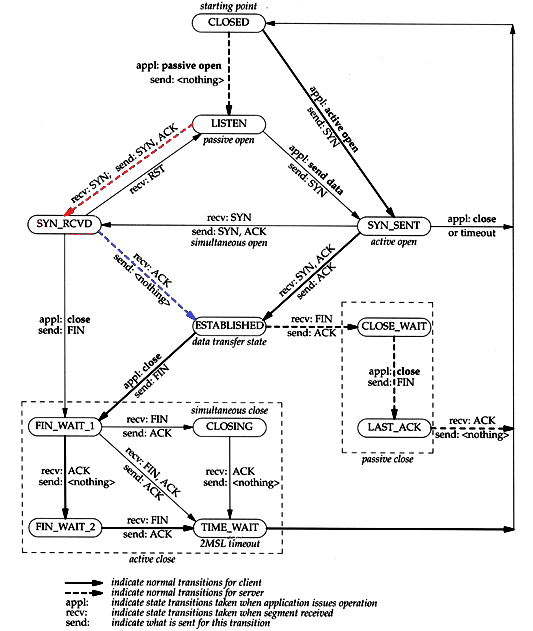
对服务器上出现大量的SYN_RECV状态的TCP连接的问题分析 首先我们需要弄清楚SYN_RCVD状态是怎样产生的,通过TCP状态转换图(如下图)我们可以清楚的看到,SYN_RCVD是TCP三次握手的中间状态,是服务端口(监听端口,如应用服务器的80端口)收到SYN包并发送[SYN,ACK]包后所处的状态。这时如果再收到ACK的包,就完成了三次握手,建立起TCP连接。
如果服务器上出现大量的SYN_RCVD状态的TCP连接说明这些连接一直没有收到ACK包,这主要有两种可能,一种是对方(请求方或客户端)没有收到服务器发送的[SYN,ACK]包,另一种可能是对方收到了[SYN,ACK]包却没有ACK。
对于第一种情况一般是由于网络结构或安全规则限制导致(SYN,ACK)包无法发送到对方,这种情况比较容易判断:只要在服务器上能够ping通互联网的任意主机,基本可以排除这种情况。
对于第二种情况要稍微复杂一些,这种情况还有两种可能:一种是对方根本就不打算ACK,一般在对方程序有意为之才会出现,如SYN Flood类型的 DOS/DDOS攻击;另一种可能是对方收到的[SYN,ACK]包不合法,常见的是SYN包的目的地址(服务地址)和应答[SYN,ACK]包的源地址不同。这种情况在只配置了DNAT而不进行SNAT的服务网络环境下容易出现,主要是由于inbound(SYN包)和outbound([SYN,ACK]包)的包穿越了不同的网关/防火墙/负载均衡器,从而导致[SYN,ACK]路由到互联网的源地址(一般是防火墙的出口地址)与SYN包的目的地址(服务的虚拟IP)不同,这时客户机无法将SYN包和[SYN,ACK]包关联在一起,从而会认为已发出的SYN包还没有被应答,于是继续等待应答包。这样服务器端的连接一直保持在SYN_RCVD状态(半开连接)直到超时。
--------------------- 本文来自 fengxinze 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/fengxinze/article/details/7092270?utm_source=copy
来自 https://blog.csdn.net/fengxinze/article/details/7092270
大量SYN_RECV,80端号占死(优秀) 上转来的文章,效果较为明显
前几天,服务器上进行了一次网络投票
被恶意刷票
采用了动态排序 动态验证码长度 记录IP 等手段 使机器人自动投票作弊失效 只能手工投票
结果 惹恼了参选人雇佣的公司 被他们记恨
对服务器发起了各种攻击
与黑客斗争了好几天 采用了多种手段 效果不太好
下面的文章 值得参考 即使暂时没有被攻击 一些指令也该加入服务器
感谢本文的作者
1
sysctl -w net.ipv4.tcp_syncookies=1 #启用使用syncookies
sysctl -w net.ipv4.tcp_synack_retries=1 #降低syn重试次数
sysctl -w net.ipv4.tcp_syn_retries=1 #降低syn重试次数
sysctl -w net.ipv4.tcp_max_syn_backlog=6000 #最大半连接数
sysctl -w net.ipv4.conf.all.send_redirects=0
sysctl -w net.ipv4.conf.all.accept_redirects=0 #不接受重定向的icmp數據包
sysctl -w net.ipv4.tcp_fin_timeout=30
sysctl -w net.ipv4.tcp_keepalive_time=60
sysctl -w net.ipv4.tcp_window_scaling=1
sysctl -w net.ipv4.icmp_echo_ignore_all=1 #禁止ICMP
sysctl -w net.ipv4.icmp_echo_ignore_broadcasts=1#ICMP禁止广播
2.限制单位时间内连接数
如
iptables -N syn-flood
iptables -A FORWARD -p tcp --syn -j syn-flood
iptables -A INPUT -p tcp --syn -j syn-flood
iptables -A syn-flood -p tcp --syn -m limit --limit 3/s--limit-burst 1 -j ACCEP
iptables -A syn-flood -j DROP
iptables -A INPUT -i eth0 -p tcp ! --syn -m state --state NEW-j DROP
iptables -A INPUT -p tcp --syn -m state --state NEW -jDROP
3 如果还是不行,
iptables -A INPUT -p tcp --dport 80 -m recent --nameBAD_HTTP_ACCESS --update --seconds 60 --hitcount 30 -j REJECT
iptables -A INPUT -p tcp --dport 80 -m recent --nameBAD_HTTP_ACCESS --set -j ACCEP
如攻击过来的流量大于你的服务器的流量,那就没有什么办法了,如果流量不大,以上方法,可以暂时保证你的80可以访问
---------------------------------------------------------------------------------------------
如果你的内核已经支持iptables connlimit可以使用, iptables设定部份,也可以使用
iptables -I FORWARD -p tcp --syn -m connlimit--connlimit-above 5 -j DROP
或
iptables -A INPUT -p tcp --syn --dport 80 -m connlimit--connlimit-above 5 -j REJECT
------------------------------------------------------------------------------------
iptables -A INPUT -p tcp --syn -m limit --limit 1/s -jACCEPT
iptables -A INPUT -p tcp --tcp-flags SYN,ACK,FIN,RST RST -mlimit --limit 1/s -j ACCEPT
iptables -A INPUT -p icmp --icmp-type echo-request -m limit--limit 1/s -j ACCEPT
echo 2048 >/proc/sys/net/ipv4/tcp_max_syn_backlog
echo 1 >/proc/sys/net/ipv4/tcp_synack_retries
echo 1 >/proc/sys/net/ipv4/tcp_syn_retries
echo 1 >/proc/sys/net/ipv4/tcp_syncookies
