参考资料
http://www.imkevinyang.com/2009/08/%E4%BD%BF%E7%94%A8%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%89%BE%E5%87%BA%E4%B8%8D%E5%8C%85%E5%90%AB%E7%89%B9%E5%AE%9A%E5%AD%97%E7%AC%A6%E4%B8%B2%E7%9A%84%E6%9D%A1%E7%9B%AE.html
正则基本知识
http://xixian.iteye.com/blog/721147
正则表达式中有前瞻(Lookahead)和后顾(Lookbehind)的概念,这两个术语非常形象的描述了正则引擎的匹配行为。需要注意一点,正则表达式中的前和后和我们一般理解的前后有点不同。一段文本,我们一般习惯把文本开头的方向称作“前面”,文本末尾方向称为“后面”。
但是对于正则表达式引擎来说,因为它是从文本头部向尾部开始解析的(可以通过正则选项控制解析方向),因此对于文本尾部方向,称为“前”,因为这个时候,正则引擎还没走到那块,而对文本头部方向,则称为“后”,因为正则引擎已经走过了那一块地方。
如下图所示:
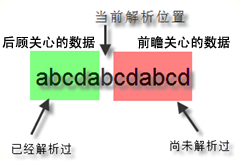
前瞻就是在正则表达式匹配到某个字符的时候,往“尚未解析过的文本”预先看一下,看是不是符合/不符合匹配模式。
后顾,就是在正则引擎已经匹配过的文本看看是不是符合/不符合匹配模式。符合和不符合特定匹配模式我们又称为肯定式匹配和否定式匹配
现在看它们的定义方法吧(零断言,不用管术语名称,翻译太拗口复杂了)
开始写不含特定字符的正则
参考例子说明
上面就把含有特定字符的句子完全抹杀了,实现了完全和谐社会。。。。。
上面例子是特定字符在任意位置出现都会匹配
现在某国突然良心发现皇恩浩荡开放部分言论
只想实现不以特定字符结尾的句子
我们套用上面的例子,稍微改下
现在第三条数据这么不和谐的数据也通过
人民可以说些话了,某国也可以辟谣了
五毛们也有工作量了,也多少增加了GDP的发展吧
-------------------------------
以上数据纯属虚构,如有雷同,纯属巧合
http://www.imkevinyang.com/2009/08/%E4%BD%BF%E7%94%A8%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%89%BE%E5%87%BA%E4%B8%8D%E5%8C%85%E5%90%AB%E7%89%B9%E5%AE%9A%E5%AD%97%E7%AC%A6%E4%B8%B2%E7%9A%84%E6%9D%A1%E7%9B%AE.html
正则基本知识
http://xixian.iteye.com/blog/721147
正则表达式中有前瞻(Lookahead)和后顾(Lookbehind)的概念,这两个术语非常形象的描述了正则引擎的匹配行为。需要注意一点,正则表达式中的前和后和我们一般理解的前后有点不同。一段文本,我们一般习惯把文本开头的方向称作“前面”,文本末尾方向称为“后面”。
但是对于正则表达式引擎来说,因为它是从文本头部向尾部开始解析的(可以通过正则选项控制解析方向),因此对于文本尾部方向,称为“前”,因为这个时候,正则引擎还没走到那块,而对文本头部方向,则称为“后”,因为正则引擎已经走过了那一块地方。
如下图所示:
前瞻就是在正则表达式匹配到某个字符的时候,往“尚未解析过的文本”预先看一下,看是不是符合/不符合匹配模式。
后顾,就是在正则引擎已经匹配过的文本看看是不是符合/不符合匹配模式。符合和不符合特定匹配模式我们又称为肯定式匹配和否定式匹配
现在看它们的定义方法吧(零断言,不用管术语名称,翻译太拗口复杂了)



- //前瞻
- (?=exp)真正有用的部分,在这个位置之前,之前的数据需要匹配exp
- (?<=exp)真正有用的部分,在这个位置之后,之后的数据需要匹配exp
- //后顾
- (?!exp)真正有用的部分,在这个位置之前,之前的数据不匹配exp
- (?<!exp)真正有用的部分,在这个位置之后,之后的数据不匹配exp
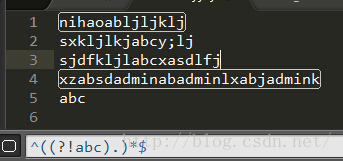
开始写不含特定字符的正则
参考例子说明
- String reg="^(?!.*(不合谐)).*$";//用到了前瞻
- System.out.println("不管信不信,反正现在很不合谐".matches(reg));//false不通过
- System.out.println("不管信不信,反正现在非常合谐".matches(reg));//true通过
- System.out.println("不合谐在某国是普遍存在的".matches(reg));//false不通过
上面就把含有特定字符的句子完全抹杀了,实现了完全和谐社会。。。。。
上面例子是特定字符在任意位置出现都会匹配
现在某国突然良心发现皇恩浩荡开放部分言论
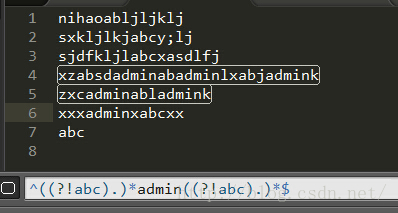
只想实现不以特定字符结尾的句子
我们套用上面的例子,稍微改下
- String reg="^.*(?<!(不合谐))$";//用到了后顾
- System.out.println("不管信不信,反正现在很不合谐".matches(reg));//false不通过
- System.out.println("不管信不信,反正现在非常合谐".matches(reg));//true通过
- System.out.println("不合谐在某国是普遍存在的".matches(reg));//true通过
现在第三条数据这么不和谐的数据也通过
人民可以说些话了,某国也可以辟谣了
五毛们也有工作量了,也多少增加了GDP的发展吧
-------------------------------
以上数据纯属虚构,如有雷同,纯属巧合