
MySQL 对 SQL 有很多扩展,有些用起来很方便,但有一些被误用之后会有性能问题,还会有一些意料之外的副作用,比如 REPLACE INTO。
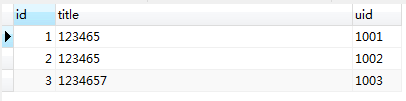
比如有这样一张表:

CREATE TABLE `auto` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL, `v` varchar(100) DEFAULT NULL, `extra` varchar(200) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_k` (`k`) ) ENGINE=InnoD
auto 表有一个自增的 id 字段作为主键,字段 k 有 UNIQUE KEY 做唯一性约束。写入几条记录之后会是这样:
xupeng@diggle7:3600(dba_m) [dba] mysql> INSERT INTO auto (k, v, extra) VALUES (1, '1', 'extra 1'), (2, '2', 'extra 2'), (3, '3', 'extra 3'); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 xupeng@diggle7:3600(dba_m) [dba] mysql> SHOW CREATE TABLE auto\G *************************** 1. row *************************** Table: auto Create Table: CREATE TABLE `auto` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL, `v` varchar(100) DEFAULT NULL, `extra` varchar(200) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_k` (`k`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=latin1 1 row in set (0.01 sec) xupeng@diggle7:3600(dba_m) [dba] mysql> SELECT * FROM auto; +----+---+------+---------+ | id | k | v | extra | +----+---+------+---------+ | 1 | 1 | 1 | extra 1 | | 2 | 2 | 2 | extra 2 | | 3 | 3 | 3 | extra 3 | +----+---+------+---------+ 3 rows in set (0.00 sec)
在 slave 节点上是和 master 一致的:
xupeng@diggle8:3600(dba_s) [dba] mysql> SELECT * FROM auto; +----+---+------+---------+ | id | k | v | extra | +----+---+------+---------+ | 1 | 1 | 1 | extra 1 | | 2 | 2 | 2 | extra 2 | | 3 | 3 | 3 | extra 3 | +----+---+------+---------+ 3 rows in set (0.00 sec) xupeng@diggle8:3600(dba_s) [dba] mysql> SHOW CREATE TABLE auto\G *************************** 1. row *************************** Table: auto Create Table: CREATE TABLE `auto` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL, `v` varchar(100) DEFAULT NULL, `extra` varchar(200) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_k` (`k`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
可以看到,写入三条记录之后,auto 表的 AUTO_INCREMENT 增长为 4,也就是说下一条不手工为 id 指定值的记录,id 字段的值会是 4。
接下来使用 REPLACE INTO 来写入一条记录:
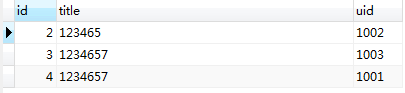
xupeng@diggle7:3600(dba_m) [dba] mysql> REPLACE INTO auto (k, v) VALUES (1, '1-1'); Query OK, 2 rows affected (0.01 sec) xupeng@diggle7:3600(dba_m) [dba] mysql> SELECT * FROM auto; +----+---+------+---------+ | id | k | v | extra | +----+---+------+---------+ | 2 | 2 | 2 | extra 2 | | 3 | 3 | 3 | extra 3 | | 4 | 1 | 1-1 | NULL | +----+---+------+---------+ 3 rows in set (0.00 sec) xupeng@diggle7:3600(dba_m) [dba] mysql> SHOW CREATE TABLE auto\G *************************** 1. row *************************** Table: auto Create Table: CREATE TABLE `auto` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL, `v` varchar(100) DEFAULT NULL, `extra` varchar(200) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_k` (`k`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
可以看到 MySQL 说 “2 rows affected”,可是明明是只写一条记录,为什么呢?这是因为 MySQL 在执行 REPLACE INTO auto (k) VALUES (1) 时首先尝试 INSERT INTO auto (k) VALUES (1),但由于已经存在一条 k=1 的记录,发生了 duplicate key error,于是 MySQL 会先删除已有的那条 k=1 即 id=1 的记录,然后重新写入一条新的记录。
这时候 slave 上出现了诡异的问题:
xupeng@diggle8:3600(dba_s) [dba] mysql> SHOW CREATE TABLE auto\G *************************** 1. row *************************** Table: auto Create Table: CREATE TABLE `auto` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL, `v` varchar(100) DEFAULT NULL, `extra` varchar(200) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_k` (`k`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=latin1
可以知道,当前表内数据 id 字段的最大值是 4,AUTO_INCREMENT 应该为 5,但在 slave 上 AUTO_INCREMENT 却并未更新,这会有什么问题呢?把这个 slave 提升为 master 之后,由于 AUTO_INCREMENT 比实际的 next id 还要小,写入新记录时就会发生 duplicate key error,每次冲突之后 AUTO_INCREMENT += 1,直到增长为 max(id) + 1 之后才能恢复正常:
xupeng@diggle8:3600(dba_s) [dba] mysql> REPLACE INTO auto (k, v) VALUES (4, '4'); ERROR 1062 (23000): Duplicate entry '4' for key 'PRIMARY' xupeng@diggle8:3600(dba_s) [dba] mysql> REPLACE INTO auto (k, v) VALUES (5, '5'); Query OK, 1 row affected (0.00 sec) xupeng@diggle8:3600(dba_s) [dba] mysql> SELECT * FROM auto; +----+---+------+---------+ | id | k | v | extra | +----+---+------+---------+ | 2 | 2 | 2 | extra 2 | | 3 | 3 | 3 | extra 3 | | 4 | 1 | 1-1 | NULL | | 5 | 5 | 5 | NULL | +----+---+------+---------+ 4 rows in set (0.00 sec)
没有预料到 MySQL 在数据冲突时实际上是删掉了旧记录,再写入新记录,这是使用 REPLACE INTO 时最大的一个误区,拿之前的例子来说,执行完 REPLACE INTO auto (k, v) VALUES (1, ‘1-1’) 之后,由于新写入记录时并未给 extra 字段指定值,原记录 extra 字段的值就「丢失」了,而通常这并非是业务上所预期的,更常见的需求实际上是,当存在 k=1 的记录时,就把 v 字段的值更新为 ‘1-1’,其他未指定的字段则保持原状,而满足这一需求的 MySQL 方言是 INSERT INTO auto (k, v) VALUES (1, ‘1-1’) ON DUPLICATE KEY UPDATE v=VALUES(v);
鉴于此,很多使用 REPLACE INTO 的场景,实际上需要的是 INSERT INTO … ON DUPLICATE KEY UPDATE,在正确理解 REPLACE INTO 行为和副作用的前提下,谨慎使用 REPLACE INTO。
来自 https://www.cnblogs.com/monian/archive/2014/10/09/4013784.html