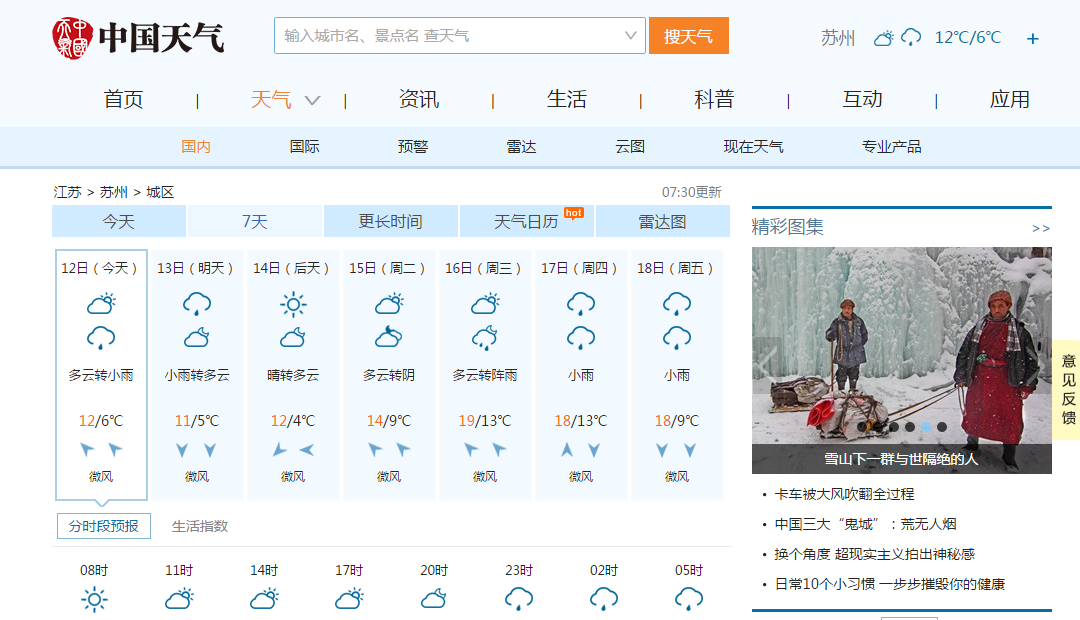
程序开头我们添加:
这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中文。
要引用的包:
requests:用来抓取网页的html源代码
csv:将数据写入到csv文件中
random:取随机数
time:时间相关操作
socket和http.client 在这里只用于异常处理
BeautifulSoup:用来代替正则式取源码中相应标签中的内容
urllib.request:另一种抓取网页的html源代码的方法,但是没requests方便(我一开始用的是这一种)
获取网页中的html代码:
header是requests.get的一个参数,目的是模拟浏览器访问
header 可以使用chrome的开发者工具获得,具体方法如下:
打开chrome,按F12,选择network 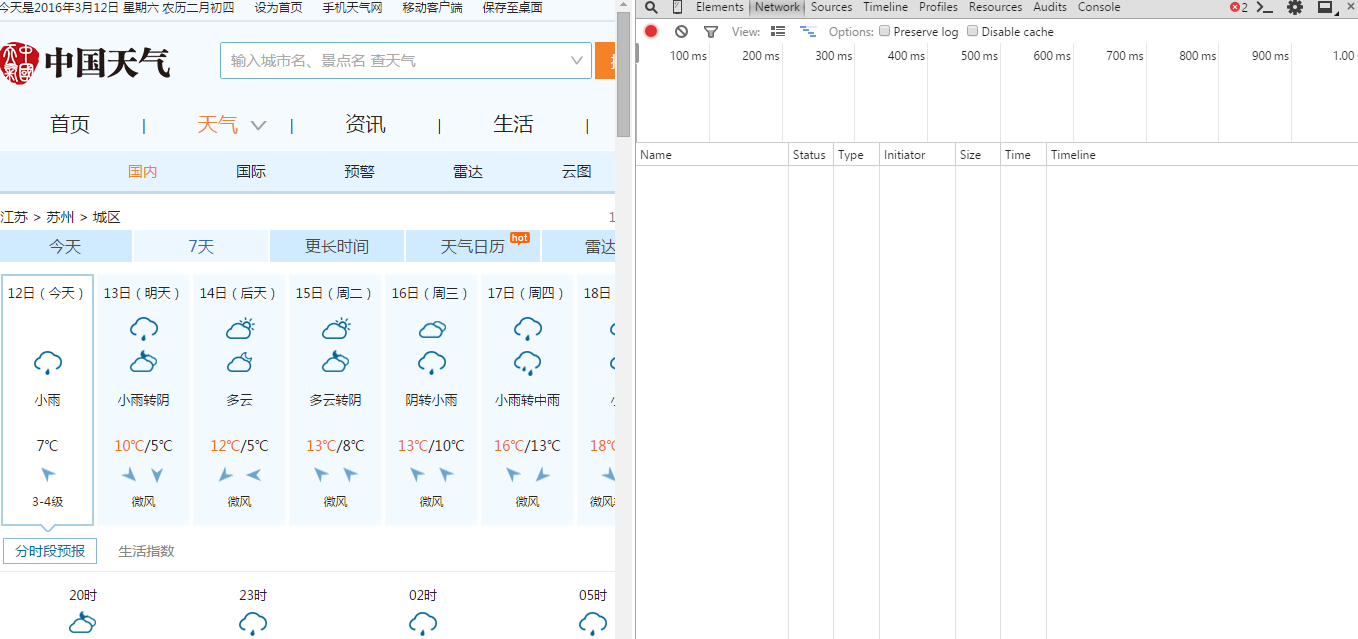
重新访问该网站,找到第一个网络请求,查看它的header 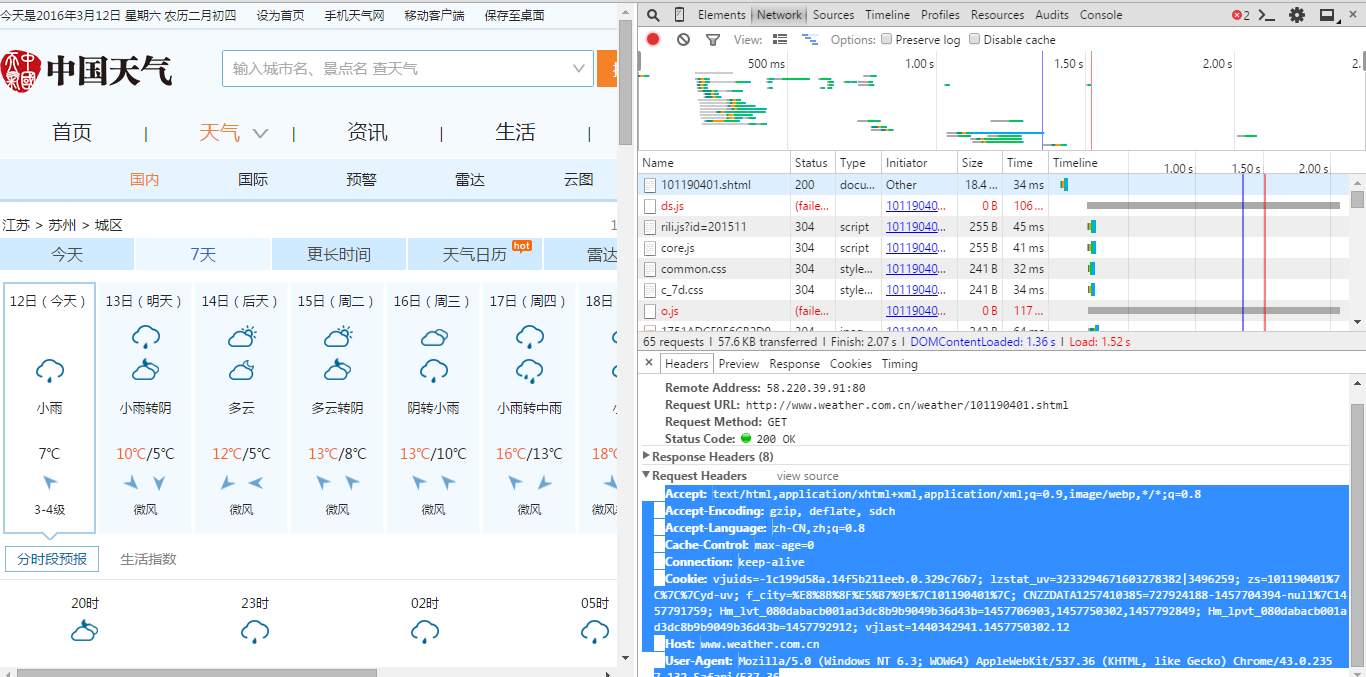
timeout是设定的一个超时时间,取随机数是因为防止被网站认定为网络爬虫。
然后通过requests.get方法获取网页的源代码、
rep.encoding = ‘utf-8’是将源代码的编码格式改为utf-8(不该源代码中中文部分会为乱码)
下面是一些异常处理
返回 rep.text
获取html中我们所需要的字段:
这里我们主要要用到BeautifulSoup
BeautifulSoup 文档http://www.crummy.com/software/BeautifulSoup/bs4/doc/
首先还是用开发者工具查看网页源码,并找到所需字段的相应位置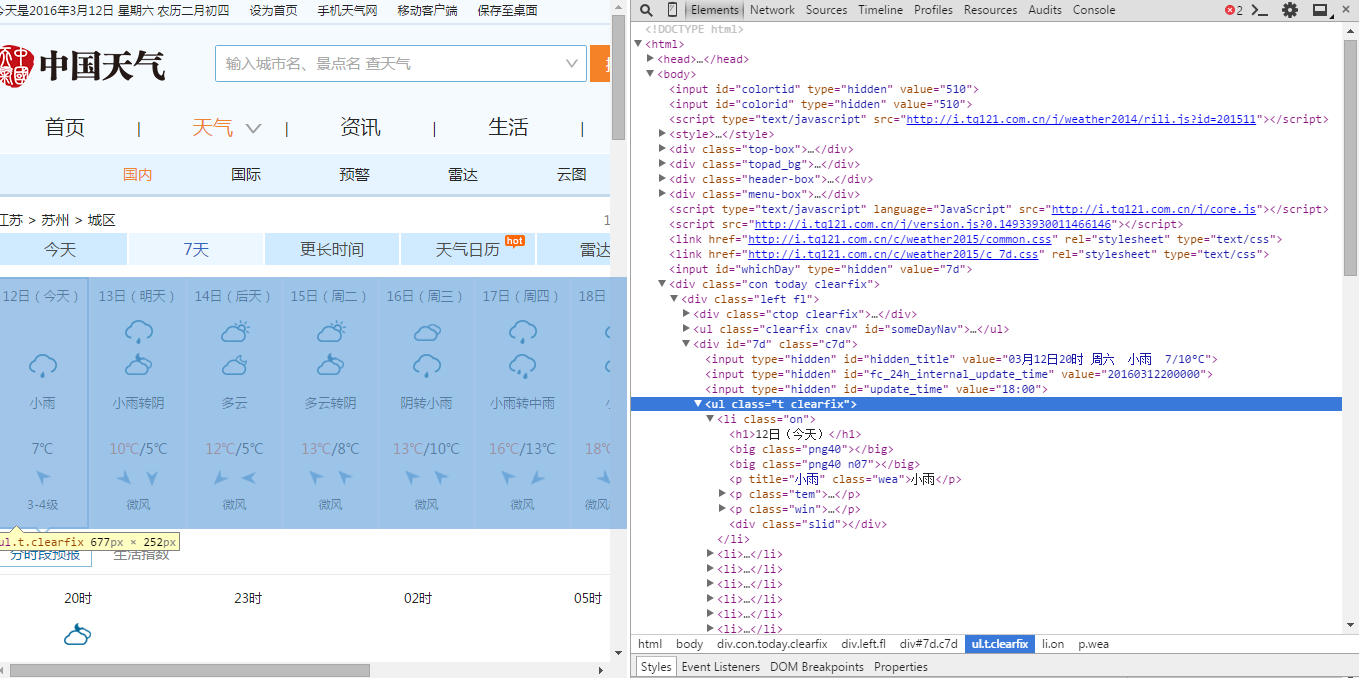