查询某ip并发连接数
netstat -na|grep SYN|awk '{print $5}'|awk -F: '{print$1}'|sort|uniq -c|sort -r
统计
netstat -na |grep SYN_RECV |grep 80 |wc -l
查看各个状态总数
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a,S[a]}'
---------------------------------------------------------------------------------------------
防止同步包洪水(Sync Flood)
# iptables -A FORWARD -p tcp --syn -m limit --limit 1/s -jACCEPT
也有人写作
#iptables -A INPUT -p tcp --syn -m limit --limit 1/s -jACCEPT
--limit 1/s 限制syn并发数每秒1次,可以根据自己的需要修改
防止各种端口扫描
# iptables -A FORWARD -p tcp --tcp-flags SYN,ACK,FIN,RST RST-m limit --limit 1/s -j ACCEPT
Ping洪水攻击(Ping of Death)
# iptables -A FORWARD -p icmp --icmp-type echo-request -mlimit --limit 1/s -j ACCEPT
vi /etc/sysctl.conf
net.ipv4.tcp_tw_reuse = 1
该文件表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接。
net.ipv4.tcp_tw_recycle = 1
recyse是加速TIME-WAIT sockets回收
对tcp_tw_reuse和tcp_tw_recycle的修改,可能会出现.warning, got duplicatetcp line warning, got BOGUS tcpline.上面这二个参数指的是存在这两个完全一样的TCP连接,这会发生在一个连接被迅速的断开并且重新连接的情况,而且使用的端口和地址相同。但基本上这样的事情不会发生,无论如何,使能上述设置会增加重现机会。这个提示不会有人和危害,而且也不会降低系统性能,目前正在进行工作
net.ipv4.tcp_syncookies = 1
表示开启SYNCookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_keepalive_time = 1200
表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时
net.ipv4.tcp_fin_timeout = 30
fin_wait1状态是在发起端主动要求关闭tcp连接,并且主动发送fin以后,等待接收端回复ack时候的状态。对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_max_syn_backlog = 8192
该文件指定了,在接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.ipv4.tcp_max_tw_buckets = 5000
sysctl -p
--------------------- 本文来自 追寻北极 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/joeyon1985/article/details/46454831?utm_source=copy
来自 https://blog.csdn.net/joeyon1985/article/details/46454831
Nginx调优 | 解决timewait | 解决SYN_RECV | LAST_ACK TCP需要三次握手才能建立,而断开连接则需要四次握手。整个过程如下图所示:
未优化前服务器的状态
[root@ngx32 ~]# netstat -na |awk '{print $6}'| sort |uniq -c |sort -nr
490 ESTABLISHED
44 SYN_RECV
34 LAST_ACK
10 CONNECTED
5 LISTEN
3 CLOSE_WAIT
2
1 established)
1 and
1 I-Node
1 Foreign
1 7894382
1 6343
1 6250
1 6241
1 3937508
1 2837682
1 1863 理论图 放一张图,要搞清楚怎么调整参数,这张图相当重要。看不太明白不要紧,后面会详细讲到这张图
优化经验值
转一个金山张宴的贴子对/etc/sysctrl.conf的优化参数,后面会仔细介绍参数。
# Addnet.ipv4.tcp_max_syn_backlog = 65536
net.core.netdev_max_backlog = 32768
net.core.somaxconn = 32768
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_tw_recycle = 1#net.ipv4.tcp_tw_len = 1net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_max_orphans = 3276800#net.ipv4.tcp_fin_timeout = 30#net.ipv4.tcp_keepalive_time = 120net.ipv4.ip_local_port_range = 1024 65535 TCP三次握手以及其中的各种状态: SYN(Synchronize Sequence Numbers)。
同步序列编号
ACK (ACKnowledge Character)
在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。
=================================client发送syn至server
此时客户端的状态变为SYN_SENT
client(syn=j)====>server
server收到syn,并发送syn+ack到client,
这种过程server状态由listen变为SYN_RECV,并等待客户端再次发来ack数据
client<=========server(syn=k,ack=j+1)client接收到server发过来的syn+ack,并向服务端发送ACK,服务器接收后由SYN_RECV变为ESTABLISHED
client(ACK(ack=k+1))========>server
此种情况下,服务端在三次握手的变迁是
LISTEN->SYN_RECV ->ESTABLISHED
客户端的三次握手的变迁是
SYN_SENT ->ESTABLISHED==================================== 注意问题 一、首先server有个用来接收client发送的syn并对syn进行排队的队列,如果队列满了,新的请求不被接受。
