unserialize(): Error at offset出现的原因分析以及解决方法
在PHP的unserialize函数使用中,当字符串或数据库中取出的数据有中文的时候,会出现如下错误
Notice: unserialize(): Error at offset xx of xxx bytes in C:\toolmao\php\index.php on line 21
说到中文,我们肯定第一时间想到编码,那么让我们看看不同文件编码下 serialize 函数对中文的处理是怎么样的,用同一段代码,文件用不同编码来测试
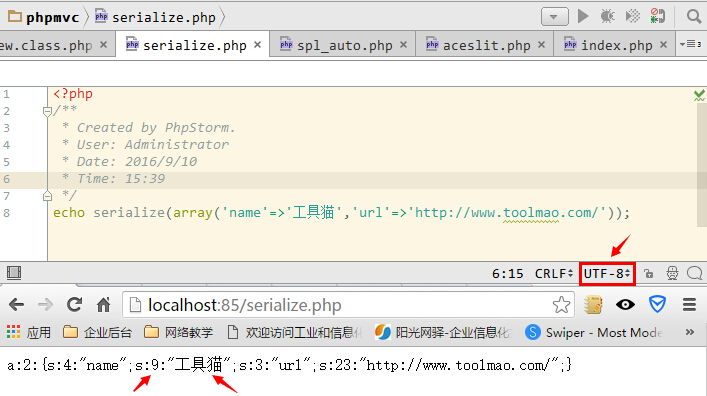
首先看看UTF8的效果,我们发现 中文 “工具猫”的长度是 9
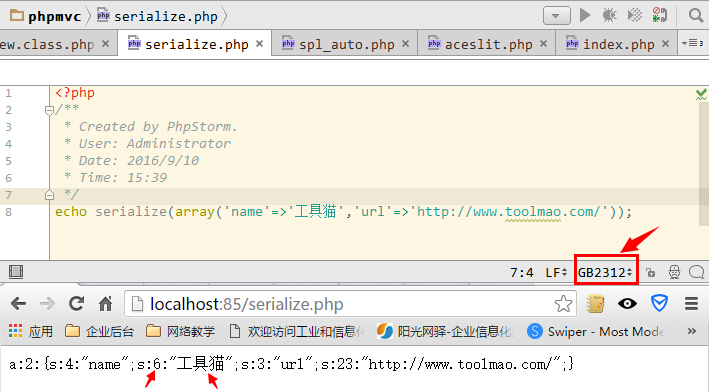
而文件编码是GB2312的时候,中文“工具猫”的长度是 6
所以当我们取出数据库编码为GBK等中文编码,后又用转码函数转成UTF8后,再用unserialize函数时,因为中文在不同编码下的长度不同,就会出现这个问题了。有人可能会说,数据库取出的时候 SET NAMES 不就行了,但有些数据库(比如access和sqlite)是不支持这样操作的。所以编码不符的时候,必须取出数据转码了。那么具体要如何操作呢?接下来就讲解决方案:
上面我们已经知道了unserialize出现Error at offset报错的成因,那么解决起来就简单了,用正则函数把错误的长度替换掉就可以了,网上已经有大神给出了现成的代码:
但是由于php的原因,/e 模式存在漏洞,所以php5.5以后取消了这样的用法,所以使用php5.5+的小伙伴们不要急,这里提供另一个解决方案