找到我们需要字段都在 id = “7d”的“div”的ul中。日期在每个li中h1 中,天气状况在每个li的第一个p标签内,最高温度和最低温度在每个li的span和i标签中。
感谢Joey_Ko指出的错误:到了傍晚,当天气温会没有最高温度,所以要多加一个判断。
代码如下:
写入文件csv:
将数据抓取出来后我们要将他们写入文件,具体代码如下:
主函数:
然后运行一下:
生成的weather.csv文件如下: 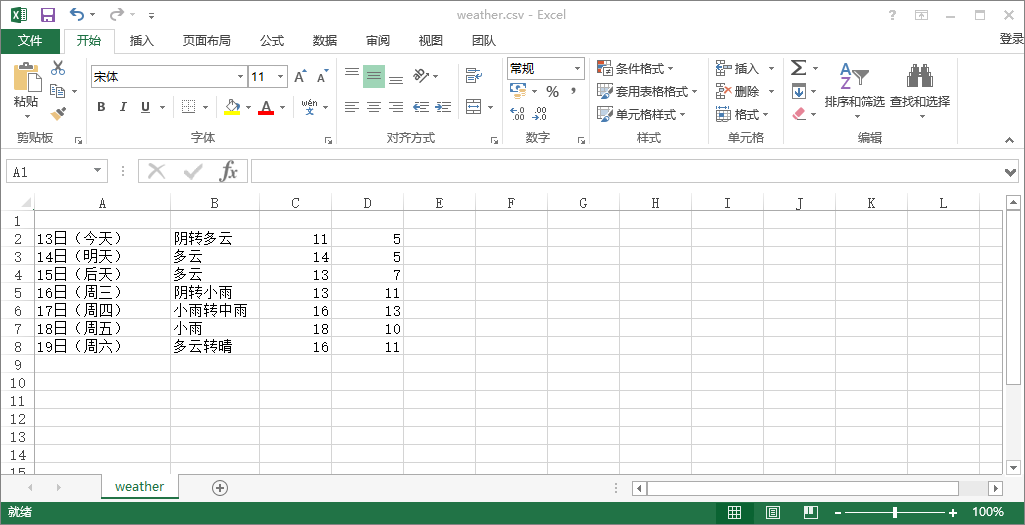
总结一下,从网页上抓取内容大致分3步:
1、模拟浏览器访问,获取html源代码
2、通过正则匹配,获取指定标签中的内容
3、将获取到的内容写到文件中
刚学python爬虫,可能有些理解有错误的地方,请大家批评指正,谢谢!
30楼 rainbow120957分钟前发表