此队列长度控制参数:
net.ipv4.tcp_max_syn_backlog
对应文件(/proc/sys/net/ipv4/tcp_max_syn_backlog ) 默认是1024
1 [root@web]# cat /proc/sys/net/ipv4/tcp_max_syn_backlog2 1024 二、然后是SYN-ACK重传:当server向client发送syn+ack没有收到相应,server将重传,然后再重传。。。控制这个重传次数的参数是
tcp_synack_retries
对应文件(/proc/sys/net/ipv4/tcp_synack_retries )默认值是5,对应于180秒左右时间
1 [root@web ~]# cat /proc/sys/net/ipv4/tcp_synack_retries2 5 关于tcp_synack_retries的英文解释:
备注:与此相对应的client的参数是:
三、关于tcp_syncookies
SYN Cookie原理及其在Linux内核中的实现
http://www.ibm.com/developerworks/cn/linux/l-syncookie/?ca=dwcn-newsletter-linux
SYN Cookie是对TCP服务器端的三次握手协议作一些修改,专门用来防范SYN Flood攻击的一种手段。它的原理是,在TCP服务器收到TCP SYN包并返回TCP SYN+ACK包时,不分配一个专门的数据区,而是根据这个SYN包计算出一个cookie值。在收到TCP ACK包时,TCP服务器在根据那个cookie值检查这个TCP ACK包的合法性。如果合法,再分配专门的数据区进行处理未来的TCP连接。
1 [root@web~]# cat /proc/sys/net/ipv4/tcp_syncookies2 1 典型syn_recv故障处理 如果服务器syn_recv的条数过多,可以采取的操作是:
减少server==>client重传syn+ack的次数。
加大syn队列长度,防止无法响应新的连接
1 echo "net.ipv4.tcp_max_syn_backlog = 4096" >>/etc/sysctl.conf
2 echo "net.ipv4.tcp_synack_retries = 1" >>/etc/sysctl.conf
3 sysctl -p 当受到syn攻击的时候,启用syn-cookie(默认启用,在/etc/sysctl.conf里本身就有参数配置)
1 echo 1 >/proc/sys/net/ipv4/tcp_syncookies TCP四次握手 下面说tcp/ip的第四次握手,分析主动关闭和被动关闭两种。
A:因为如果是CLIENT端主动断掉当前连接,那么双方关闭这个TCP连接共需要四个packet:
setup
Client ---> FIN(M) ---> Server
client发送一个FIN给server,(说它不跟你玩了),client由ESTABLISHED->FIN_WAIT1
Client <--- ACK(M+1) <--- Server
SER VER收到fin后发送ack确认(拿出两人信物),状态由ESTABLISHED->close_wait
client收到server的ack确认,只是改变状态ESTABLISHED->FIN_WAIT1->FIN_WAIT2,继续等server发送数据。
Client <-- FIN(N) <-- Server
server继续发送FIN到client(好就不玩了吧),状态ESTABLISHED->close_wait->LAST_ACK,等待client发送ack做最后的确认
Client --> ACK(N+1) --> Server
client收到FIN,马上发送ack确认,状态ESTABLISHED->FIN_WAIT1->FIN_WAIT2->TIME_WAIT[2MSL超时]->closed
server收到ack确认,状态ESTABLISHED->close_wait->LAST_ACK->CLOSED. keepalive_timeout client关闭连接很好想,有点要搞清楚的是,server端什么时候会发起丢掉连接的操作:
有些是应用程序控制的。nginx.conf为例
keepalive_timeout 0;[root@lvs-2 ~]# curl -I http://www.XXX.comConnection: close keepalive_timeout 600;[root@lvs-2 ~]# curl -I http://www.XXX.comConnection: keep-alive 这种规定了连接时间的,到了时间连接会断掉。
如果没有规定的,则按照系统keepalived定时器的设置进行,具体参数如下:
[root@ngx32 ~]# sysctl -a|grep tcp_keepalivenet.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 30 连接两端一直没发送数据,间隔半分钟,后开始第一次探测,间隔75秒后第二次探测,探测9次,最后放弃连接。
http://www.360doc.com/content/09/1231/16/96202_12383765.shtml
四种状况其实最后一种没什么意义,能考虑到下面三种就行了
1 client正常,每进行一次通讯,net.ipv4.tcp_keepalive_time重置一次。
2 一直到7200+75*9后也无法获取client反馈信息,则认为client已经关闭并终止连接(连接超时)
3 client重启, 收到探测后返回一个复位(RST)信息。server收到后终止连接(连接被对方复位)
典型timewait故障处理 一、网站服务器访问速度变慢,查看网站服务器连接,看到连接至数据库的连接中出现大量time_wait,多达400个。分析是网站服务器定时任务做大量读取数据库操作的时候产生的。
根据上面讲的,time_wait对应2MSL超时,什么是2MSL?,是在client在四次握手的时候最后发送了ack确认给服务器后必然经过 的一个时间。TIME_WAIT状态的目的是为了防止最后client发出的ack丢失,让server处于LAST_ACK超时重发FIN。配置 2MSL时间长短的服务器参数,但这里不是优化的重要参数,我们需要的是Time_wait的连接可以重用,并且能迅速关闭。
2MSl的解释:
MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为tcp报文(segment)是ip数据报(datagram)的数据部分,具体称谓请参见《数据在网络各层中的称呼》一文,而ip头中有一个TTL域,TTL是time to live的缩写,中文可以译为“生存时间”,这个生存时间是由源主机设置初始值但不是存的具体时间,而是存储了一个ip数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减1,当此值为0则数据报将被丢弃,同时发送ICMP报文通知源主机。RFC 793中规定MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟等。
