sed之所以能以行为单位的编辑或修改文本,其原因在于它使用了两个空间:一个是活动的“模式空间(pattern space)”,另一个是起辅助作用的“保持空间(hold space)这2个空间的使用。
模式空间:可以想成工程里面的生产车间,数据之间在它上面进行处理。
保持空间:可以想象成仓库,我们在进行数据处理的时候,作为数据的暂存区域。
正常情况下,如果不显示使用某些高级命令,保持空间不会使用到!
sed在正常情况下,将处理的行读入模式空间,脚本中的“sed command(sed命令)”就一条接着一条进行处理,直到脚本执行完毕。然后该行被输出,模式被清空;接着,再重复执行刚才的动作,文件中的新的一行被读入,直到文件处理完毕。
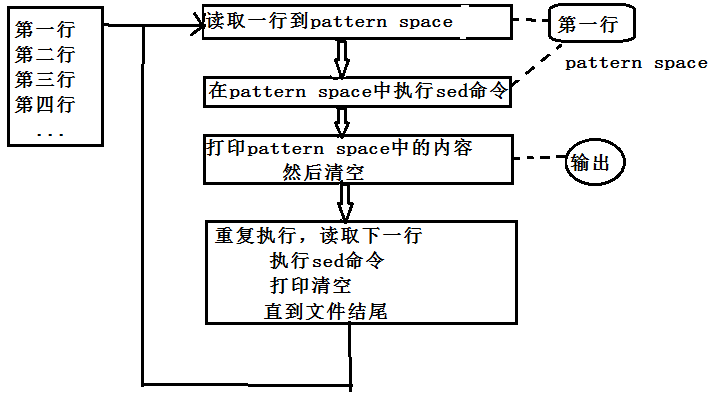
一般情况下,数据的处理只使用模式空间(pattern space),按照如上的逻辑即可完成主要任务。但是某些时候,通过使用保持空间(hold space),还可以带来意想不到的效果。
sed命令:
+ g:[address[,address]]g 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除。
+ G:[address[,address]]G 将hold space中的内容append到pattern space\n后。
+ h:[address[,address]]h 将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除。
+ H:[address[,address]]H 将pattern space中的内容append到hold space\n后。
+ d:[address[,address]]d 删除pattern中的所有行,并读入下一新行到pattern中。
+ D:[address[,address]]D 删除multiline pattern中的第一行,不读入下一行。
+ x:交换保持空间和模式空间的内容。
1. 给每行结尾添加一行空行
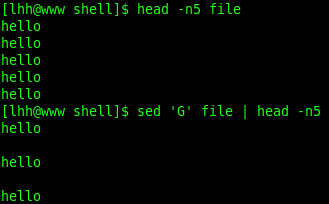
2.用sed模拟出tac的功能(倒序输出)
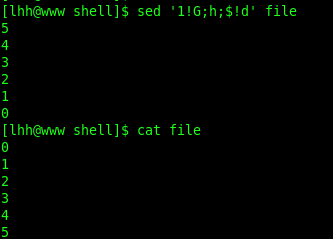
1!G:第1行不执行“G”命令,从第2行开始执行。$!d:最后一行不删除(保留最后1行)。
3.追加匹配行到文件结尾
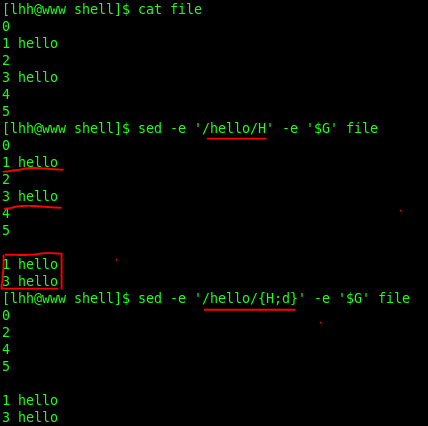
-e :进行多项编辑,即对输入行应用多条sed命令时使用
4.行列转化
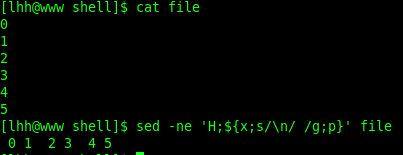
-n :取消默认的输出
H表示把pattern space 的内容追加到hold space中去,H可以带一个地址,这里用的是$,表示到文件的末尾,然后用x将之取到pattern space中,把\n替换成空格再打印即可。
5. 行列转化,求1~100的求和

seq 100 ==>竖排打印1...100个数字。
bc ==>交给bc计算
附:seq命令的语法
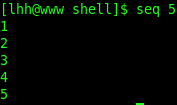
1)生成序列[1…LAST]
例:seq 5 表示序列为 1 2 3 4 5
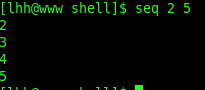
2)生成序列[FIRST…LAST],步长为1
例:seq 2 5表示序列为 2 3 4 5
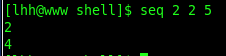
3)生成序列[FIRST…LAST],步长为INCREMENT
例:seq 2 2 5表示序列为 2 4
6. 打印奇偶数行
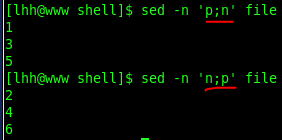
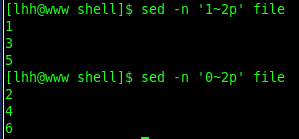
附:awk打印奇偶行
方法一:
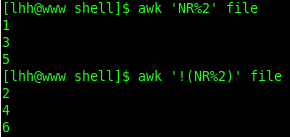
