You are here
SSRF原理以及漏洞挖掘方法
转载自:http://www.freebuf.com/articles/web/20407.html
转载自:http://bobao.360.cn/learning/detail/240.html
ssrf攻击概述
很多web应用都提供了从其他的服务器上获取数据的功能。使用用户指定的URL,web应用可以获取图片,下载文件,读取文件内容等。这个功能如果被恶意使用,可以利用存在缺陷的web应用作为代理攻击远程和本地的服务器。这种形式的攻击称为服务端请求伪造攻击(Server-side Request Forgery)。
比如下图显示的就是提供这种功能的典型应用:

如果应用程序对用户提供的URL和远端服务器返回的信息没有进行合适的验证和过滤,就可能存在这种服务端请求伪造的缺陷。Google,Facebook,Adobe,baidu,tencent等知名公司都被发现过这种漏洞。攻击者利用ssrf可以实现的攻击主要有5种:
1.可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息;
2.攻击运行在内网或本地的应用程序(比如溢出);
3.对内网web应用进行指纹识别,通过访问默认文件实现;
4.攻击内外网的web应用,主要是使用get参数就可以实现的攻击(比如struts2,sqli等);
5.利用file协议读取本地文件等。
常用的后端实现
ssrf攻击可能存在任何语言编写的应用,我们通过一些php实现的代码来作为样例分析。代码的大部分来自于真实的应用源码。
1,php file_get_contents:
这段代码使用file_get_contents函数从用户指定的url获取图片。然后把它用一个随即文件名保存在硬盘上,并展示给用户。
2,php fsockopen():
这段代码使用fsockopen函数实现获取用户制定url的数据(文件或者html)。这个函数会使用socket跟服务器建立tcp连接,传输原始数据。
3,php curl_exec():
这是另外一个很常见的实现。使用curl获取数据。
攻击场景
大部分的web服务器架构中,web服务器自身都可以访问互联网和服务器所在的内网。下图展示了web服务器的请求可以到达的地方。

端口扫描
大多数社交网站都提供了通过用户指定的url上传图片的功能。如果用户输入的url是无效的。大部分的web应用都会返回错误信息。攻击者可以输入一些不常见的但是有效的URI,比如
然后根据服务器的返回信息来判断端口是否开放。大部分应用并不会去判断端口,只要是有效的URL,就发出了请求。而大部分的TCP服务,在建立socket连接的时候就会发送banner信息,banner信息是ascii编码的,能够作为原始的html数据展示。当然,服务端在处理返回信息的时候一般不会直接展示,但是不同的错误码,返回信息的长度以及返回时间都可以作为依据来判断远程服务器的端口状态。
下面一个实现就可以用来做端口扫描:
读者可以使用如下表单提交测试(比较简陋~~):
正常情况下,请求http://www.twitter.com/robots.txt 返回结果如下:

如果请求非http服务的端口,比如:http://scanme.nmap.org:22/test.txt 会返回banner信息

请求关闭的端口会报错:http://scanme.nmap.org:25/test.txt

请求本地的mysql端口:http://127.0.0.1:3306/test.txt

当然大多数互联网的应用并不会直接返回banner信息。不过可以通过前面说过的,处错误信息,响应时间,响应包大小来判断。下面是Google的webmaster应用中,利用返回信息判断端口状态的案例.该缺陷Google已修复。



攻击应用程序
内网的安全通常都很薄弱,溢出,弱口令等一般都是存在的。通过ssrf攻击,可以实现对内网的访问,从而可以攻击内网或者本地机器,获得shell等。
下面是用一个小程序本地来演示:
请求:http://127.0.0.1:8987/test.txt

探测到8987端口开放。
请求:


这里是白盒分析,实战的时候当然没这个条件只能是利用已知漏洞来溢出。通过分析写好exp。因为http是基于文本的协议,所以处理一些不可以打印的unicode字符会存在问题。这里使用msfencode来进行编码。命令如下:
最终payload如下:
溢出成功,弹出计算器。