没有找到生成的csv文件
29楼 ccmedu6天前 14:31发表

pip install beautifulsoup4 下载包,就可以用 beautifulsoup4 了,楼主很厉害
28楼 huzuxiong2017-12-14 22:38发表

感谢,学了几个小时,涨了不少姿势
27楼 qq_209345392017-12-13 17:25发表

一直显示NameError:name 'name' is not defined,是按照你的代码来写的,不知道怎么就解决,谢谢
26楼 叶峰润2017-12-06 16:02发表

li = ul.find_all('li')#获取所有li部分,没有获取到所有的内容,只是获取了标签名,里面的内容没有获取到,导致获取日期等值的时候报错了,怎么解决啊
[<li class="sky skyid lv1 on">\n<h1>6\u65e5\uff08\u4eca\u5929\uff09</h1>\n<big class="png40 d00"></big>\n<big class="png40 n00"></big>\n<p class="wea" title="\u6674">\u6674</p>\n<p class="tem">\n<span>11</span>/<i>4\u2103</i>\n</p>\n<p class="
25楼 readimprove2017-11-01 09:54发表

作者真棒!!!学了好多东西从里面。
24楼 qq_350463142017-10-31 21:03发表

请问那个http.client安装不上咋办啊
23楼 kookob2017-10-31 10:55发表

python3.6的安装 BeautifulSoup变成 beautifulsoup4
22楼 weixin_405092992017-10-13 21:21发表