NR是行号,awk的内建函数,当第一行,NR==1时,对2取余,结果是1,在awk的执行模式里,这个1就是pattern,为真,执行默认的{print},这个action操作。那么打印出该行,到第2行则余数是0,pattern为0,则为假,不会执行默认的{print},则不会输出偶数行。就达到了只输出奇数行的效果,反之则输出偶数行了。
方法二:
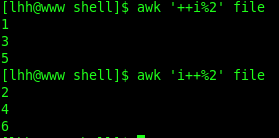
这行命令充分的利用了C语言中 ++i 与 i++ 的区别,i++ 中i的值自加一次后这个表达式的结果等于1,但此时i的值仍然为0,i的值在当前表达式中不会改变,++i中i的值自加一次后,i的值是1。第一行时,因为对2取余的时候
i++ 自加一次后的值是1,但 i++ 是把i的自加前的值去对2取余的,0对2取余结果为0,条件为假,到第二行的时候i的值才是上次自加后的值为1,对2取余数为1,pattern为真,则输出第2行,以此类推。++i 则是自加后i的值是1,所以输出的奇数行。
方法三:
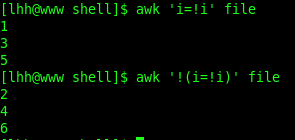
方法四:
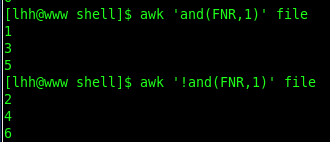
awk里面有三个built-in function,分别是:and(a, b)按位与,or(a, b)按位或,xor(a, b)按位异或,当FNR为1的时候,就是第一行,1的2进制为0001,与0001按位与,得到结果是0001,0001的结果为真,就打印改行,当FNR为2时二进制表示为0010,那么又与0001相与,结果为0000,条件为假,则不打印。只有当FNR为奇数时,二进制的尾数为1,与0001相与结果才为真,否则结果都为假。即只输出奇数行,非则输出偶数行。
7.求1~100和

:a表示标签a,ba表示跳转到a标签,$表示最后一行,!表示不做后续操作,所以,$!ba表示最后一行不用跳转到a标签,结束此次操作。
---------------------
本文来自 wanglelelihuanhuan 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/wanglelelihuanhuan/article/details/51591809?utm_source=copy
来自 https://blog.csdn.net/wanglelelihuanhuan/article/details/51591809
sed高级用法:模式空间(pattern space)和保持空间(hold space)
2014年03月13日 00:54:09 itsenlin 阅读数:12268更多
环境:centos 6.4
sed版本:sed-4.2.1-10.el6.x86_64
前面的基本用法已经可以满足90%的需要,人个认为想要真正掌握sed,还需要学习一下sed的高级用法,本节就详细讲解一下sed的模式空间和保持空间
前面基本用法中也有提到模式空间,即为处理文件中一行内容的一个临时缓冲区。处理完一行之后就会把模式空间中的内容打印到标准输出,然后自动清空缓存。
而这里说的保持空间是sed中的另外一个缓冲区,此缓冲区正如其名,不会自动清空,但也不会主动把此缓冲区中的内容打印到标准输出中。而是需要以下sed命令进行处理:
d Delete pattern space. Start next cycle. 删除pattern space的内容,开始下一个循环.
h、 H Copy/append pattern space to hold space. 复制/追加pattern space的内容到hold space.
g、 G Copy/append hold space to pattern space. 复制/追加hold space的内容到pattern space.
x Exchange the contents of the hold and pattern spaces. 交换hold space和pattern space的内容.