5
6 2MSL即两倍的MSL,TCP的TIME_WAIT状态也称为2MSL等待状态,当TCP的一端发起主动关闭,在发出最后一个ACK包后,即第3次握手完成后发送了第四次握手的ACK包后就进入了TIME_WAIT状态,必须在此状态上停留两倍的MSL时间,等待2MSL时间主要目的是怕最后一个ACK包对方没收到,那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的FIN包后可以再发一个ACK应答包。在TIME_WAIT状态时两端的端口不能使用,要等到2MSL时间结束才可继续使用。当连接处于2MSL等待阶段时任何迟到的报文段都将被丢弃。不过在实际应用中可以通过设置SO_REUSEADDR选项达到不必等待2MSL时间结束再使用此端口。
7
8 TTL与MSL是有关系的但不是简单的相等的关系,MSL要大于等于TTL。
1 [root@bjweba ~]# sysctl -a | grep time | grep wait2 net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait = 120
3 net.ipv4.netfilter.ip_conntrack_tcp_timeout_close_wait = 60
4 net.ipv4.netfilter.ip_conntrack_tcp_timeout_fin_wait = 120 关于 ip_ct_tcp_timeout_time_wait
1 3.7.15. ip_ct_tcp_timeout_time_wait
2
3 The ip_ct_tcp_timeout_time_wait variable defines the timeout value of the TIME-WAIT state as defined by RFC 793. This is the final state possible in a TCP connection. When a connection is closed in both directions, the server and client enters the TIME-WAIT state, which is used so that all stale packets have time to enter the client or server. One example of the usage of this may be if packets are reordered during transit between the hosts and winds up in a different order at either side. In such a case, the timewindow defined in the ip_ct_tcp_timeout_time_wait variable is used so that those packets may reach their destinations anyways. When the timeout expires, the conntrack entry is destroyed and we enter the state CLOSED, which means that there is no conntrack data at all for the connection in question.
4
5 The default value of the ip_ct_tcp_timeout_time_wait variable is set to 120 seconds, or 2 minutes. You should generally want to keep this value if you know that you live on a connection that is slow and that often reorders the packets in question. If this value is too low you will often experience corrupt downloads or missing data in downloaded data, you should definitely avoid tuning this value down in such a case, and you may most definitely consider raising the timeout of this value in such case. If you never experience such behaviour or any other problems like that, you may most probably lower this value so that conntrack entries die faster, and hence recycle the conntrack entry space faster.
6 3.7.15.3.7.15. ip_ct_tcp_timeout_time_wait 如何解决?
控制重用和迅速回收的参数是net.ipv4.tcp_tw_reuse和net.ipv4.tcp_tw_recycle。
这两个参数的具体英文解释和作用等我查到了再补充,网上讲的也不怎么清楚。
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0。
1 echo "net.ipv4.tcp_tw_reuse = 1" >>/etc/sysctl.conf
2 echo "net.ipv4.tcp_tw_recycle = 1" >>/etc/sysctl.conf
3 sysctl -p 出现FIN_WAIT_2状态 现象描述
服务器端运行服务9090的c,或java程序用killall -9 服务名 kill掉后,出现
FIN_WAIT_2状态,新的服务无法启动。因为这个状态占据了服务端口。时间默认1分钟。
1 [root@web ~]# sysctl -a | grep time | grep fin2 net.ipv4.tcp_fin_timeout = 60 关于FIN_WAIT_2的解释http://httpd.apache.org/docs/1.3/misc/fin_wait_2.html
主要就是服务端主动发起关闭,此时服务端相当于一个client,在最后等对方发送最后一个FIN的却一直等不到,直至超时,控制这个超时的时间参数是tcp_fin_timeout
How many seconds to wait for a final FIN packet before the socket is forcibly closed. This is strictly a violation of the TCP specification, but required to prevent denial-of-service (DoS) attacks. The default value in 2.4 kernels is 60, down from 180 in 2.2.