为什么我开头就报错了
21楼 LaoChengZier2017-10-08 09:38发表

小白一枚,感谢分享。不过想问一下,应该如何设置csv保存路径
20楼 qq_341142162017-09-28 17:27发表

赞,运行成功,文件就在编写python文件的同目录下.
19楼 wwj004772017-09-19 18:53发表

get_content显示的内容是 id='today'
id=‘’7d‘’ 的显示与 填的header有关吗?
18楼 HLiu_2017-08-20 10:39发表

为什么定义get_content()这个函数的时候,要写两个参数呢,第二个data参数不是并没有用到嘛,新手求问~
Re: wwj004772017-09-19 18:55发表
回复Duaduatua:给urllib.request用的参数,默认库不带requests库,要自己安装
17楼 qq_369358932017-08-15 16:14发表

为什么我没错误 但是运行完了没文件
16楼 lp9252422017-08-11 15:54发表

# with open(file_name, 'a', errors='ignore', newline='') as f:
TypeError: file() takes at most 3 arguments (4 given)Re: lp9252422017-08-11 15:54发表
回复lp925242:这是么情况怎么解决啊
15楼 lp9252422017-08-11 15:51发表
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
SyntaxError: Non-ASCII character '\xe5' in file but no encoding declared
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象这一行报错了 怎么解决啊
14楼 qq_357842482017-07-27 17:49发表

13楼 baidu_341285362017-07-18 14:23发表

NameError: name 'get_connet' is not defined报这个错怎么解决?
12楼 砰啪噗叽噗叽2017-05-17 10:45发表

赞!有个小问题:网页显示12号今天,csv中显示13号今天
11楼 qq_383140102017-04-13 22:28发表

我的电脑是Thinkpad的点F12不能出现network怎么办
Re: hfchao11262017-05-30 17:59发表

回复qq_38314010:按F5刷新下
10楼 budongaiqing82017-03-16 08:46发表

Python网络爬虫实战教程(全套完整版)
课程观看地址:http://www.xuetuwuyou.com/course/168
9楼 技术宅girl哈哈哈哈哈哈2016-12-05 18:52发表

请问抓取那一串代码我放上去报错“Unsupported characters in input”怎么解决呢
8楼 技术宅girl哈哈哈哈哈哈2016-12-05 18:51发表
请问抓取那一串代码我放上去报错“Unsupported characters in input”怎么解决呢
7楼 qq_351267722016-11-30 20:14发表

赞!代码简洁明了,调式方便!叼叼叼
Re: sinat_353144212016-12-07 14:08发表

回复qq_35126772:QAQ 不行
6楼 hucong7452016-11-21 09:56发表

为啥我跑不通?刚学Python不知道问题出在哪里
5楼 qq_342819622016-10-19 17:04发表

有源码吗,或者是项目的结构
Re: Bo_wen_2016-11-21 23:22发表

回复qq_34281962:http://pan.baidu.com/s/1hsbnwTu
Re: qq_342819622016-11-26 20:03发表
回复Bo_wen_:x谢谢
4楼 hilary2022016-10-14 15:21发表

写好的csv存在哪里?我怎么找不到?程序没有报错了。
Re: rainbow120955分钟前发表
回复hilary202:这个问题解决了么,我也出现这个问题了
Re: Bo_wen_2016-11-21 23:25发表
回复hilary202:应该就是在python程序的位置
Re: qq_364499022016-10-19 20:55发表

回复hilary202:我也遇到这个问题。请问你解决了吗
3楼 qq_363542092016-10-10 13:54发表

在vs 不会弄。在IED 更不会弄,求指点
2楼 hitlx2016-09-28 17:00发表

感谢楼主,按照这个流程,我完成了第一个python程序 非常感谢
1楼 JoeyKo2016-03-13 22:42发表

Re: Bo_wen_2016-03-13 23:50发表
回复gx15366039985:感谢,我写代码的时候是白天,没发现这个问题,已修改
Re: sinat_395680522017-07-20 12:00发表