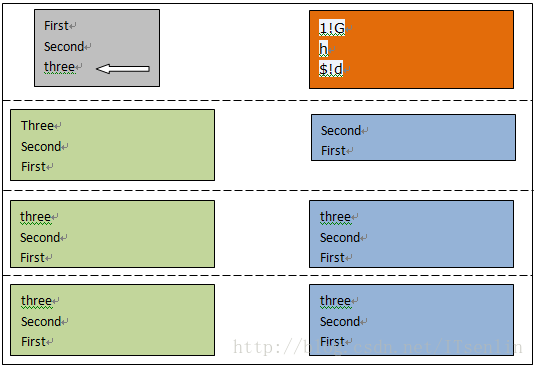
下面以一个例子来说明上面命令的用法,例如有一个文件,我们可以用tac命令反序打印出文件的内容,其实用sed的话也可以实现,这里先将结果列出,再详细讲解
[root@localhost ~]# cat file
[root@localhost ~]# sed '1!G;h;$!d' file

不错就是一行命令就可实现:
sed '1!G;h;$!d' file
通过下面的讲解大家可以了解到sed的处理机制以及处理过程:
说明:
第一行左边为文件内容,箭头所指为sed当前处理的行,右侧为sed命令;
后面三行左侧绿色为模式空间内容,右侧蓝色为保持空间内容。
每次sed只读取文件中一行到模式空间,即每次执行sed命令前,模式空间中只有文件中当前处理行内容,这一点没有在图中表现。
每一行表示一个命令处理完后两个空间中的内容
因为每一步骤都很清楚,所以只把执行的结果以图形表示,不做说明,可以对照前面对sed命令的说明,以加深理解
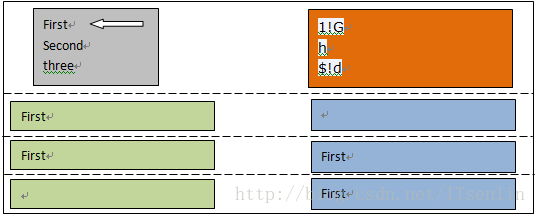
1,读取文件的第一行"First"进行处理,最后一个命令将模式空间内容删除,所以不会在屏幕上打印内容
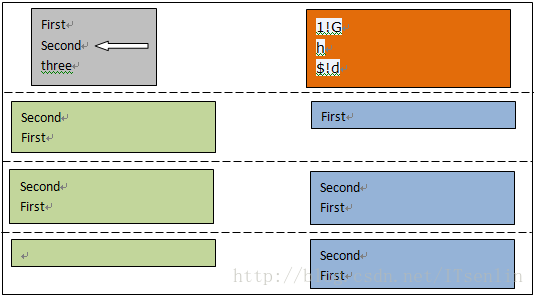
2,读取第二行“Sencond”进行处理,最后一个命令将模式空间内容删除,所以不会在屏幕上打印内容
3,读取第三行“three”进行处理,注意sed处理完之后会把模式空间中内容打印到屏幕并自动清空模式空间(这个没在图中表现)
其实这个功能还可以用下面命令实现:
sed -n '1!G;h;$p' file
说明:
-n: 表示不输出sed的处理结果,而想要输出,则需要要显示的用“p”命令
其实sed的高级命令还有几个,可以分为三组,后续有机会再学习其他两组命令:
处理多行模式空间(N、D、P)。
采用保持空间来保存模式空间的内容并使它可用于后续的命令(H、h、G、g、x)。
编写使用分支和条件指令的脚本来更改控制流(:、b、t)。
来自 https://blog.csdn.net/itsenlin/article/details/21129405
前段时间在学习shell脚本,上次有提到sed的模式空间和保持空间概念,但是一直没有研究好,这两天研究了一下,所以将它发出来,不是很全面,仅仅供大家参考一下。
保持空间sed在正常情况下,将处理的行读入模式空间,脚本中的“sed command(sed命令)”就一条接着一条进行处理,直到脚本执行完毕。然后该行被输出,模式被清空;接着,在重复执行刚才的动作,文件中的新的一行被读入,直到文件处理完毕。
模式空间可以比喻为一个生产线,而保持空间则可以被比喻为仓库,这个比喻希望可以帮助大家理解两者的关系。
sed的指令中用来操作保持空间和模式空间的常见的有一下
为了方便,在下面用P来表示模式空间,M来表示保持空间
h :把模式空间里的内容复制到暂存缓冲区(保持空间)
H :把模式空间里的内容追加到暂存缓冲区(保持空间)