备注:TCP_LINGER2(tcp socket编程选项)The lifetime of orphaned FIN_WAIT2 state sockets. This option can be used to override the system wide sysctl tcp_fin_timeout on this socket. This is not to be confused with the socket (7) level option SO_LINGER. This option should not be used in code intended to be portable.
1 echo "net.ipv4.tcp_fin_timeout = 30" >>/etc/sysctl.conf
2 sysctl -p
3 #echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout 此外,还有控制tcp发送缓冲区,接收缓冲区大小的设置,能够使用端口范围的设置。
1 [root@web~]# cat /proc/sys/net/ipv4/ip_local_port_range2 32768 61000 这个是本地连接外地端口时开的动态端口,个人觉得默认就够了。如果有很频繁的要连接外面端口,可以设大。
1 #echo "5000 65535" > /proc/sys/net/ipv4/ip_local_port_range2 echo "net.ipv4.ip_local_port_range = 5000 65000" >> /etc/sysctl.conf
3 sysctl -p 总结经验值 net.ipv4.tcp_keepalive_time = 300
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.ip_local_port_range = 5000 65000
netstat -n | awk ' /^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]} ' 这条语句返回结果如下
TIME_WAIT 346
FIN_WAIT1 85
FIN_WAIT2 6
ESTABLISHED 1620
SYN_RECV 169
LAST_ACK 8 SYN_RECV表示正在等待处理的请求数; ESTABLISHED 表示正常数据传输状态; TIME_WAIT 表示处理完毕,等待超时结束的请求数。
状态:描述
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
另外很多人会用到TCP SYN Flood 透过网路底层对服务器 Server 进行攻击的,我可以用 Iptables防范下:
防止同步包洪水(Sync Flood )
iptables -A FORWARD -p tcp --syn -m limit --limit 1 /s -j ACCEPT 也有人写作:
iptables -A INPUT -p tcp --syn -m limit --limit 1 /s -j ACCEPT --limit 1/s 限制 syn 并发数每秒 1 次,可以根据自己的需要修改 防止各种端口扫描
iptables -A FORWARD -p tcp --tcp-flags SYN,ACK,FIN,RST RST -m limit --limit 1 /s -j ACCEPT Ping 洪水攻击( Ping of Death )
iptables -A FORWARD -p icmp --icmp-type echo-request -m limit --limit 1 /s -j ACCEPT
# add by geminis for syn crack
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog =2048
net.ipv4.tcp_synack_retries =1
sysctl -p http://www.sphinxsearch.org/archives/10
Linux防止syn flood攻击,屏蔽 SYN_RECV 的连接 2009年02月9日 — admin
今web服务器一直都有syn flood攻击。查阅了Google后方得到一些有效资料
#####################################
抵御SYN SYN攻击是利用TCP/IP协议3次握手的原理,发送大量的建立连接的网络包,但不实际建立连接,最终导致被攻击服务器的网络队列被占满,无法被正常用户访问。
Linux内核提供了若干SYN相关的配置,用命令: sysctl -a | grep syn 看到:
net.ipv4.tcp_max_syn_backlog = 1024 net.ipv4.tcp_syncookies = 0
增加SYN队列长度到2048:
sysctl -w net.ipv4.tcp_max_syn_backlog=2048
打开SYN COOKIE功能:
sysctl -w net.ipv4.tcp_syncookies=1
降低重试次数:
防止同步包洪水(Sync Flood)
Ping洪水攻击(Ping of Death)
禁止某IP访问
iptables -I INPUT -s xxx.xxx.xxx.xx -j DROP
保存配置
查看 iptables配置
/etc/init.d/iptables status
重启iptables
/etc/init.d/iptables restart
http://rhomobi.com/topics/47
linux中netstatus查看SYN_RECV 作者:用户 来源:互联网 时间:2016-12-28 14:10:54
net 服务器 tcp 数据 应用 端口
摘要: 本文讲的是linux中netstatus查看SYN_RECV, 可以通过下面这个命令来统计当前连接数 netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' 这条语句返回结果如下 1.TIME_WAIT
1.TIME_WAIT 346
状态:描述
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
另外很多人会用到TCP SYN Flood透过网路底层对服务器Server进行攻击的,我可以用Iptables防范下:
防止同步包洪水(Sync Flood)
1.iptables -A FORWARD -p tcp --syn -m limit --limit 1/s -j ACCEPT
也有人写作
1.iptables -A INPUT -p tcp --syn -m limit --limit 1/s -j ACCEPT
--limit 1/s 限制syn并发数每秒1次,可以根据自己的需要修改
1.iptables -A FORWARD -p tcp --tcp-flags SYN,ACK,FIN,RST RST -m limit --limit 1/s -j ACCEPT
Ping洪水攻击(Ping of Death)
1.iptables -A FORWARD -p icmp --icmp-type echo-request -m limit --limit 1/s -j ACCEPT
同时,在初始化系统过程中,可以对服务器的数据连接做设置,下面简单的设置下,如果有关于这方面的设置,欢迎大家分享下,先谢过了...