大家也许会对http发送的数据是否能被其他服务器协议接收存在疑问。可以参考跨协议通信技术利用
内网web应用指纹识别
识别内网应用使用的框架,平台,模块以及cms可以为后续的攻击提供很多帮助。大多数web应用框架都有一些独特的文件和目录。通过这些文件可以识别出应用的类型,甚至详细的版本。根据这些信息就可以针对性的搜集漏洞进行攻击。比如可以通过访问下列文件来判断phpMyAdmin是否安装:
访问 http://10.0.0.1/portName.js 可以判断是否是Dlink 路由器

下面百度的案例来自于wooyun,已经修复。通过访问http://10.50.33.43:8080/manager/images/tomcat.gif 识别出服务器使用了tomcat。
{kind=link}


攻击内网web应用
仅仅通过get方法可以攻击的web有很多,比如struts2命令执行等。这里提供一个Jboss的案例,使用一个get请求即可部署webshell。

只需要将网马放在公网服务器上,然后发送这个请求即可:
通过加参数请求网马执行命令:http://127.0.0.1:8080/cmd/shell.jsp?x=dir

实战中一般不会有回显,类似于盲打只能。
读取本地文件
上面提到的案例都是基于http请求的。如果我们指定file协议,也可能读到服务器上的文件。如下的请求会让应用读取本地文件:

下面是Adobe的一个案例,已经修复。请求为file:///etc/passwd
SSRF 漏洞的寻找
一、从WEB功能上寻找
我们从上面的概述可以看出,SSRF是由于服务端获取其他服务器的相关信息的功能中形成的,因此我们大可以列举几种在web 应用中常见的从服务端获取其他服务器信息的的功能。
1)分享:通过URL地址分享网页内容
早期分享应用中,为了更好的提供用户体验,WEB应用在分享功能中,通常会获取目标URL地址网页内容中的<tilte></title>标签或者<meta name="description" content=“”/>标签中content的文本内容作为显示以提供更好的用户体验。例如人人网分享功能中:
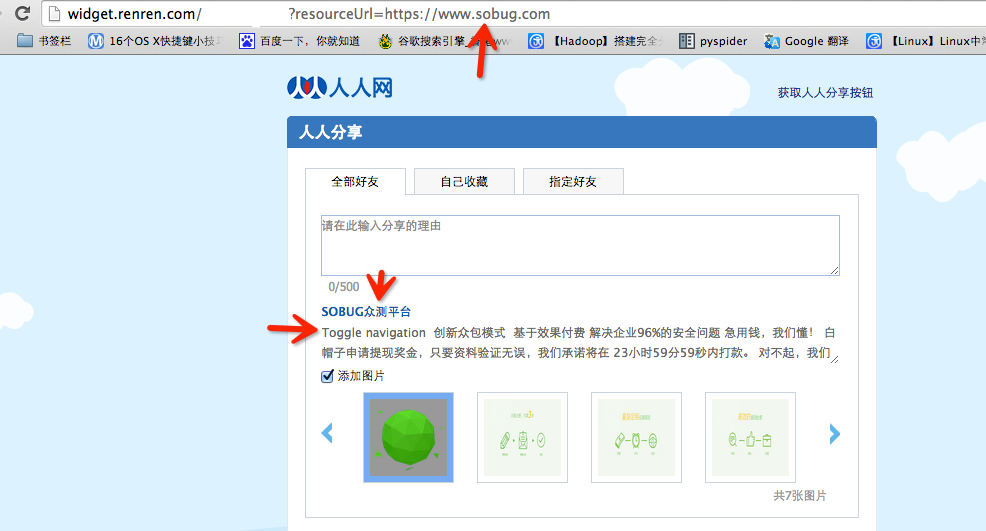
1 | http://widget.renren.com/*****?resourceUrl=https://www.sobug.com |
通过目标URL地址获取了title标签和相关文本内容。而如果在此功能中没有对目标地址的范围做过滤与限制则就存在着SSRF漏洞。
根寻这个功能,我们可以发现许多互联网公司都有着这样的功能,下面是我从百度分享集成的截图如下:
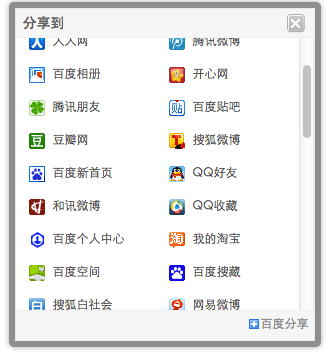
从国内某漏洞提交平台上提交的SSRF漏洞,可以发现包括淘宝、百度、新浪等国内知名公司都曾被发现过分享功能上存在SSRF的漏洞问题。
2)转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
由于手机屏幕大小的关系,直接浏览网页内容的时候会造成许多不便,因此有些公司提供了转码功能,把网页内容通过相关手段转为适合手机屏幕浏览的样式。例如百度、腾讯、搜狗等公司都有提供在线转码服务。
3)在线翻译:通过URL地址翻译对应文本的内容。提供此功能的国内公司有百度、有道等
4)图片加载与下载:通过URL地址加载或下载图片
图片加载远程图片地址此功能用到的地方很多,但大多都是比较隐秘,比如在有些公司中的加载自家图片服务器上的图片用于展示。(此处可能会有人有疑问,为什么加载图片服务器上的图片也会有问题,直接使用img标签不就好了? ,没错是这样,但是开发者为了有更好的用户体验通常对图片做些微小调整例如加水印、压缩等,所以就可能造成SSRF问题)。
5)图片、文章收藏功能
此处的图片、文章收藏中的文章收藏就类似于功能一、分享功能中获取URL地址中title以及文本的内容作为显示,目的还是为了更好的用户体验,而图片收藏就类似于功能四、图片加载。
6)未公开的api实现以及其他调用URL的功能
此处类似的功能有360提供的网站评分,以及有些网站通过api获取远程地址xml文件来加载内容。
在这些功能中除了翻译和转码服务为公共服务,其他功能均有可能在企业应用开发过程中遇到。
二、从URL关键字中寻找
在对功能上存在SSRF漏洞中URL地址特征的观察,通过我一段时间的收集,大致有以下关键字:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | sharewapurllinksrcsourcetargetu3gdisplaysourceURlimageURLdomain... |
如果利用google 语法加上这些关键字去寻找SSRF漏洞,耐心的验证,现在还是可以找到存在的SSRF漏洞。
SSRF 漏洞的验证
1)基本判断(排除法)
例如:
1 | http://www.douban.com/***/service?image=http://www.baidu.com/img/bd_logo1.png |
排除法一:
你可以直接右键图片,在新窗口打开图片,如果是浏览器上URL地址栏是http://www.baidu.com/img/bd_logo1.png,说明不存在SSRF漏洞。
{kind=link}
排除法二:
你可以使用burpsuite等抓包工具来判断是否不是SSRF,首先SSRF是由服务端发起的请求,因此在加载图片的时候,是由服务端发起的,所以在我们本地浏览器的请求中就不应该存在图片的请求,在此例子中,如果刷新当前页面,有如下请求,则可判断不是SSRF。(前提设置burpsuite截断图片的请求,默认是放行的)
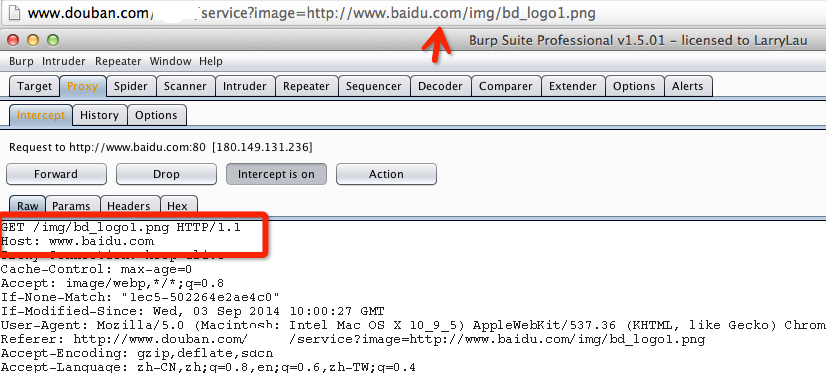
此处说明下,为什么这边用排除法来判断是否存在SSRF,举个例子:

1 | http://read.*******.com/image?imageUrl=http://www.baidu.com/img/bd_logo1.png |
现在大多数修复SSRF的方法基本都是区分内外网来做限制(暂不考虑利用此问题来发起请求,攻击其他网站,从而隐藏攻击者IP,防止此问题就要做请求的地址的白名单了),如果我们请求 :
1 | http://read.******.com/image?imageUrl=http://10.10.10.1/favicon.ico |
而没有内容显示,我们是判断这个点不存在SSRF漏洞,还是http://10.10.10.1/favicon.ico这个地址被过滤了,还是http://10.10.10.1/favicon.ico这个地址的图片文件不存在,如果我们事先不知道http://10.10.10.1/favicon.ico这个地址的文件是否存在的时候是判断不出来是哪个原因的,所以我们采用排除法。
2)实例验证
经过简单的排除验证之后,我们就要验证看看此URL是否可以来请求对应的内网地址。在此例子中,首先我们要获取内网存在HTTP服务且存在favicon.ico文件的地址,才能验证是否是SSRF漏洞。
找存在HTTP服务的内网地址:
一、从漏洞平台中的历史漏洞寻找泄漏的存在web应用内网地址
二、通过二级域名暴力猜解工具模糊猜测内网地址

1 | example:ping xx.xx.com.cn |
可以推测10.215.x.x 此段就有很大的可能: http://10.215.x.x/favicon.ico 存在。
在举一个特殊的例子来说明:
1 |
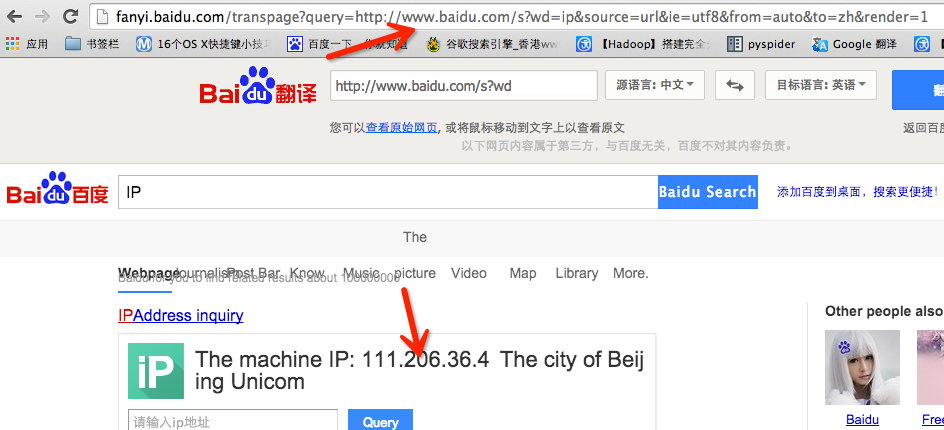
