注:在执行SQL语句前加上explain可以查看MySQL的执行计划
数据库:MySQL官方提供的sakila数据库
Max优化:
例如:查询最后支付时间
1
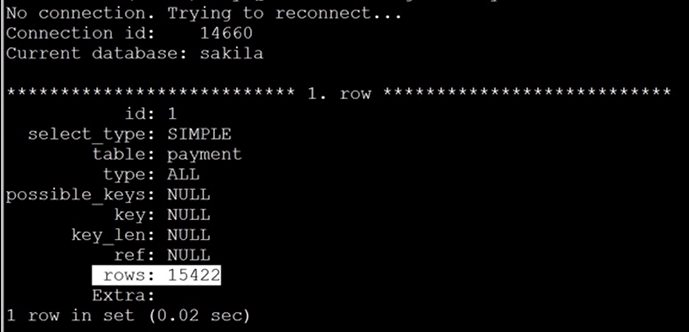
查询的类型为simple,没有用到任何索引,扫描行数为1万多行,用时0.02sec
优化方法:
在payment_date列建立索引
1
然后在执行此sql语句,发现:
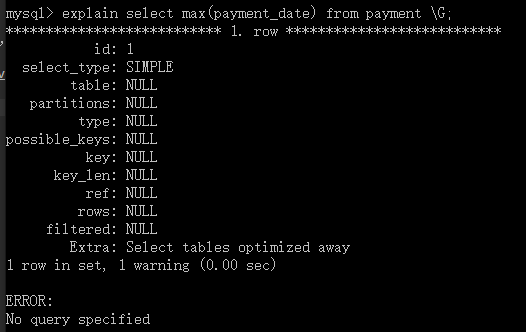
此执行结果的原因为:因为索引是顺序排列的,通过索引,就可以马上知道最后一个是什么
Count优化
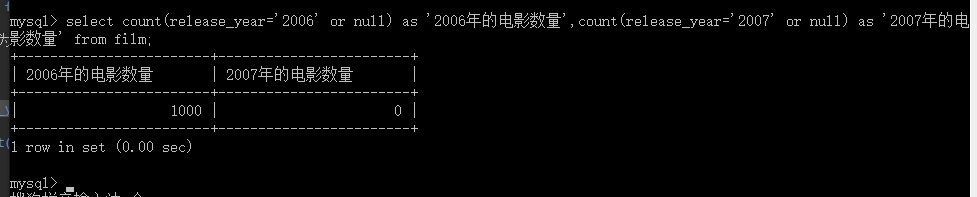
例如:在一条SQL语句中同时查出2006年和2007年的电影数量分别是多少
错误方式:
1
无法分开计算2006年和2007年的电影数量
1
release_year不能同时为2006和2007,因此逻辑上有误
查询优化如下:
1
说明,在sql中,count(*)和count(某列),执行结果有时候会是不一样的,因为,count(*)包含为null的,而另个如果为null的话,则不计数在内。
利用这个特性,将为不是2006年的记为null,执行结果如下图所示