vim /etc/sysctl.conf
net.ipv4.tcp_tw_reuse = 1
该文件表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接。
recyse是加速TIME-WAIT sockets回收
对tcp_tw_reuse和tcp_tw_recycle的修改,可能会出现.warning, got duplicate tcp line warning, got BOGUS tcp line.上面这二个参数指的是存在这两个完全一样的TCP连接,这会发生在一个连接被迅速的断开并且重新连接的情况,而且使用的端口和地址相同。但基本 上这样的事情不会发生,无论如何,使能上述设置会增加重现机会。这个提示不会有人和危害,而且也不会降低系统性能,目前正在进行工作
表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时
fin_wait1状态是在发起端主动要求关闭tcp连接,并且主动发送fin以后,等待接收端回复ack时候的状态。对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。
该文件指定了,在接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
使设置生效
sysctl -p
以上是云栖社区小编为您精心准备的的内容,在云栖社区的博客、问答、公众号、人物、课程等栏目也有的相关内容,欢迎继续使用右上角搜索按钮进行搜索net , 服务器 , tcp , 数据 , 应用 端口 linux syn recv 过多、linux上 syn recv、syn recv、syn recv状态、syn recv 解决办法,以便于您获取更多的相关知识。
linux 服务器 syn*** 大量SYN_RECV状态处理 1、查看连接状态
SYN_RECV表示正在等待处理的请求数; ESTABLISHED 表示正常数据传输状态; TIME_WAIT 表示处理完毕,等待超时结束的请求数。
状态:描述
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
2,解决方法
TCP SYN Flood 透过网路底层对服务器 Server 进行攻击的,我可以用 Iptables防范下:
防止同步包洪水(Sync Flood )
#iptables -A INPUT -p tcp --syn -m limit --limit 1/s -j ACCEPT
--limit 1/s 限制 syn 并发数每秒 1 次,可以根据自己的需要修改 防止各种端口扫描
linux目录 /proc/sys/net/ipv4下有关于内核的设置
tcp_tw_reuse该文件表示是否允许重新应用处于 TIME-WAIT状态的 socket用于新的 TCP连接。
tcp_tw_recycle recyse 是加速 TIME-WAITsockets 回收
对 tcp_tw_reuse 和 tcp_tw_recycle 的修改,可能会出现 .warning, got duplicate tcp linewarning, got BOGUS tcp line. 上面这二个参数指的是存在这两个完全一样的 TCP 连接,这会发生在一个连接被迅速的断开并且重新连接的情况,而且使用的端口和地址相同。
但基本 上这样的事情不会发生,无论如何,使能上述设置会增加重现机会。这个提示不会有人和危害,而且也不会降低系统性能,目前正在进行工作
tcp_syncookies表示开启 SYNCookies。当出现 SYN等待队列溢出时,启用 cookies来处理,可防范少量 SYN攻击,默认为 0,表示关闭;
tcp_synack_retries默认值是 5 对于远端的连接请求 SYN,内核会发送 SYN + ACK数据报,以确认收到上一个 SYN连接请求包。
这是所谓的三次握手 (threeway handshake)机制的第二个步骤。这里决定内核在放弃连接之前所送出的 SYN+ACK 数目。不应该大于 255,默认值是 5 ,对应于 180秒左右时间。
对于 syn攻击可以降低这个次数 ,减少等待时间。
tcp_max_syn_backlog该文件指定了,在接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
对于 syn攻击 可以加大这个数目,拓宽内核队列,可以接受跟多的syn。
来自 http://blog.51cto.com/monkeyzhu/1324286
服务端出现大量的SYN_RECV [问题点数:100分,结帖人bearnedzq] 结帖率 100%
0 2010-03-16 11:02:43 回复次数 33
最近在做性能测试,客户端向服务端发送http请求,短连接。过不了多久,服务端就没有回应了。在服务端上发现链接有很多处于SYN_RECV状态。客户端和服务端都是自己写的,在局域网内做测试,与恶意攻击无关。服务端的基本逻辑是:主进程在一个固定端口侦听,当收到一个请求,就建立一个新进程,由该进程发送回应,然后断开链接,退出子进程。客户端的逻辑是:连上服务端,发送请求,等待回应,收到回应后,关闭链接。一直重复这个过程。客户端是单线程。当客户端做了2万多次这种操作,就发现服务端再也连不上了。查看服务端存在大量的SYN_RECV。请高手给个思路。
问题点数: 100分
服务端问题,客户端做了这么多次连接请求,处理完要关闭socket,释放资源,你的资源没得到释放导致最后资源用尽,无法再连接了。
SYN_RECV是TCP连接三次握手过程还没完的时候。显然到后面同时有多个线程进行连接,没来得及完成握手过程,服务器在等待客户端的响应。
服务端的主进程:
for ( ; ; ) {
clilen = sizeof(cliaddr);
if ( (connfd = accept(listenfd, (SA *) &cliaddr, &clilen)) < 0) {
if (errno == EINTR)
continue; /* back to for() */
else
err_sys("accept error");
}
if ( (childpid = Fork()) == 0) { /* child process */
Close(listenfd); /* close listening socket */
str_echo(connfd); /* process the request */
exit(0);
}
Close(connfd); /* parent closes connected socket */
printf("process count %u\n", ++count);
}
str_echo函数:
//往buf中写数据
read(sockfd, buf, MAXLINE);
Writen(sockfd, rsp, strlen(rsp));
Close(sockfd);
其实这些代码就是 《Unix Network programming》中的。
劲爆!苏州26岁美女用微信做这个,1年存款吓呆父母!!