g :把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容
G:把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面
d: 删除pattern中的所有⾏行,并读入下一新行到P中
D:D 删除M ,P中的第一行,不读入下一行
x:交换保持空间和模式空间的内容
下面我就用具体事例来介绍一下用法吧:
1.实现tac功能
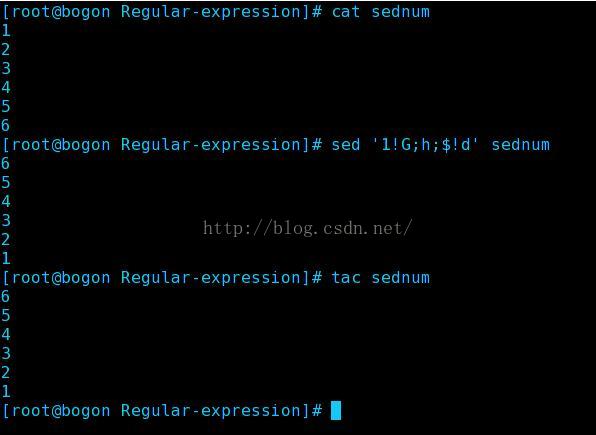
其中 1!G 表示第一行不使用G,$!d 表示最后一行不使用d,其执行工程大概是这样的:
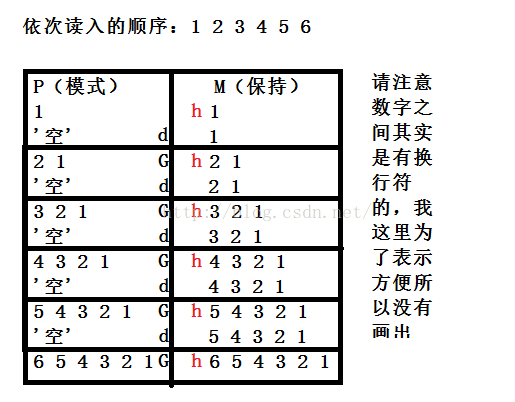
上图就是数据在两个空间的转换过程,不知道大家看懂了没,其中该行标有d的表示d操作(删除模式空间的内容),标有G的表示G操作(将内容追加到模式空间,这个操作不会覆盖原有内容),标有h的表示h操作(将模式空间内容复制到保持空间,这个会覆盖原有内容)。最后的结果和我们看到的结果一致。
2.行列转化
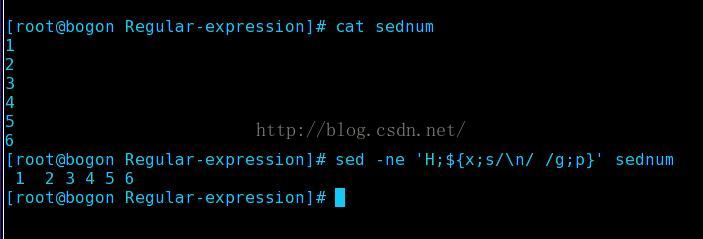
我解释一下上面的语句吧,H表示吧模式空间的内容追加到保持空间,${...} 表示最后执行,意思是最后才执行{ }里面的内容,所以最后的时候保持空间里面的内容和cat的内容一致,x
表示交换保持空间和模式空间的内容,那么此时模式空间里的内容就是cat的内容了,此时再使用 "s/p1/p2/g" 替换命令,将换行符\n,替换成空格,这样列就变成行了,反之道理一样。
3.求1~10的和(1~10比较少,观察起来比较方便,求1~100的和也是很简单的)

seq的功能是列出1~n的数:

首先: H---追加到保持空间
其次: ${x;s/\n/+/g;s/^+//;p} ---- 最后一行执行(因为${} );交换保持空间和模式空间的内容;将\n替换成+;最后使用bc计算器就可以求出1~10的和了。
以上就是我对保持空间和模式空间的一些理解以及对操作两个空间的一些指令的使用,可能使用上面的指令可以实现更多的功能,但是我在这里家就不一一介绍了,这部分确实挺考验脑力的。大家感兴趣的话可以再去多多研究研究,实现更多的功能。
---------------------
本文来自 _从未止步 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/zr1076311296/article/details/51277915?utm_source=copy
来自 https://blog.csdn.net/zr1076311296/article/details/51277915
sed 模式空间与保留空间
 (2017-04-25 11:13:26)
(2017-04-25 11:13:26)sed的工作原理
sed维护着两个数据的缓冲空间,一个是模式空间( pattern space)和另外一个保留空间( hold space),在初始环境下都为空。
sed是一个流编辑器,它会循环的从输入流中读取每一行,直到读完整个文件。具体如下:
首先,它会从输入流中读取一行(如果刚开始就是第一行),移除行尾的换行符,放置于模式空间当中,接着一条条的运行命令(命令可以有多个并且是按序执行,如果某个命令地址定界了一个行号,只有满足该行号才会执行命令, 如“1d”,意思是如果是第一行则删除模式空间内的内容 )。
当命令运行完毕之后,除非使用了 -n 选项,否则会把模式空间的内容加上之前删过的换行符并打印到输出。然后读入下行,执行下一个循环。如果没有使诸如‘D’的特殊命令,那会在两个循环之间清空模式空间,但不会清空 保留 空间。
意译自 http://www.gnu.org/software/sed/manual/sed.html 中 3.1 How sed Works
流程图如下

注:上面只是标准流程,某些特殊命令会有自己的流程
n N的说明
范例文件1
[root@CZ tmp]# cat 1
1
2
3
4
5
6
7
8
9
10
11
n:打印当前模式空间内容,然后读取下一行并替代当前模式空间的内容。 如果读取不到下一行sed则会不运行之后的命令
我们通过以下命令了解一下n
[root@CZ tmp]# sed 'n;d' 1
1
3
5
7
9
11
上面命令过程是这样
先读取第一行进模式空间(以后简称为1)
执行命令n,过程如下
打印1到输出
读取2并覆盖到模式空间
执行命令d,过程如下
删除模式空间的内容
立即执行下一循环(d命令在运行后会直接执行下一循环,所以它并不会执行之后的命令和打印模式空间,具体d介绍会留在下次分享)
按照上面的流程循环执行…….直到读取到11(最后一行),11的具体过程如下
读取11进模式空间
运行命令n,不过读取不到下一行
因为读不到,所以sed退出所有的命令,也就是说它不会执行命令d
加回换行符并打印模式空间的内容到输出,当前模式空间内容为11,所以输出11
已经是文件尾,sed结束运行。
N:读取下一行并且附加到当前模式空间内, 如果读取不到下一行sed则会不运行之后的命令
我们通过以下命令了解一下N
[root@CZ tmp]# sed 'N;a---' 1
1
2
---
3
4
---
5
6
---
7
8
---
9
10
---
11
上面命令过程是这样
读取1进模式空间
执行命令N
读取2并附加到模式空间, 当前模式空间内容 为“1\n2”
执行命令a—
在模式空间后附加一行‘—’当前模式空间内容为“1\n2\n—"
打印模式空间内容
循环执行直到读取11进模式空间,11的具体过程如下
读取11进模式空间
执行命令N,不过读取不到下一行
因为读不到,所以sed退出所有的命令,也就是说它不会执行命令a
加回换行符并 打印模式空间的内容到输出,当前模式空间内容为11,所以输出11
已经是文件尾,sed结束运行。
尾言 :
n N经常和d D一起用,不过D有点复杂,所以留在下次分享,不过我先剧透一下,D会删除模式空间内第一行,并且如果模式空间内容不为空,它会循环执行前面命令。直到为空才会执行下一循环。
来自 http://blog.sina.com.cn/s/blog_e6f9d4300102x1or.html