运行不了 不知道为什么
C:\Users\Administrator\AppData\Local\Programs\Python\Python35\python.exe C:/Users/Administrator/PycharmProjects/untitled1/weather
Traceback (most recent call last):
File "C:/Users/Administrator/PycharmProjects/untitled1/weather", line 2, in <module>
import requests
File "C:\Users\Administrator\AppData\Roaming\Python\Python35\site-packages\requests\__init__.py", line 97, in <module>
from . import utils
File "C:\Users\Administrator\AppData\Roaming\Python\Python35\site-packages\requests\utils.py", line 24, in <module>
from . import certs
File "C:\Users\Administrator\AppData\Roaming\Python\Python35\site-packages\requests\certs.py", line 15, in <module>
from certifi import where
ImportError: No module named 'certifi'
Process finished with exit code 1Re: qq_396409882017-07-31 16:01发表

回复sinat_39568052:你这库都没有安装,你看缺啥就安啥,不然你不能import
来自 http://blog.csdn.net/bo_wen_/article/details/50868339
python网络爬虫入门(二)———模拟登陆知乎
上次我写了第一个网络爬虫是抓取的天气状况,这次来尝试一下登录。
首先,像之前一样,取得header的信息。
和之前的例子不同,登录需要向服务器发送一些信息,如账号、密码等。
同样,可以使用chrome的开发者工具 在network里勾选Preseve log。
然后手动执行一次登录的过程,找到一个叫email的网络请求,在header的底部有data所包含的字段,为 _xsrf,password,remember_me和 email。其中_xsrf字段可从登录页面的源码中获取。
这次,我们要创建一个session来保存相关信息和记住登录状态。
代码如下:
顶
1
踩
0
来自 http://blog.csdn.net/Bo_wen_/article/details/50911423
多线程,是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理或同时多线程处理器。 在一个程序中,这些独立运行的程序片段叫作“线程”,利用它编程的概念就叫作“多线程处理”。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。
在编写网络爬虫的过程中利用多线程,可以提高抓取数据的效率,减少工作时间。如有10000页的数据,每个线程处理2000页的数据,同时进行,所用时间仅为原来的1/5左右。
下面我们来实现多线程:
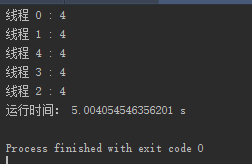
可以发现打印25个数(每打印一个数之前延时1秒)只用了5秒多的时间,提高了效率
8楼 Linton12017-11-02 14:17发表 [回复]
运行程序以后,再一次在浏览器上打开知乎,界面提示
“我们检测到你可能使用了 AdBlock 或 Adblock Plus,它的部分策略可能会影响到正常功能的使用(如关注)。
你可以设定特殊规则或将知乎加入白名单,以便我们更好地提供服务。”
这是什么情况?哪位大神能给解释下?
7楼 摇滚牛奶2017-03-11 21:21发表 [回复]
博主代码有很多问题,想要学习的可以参考https://github.com/xchaoinfo/fuck-login/blob/master/001%20zhihu/zhihu.py
同学的代码,
6楼 行遇书2016-12-02 21:04发表 [回复]
用户名 和 密码 必须用自己的真实用户名和密码吗?
5楼 shencweiwei2016-10-26 09:23发表 [回复]
怎么找Email的网络请求
4楼 shencweiwei2016-10-26 09:22发表 [回复]
1111
3楼 Clark_Linux2016-10-20 19:47发表 [回复]
运行显示这个,出了什么问题呢?
<html><body><h1>500 Server Error</h1>
An internal server error occured.
</body></html>
2楼 Clark_Linux2016-10-20 19:46发表 [回复]
运行显示这个,出了什么问题呢?
<html><body><h1>500 Server Error</h1>
An internal server error occured.
</body></html>
Re: 小二杰2016-10-26 20:37发表 [回复]
回复Clark_Linux:有验证码,作者这个应该没有写完整,需要识别验证码
1楼 qq_342819622016-10-19 17:36发表 [回复]
怎么找Email的网络请求
Re: 小二杰2016-10-26 20:37发表 [回复]
回复qq_34281962:登陆之后找
Re: 行遇书2016-12-02 21:42发表 [回复]
回复qq_18426941:我点击登陆,还是没有找到啊