服务端的主进程:
客户端:windows XP
引用 13 楼 mymtom 的回复: SYN_RECV 状态就是收到了连接请求,但是还没有accept. 我觉得是这种可能
来自 https://bbs.csdn.net/topics/330156644
最近在CentOS Linux下安装配置 ORACLE 数据库的时候,总显示因为网络端口而导致的EM安装失败,遂打算先关闭一下防火墙。root@vcentos ~]# /etc/init.d/iptables statusTable: filterChain INPUT (policy ACCEPT)num target prot opt source destination 1 ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:80 2 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:803 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0 Chain FORWARD (policy ACCEPT)num target prot opt source destination 1 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0https://blog.csdn.net/joeyon1985/article/details/46454685?utm_source=copy
来自 https://blog.csdn.net/joeyon1985/article/details/46454685
linux诡异的半连接(SYN_RECV)队列长度(一) >>转载请注明来源:飘零的代码 piao2010 ’s blog ,谢谢!^_^linux诡异的半连接(SYN_RECV)队列长度(一)
最近在学习TCP方面的基础知识,对于古老的SYN Flood也有了更多认识。SYN Flood利用的是TCP协议缺陷,发送大量伪造的TCP连接请求,从而使得被攻击方资源耗尽(CPU满负荷或内存不足)的攻击方式。
我在两台虚拟机上(虚拟机C攻击虚拟机S)做测试,S上跑了apache监听80端口,用C对S的80端口发送SYN Flood,在无任何防护的情况下攻击效果显著。用netstat可以看见80端口存在大量的半连接状态(SYN_RECV),用tcpdump抓包可以看见大量伪造IP发来的SYN连接,S也不断回复SYN+ACK 给对方,可惜对方并不存在(如果存在则S会收到RST 这样就失去效果了),所以会超时重传。
对于SYN Flood的防御一般会提到修改 net.ipv4.tcp_synack_retries, net.ipv4.tcp_syncookies, net.ipv4.tcp_max_syn_backlog
其中对于net.ipv4.tcp_max_syn_backlog的描述一般都称为半连接队列的长度,但在我实际测试的过程中却发现SYN_RECV状态的数量与net.ipv4.tcp_max_syn_backlog设置的值相差甚远。net.ipv4.tcp_max_syn_backlog = 4096 256
于是就开始相关资料,首先想到的是TCP/IP详解卷1中提到的backlog,man 2 listen:
NOTES
可见backlog在Linux 2.2之后表示的是已完成三次握手但还未被应用程序accept的队列长度。
man 7 tcp:
可见tcp_max_syn_backlog确实是半连接队列的长度,那为何会不准呢?net.core.somaxconn = 128
//file:net/socket.c
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
//上限不超过somaxconn
if ((unsigned)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
查了apache文档关于ListenBackLog 指令的说明,默认值是511. 可见最终全连接队列(backlog)应该是net.core.somaxconn = 128慢连接攻击 测试观察到虚拟机S的80端口ESTABLISHED状态最大数量384min(backlog,somaxconn); linux诡异的半连接(SYN_RECV)队列长度(二) 继续
linux诡异的半连接(SYN_RECV)队列长度(二) >>转载请注明来源:飘零的代码 piao2010 ’s blog ,谢谢!^_^linux诡异的半连接(SYN_RECV)队列长度(二)
继续上回:我们已经确认了全连接队列的长度计算,接下来继续寻找半连接队列长度。《关于半连接队列的释疑》 的文章,激动呐。根据作者提供的思路我开始翻代码,注意我用的内核版本2.6.32,不同版本代码也有差异。
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
struct inet_request_sock *ireq;
struct tcp_options_received tmp_opt;
struct request_sock *req;
__be32 saddr = ip_hdr(skb)->saddr;
__be32 daddr = ip_hdr(skb)->daddr;
__u32 isn = TCP_SKB_CB(skb)->when;
struct dst_entry *dst = NULL;
#ifdef CONFIG_SYN_COOKIES
int want_cookie = 0;
#else
#define want_cookie 0 /* Argh, why doesn't gcc optimize this :( */
#endif
/* Never answer to SYNs send to broadcast or multicast */
if (skb->rtable->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST))
goto drop;
/* TW buckets are converted to open requests without
* limitations, they conserve resources and peer is
* evidently real one.
*/
//关键函数inet_csk_reqsk_queue_is_full
if (inet_csk_reqsk_queue_is_full(sk) && !isn) {
#ifdef CONFIG_SYN_COOKIES
if (sysctl_tcp_syncookies) {
want_cookie = 1;
} else
#endif
goto drop;
}
/* Accept backlog is full. If we have already queued enough
* of warm entries in syn queue, drop request. It is better than
* clogging syn queue with openreqs with exponentially increasing
* timeout.