此处得到的IP 不是我所在地址使用的IP,因此可以判断此处是由服务器发起的http://www.baidu.com/s?wd=ip 请求得到的地址,自然是内部逻辑中发起请求的服务器的外网地址(为什么这么说呢,因为发起的请求的不一定是fanyi.baidu.com,而是内部其他服务器),那么此处是不是SSRF,能形成危害吗? 严格来说此处是SSRF,但是百度已经做过了过滤处理,因此形成不了探测内网的危害。
SSRF 漏洞中URL地址过滤的绕过
1)http://www.baidu.com@10.10.10.10与http://10.10.10.10 请求是相同的
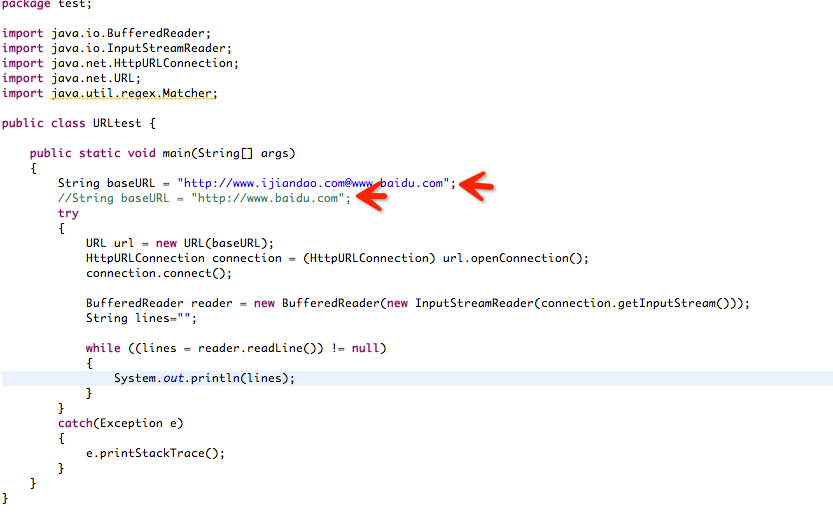
此脚本访问请求得到的内容都是www.baidu.com的内容。
2)ip地址转换成进制来访问
1 | 115.239.210.26 = 16373751032 |
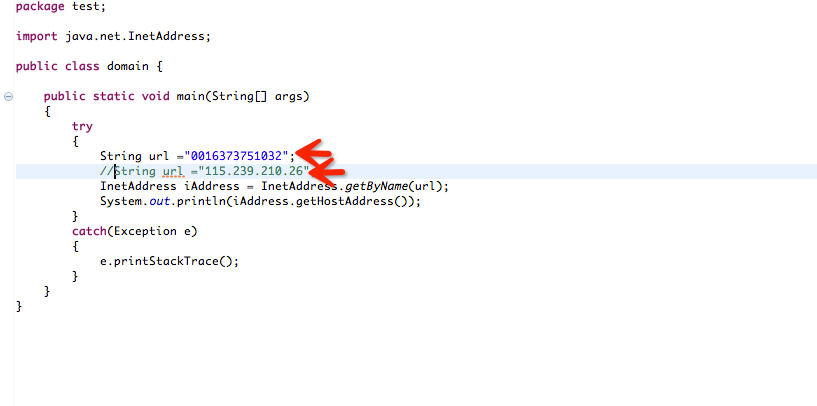
此脚本解析的地址都是 115.239.210.26,也可以使用ping 获取解析地址:
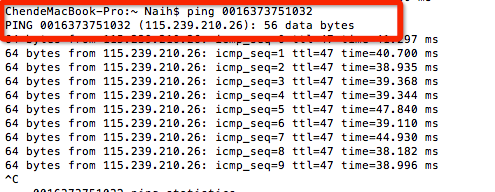
如果WEB服务简单的过滤参数中获取的URL地址,没有判断真正访问的地址,是有可能被此两种方法绕过的。
如何防御
通常有以下5个思路:
1,过滤返回信息,验证远程服务器对请求的响应是比较容易的方法。如果web应用是去获取某一种类型的文件。那么在把返回结果展示给用户之前先验证返回的信息是否符合标准。
2, 统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态。
3,限制请求的端口为http常用的端口,比如,80,443,8080,8090。
4,黑名单内网ip。避免应用被用来获取获取内网数据,攻击内网。
5,禁用不需要的协议。仅仅允许http和https请求。可以防止类似于file:///,gopher://,ftp:// 等引起的问题。
来自 https://blog.csdn.net/u010726042/article/details/77806775