*/
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1)
goto drop;
req = inet_reqsk_alloc(&tcp_request_sock_ops);
if (!req)
goto drop;
省略N多代码
跟进关键函数inet_csk_reqsk_queue_is_full,在文件includenetinet_connection_sock.h中。
static inline int inet_csk_reqsk_queue_is_full(const struct sock *sk)
{
return reqsk_queue_is_full(&inet_csk(sk)->icsk_accept_queue);
}
跟进关键函数reqsk_queue_is_full,在文件includenetrequest_sock.h中。
static inline int reqsk_queue_is_full(const struct request_sock_queue *queue)
{
//注意这里是用>>(右移)来判断的,不是大于号
return queue->listen_opt->qlen >> queue->listen_opt->max_qlen_log;
}
查找qlen和max_qlen_log的定义,在文件includenetrequest_sock.h中。
/** struct listen_sock - listen state
*
* @max_qlen_log - log_2 of maximal queued SYNs/REQUESTs
*/
struct listen_sock {
u8 max_qlen_log;// 2^max_qlen_log = 半连接队列最大长度
/* 3 bytes hole, try to use */
int qlen;//全连接队列的当前长度
int qlen_young;
int clock_hand;
u32 hash_rnd;
u32 nr_table_entries;
struct request_sock *syn_table[0];
};
可见关键是如何计算max_qlen_log,前一篇博客 提到了listen的系统调用:
//file:net/socket.c
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
//上限不超过somaxconn
if ((unsigned)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
//这里是关键。
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
sock->ops->listen其实是inet_listen,在文件netipv4af_inet.c中。
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
int err;
lock_sock(sk);
err = -EINVAL;
if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM)
goto out;
old_state = sk->sk_state;
if (!((1 << old_state) & (TCPF_CLOSE | TCPF_LISTEN)))
goto out;
/* Really, if the socket is already in listen state
* we can only allow the backlog to be adjusted.
*/
if (old_state != TCP_LISTEN) {
//关键函数inet_csk_listen_start
err = inet_csk_listen_start(sk, backlog);
if (err)
goto out;
}
sk->sk_max_ack_backlog = backlog;
err = 0;
out:
release_sock(sk);
return err;
}
跟进inet_csk_listen_start,在文件netipv4inet_connection_sock.c中。
int inet_csk_listen_start(struct sock *sk, const int nr_table_entries)
{
struct inet_sock *inet = inet_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
//关键函数reqsk_queue_alloc
int rc = reqsk_queue_alloc(&icsk->icsk_accept_queue, nr_table_entries);
//后面省略
}
跟进reqsk_queue_alloc,在文件netcorerequest_sock.c中。
int reqsk_queue_alloc(struct request_sock_queue *queue,
unsigned int nr_table_entries)
{
size_t lopt_size = sizeof(struct listen_sock);
struct listen_sock *lopt;
//这里开始影响到nr_table_entries的取值,内核版本小于2.6.20的话nr_table_entries是不会修改的
nr_table_entries = min_t(u32, nr_table_entries, sysctl_max_syn_backlog);
nr_table_entries = max_t(u32, nr_table_entries, 8);
nr_table_entries = roundup_pow_of_two(nr_table_entries + 1);
//nr_table_entries到这里已经确定
lopt_size += nr_table_entries * sizeof(struct request_sock *);
if (lopt_size > PAGE_SIZE)
lopt = __vmalloc(lopt_size,
GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO,
PAGE_KERNEL);
else
lopt = kzalloc(lopt_size, GFP_KERNEL);
if (lopt == NULL)
return -ENOMEM;
//这里确定了lopt->max_qlen_log的值
for (lopt->max_qlen_log = 3;
(1 << lopt->max_qlen_log) < nr_table_entries;//内核版本小于2.6.20的话这里是sysctl_max_syn_backlog
lopt->max_qlen_log++);
get_random_bytes(&lopt->hash_rnd, sizeof(lopt->hash_rnd));
rwlock_init(&queue->syn_wait_lock);
queue->rskq_accept_head = NULL;
lopt->nr_table_entries = nr_table_entries;
write_lock_bh(&queue->syn_wait_lock);
queue->listen_opt = lopt;
write_unlock_bh(&queue->syn_wait_lock);
return 0;
}
代码到此为止,然后我们计算一下为何在虚拟机S上的SYN_RECV状态数量会是256
nr_table_entries = listen的第二个参数int backlog ,上限是系统的somaxconn nr_table_entries = 128
nr_table_entries = min_t(u32, nr_table_entries, sysctl_max_syn_backlog); nr_table_entries = 128
nr_table_entries = max_t(u32, nr_table_entries, 8); nr_table_entries = 128
nr_table_entries = roundup_pow_of_two(nr_table_entries + 1); //roundup_pow_of_two - round the given value up to nearest power of tworoundup_pow_of_two(128 + 1) = 256
for (lopt->max_qlen_log = 3; (1 << lopt->max_qlen_log) < nr_table_entries; lopt->max_qlen_log++);max_qlen_log = 8
判断半连接队列是否满 queue->listen_opt->qlen >> queue->listen_opt->max_qlen_log;queue->listen_opt->qlen = 256 时reqsk_queue_is_full返回1 , 进入drop 0~255 , 因此SYN_RECV状态数量会是 256
另外同事的测试结果为何与我的不同?2.6.20 的话max_qlen_log是直接由sysctl_max_syn_backlog 决定的,所以半连接队列的长度就是等于sysctl_max_syn_backlog博客 ),很多代码是他带着我分析的。
来自 https://www.cnblogs.com/zengkefu/p/5606696.html