IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。
采用了特有的“正向迭代最细粒度切分算法”,具有60万字/秒的高速处理能力。
采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
准备IK-Analyzer中文分词工具包,
这儿加个下载地址:IK-Analyzer 分词器所需要的配置文件、扩展词典及停用词词典 完整包下载
下面是这个资源文件解压截图

在我的网盘里有 在 https://code.google.com/archive/p/ik-analyzer/downloads 里面也有
下载完成后将IK-Analyzer上传到Linux服务器,输入命令 " unzip IKAnalyzer.zip " ,如下图:

输入 " cp ik-analyzer.jar /home/www/solr/solr/WEB-INF/lib/IKAnalyzer.jar -r "
如下图:

将 IKAnalyzer 分词器所需要的配置文件、扩展词典及停用词词典复制到 solr 工程目录下,
输入命令 " cp IKAnalyzer.cfg.xml mydict.dic ext_stopword.dic /home/www/solr/solr/WEB-INF/classes "
如下图:

在Solr的 schema.xml 配置文件中新增配置fieldType节点,
输入命令 " vi /home/www/solr/solr/home/solr/collection1/conf/schema.xml "
新增内容:
作用:加载IK-Analyzer中文分词器工具
<fieldType name="my_first_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
如下图:
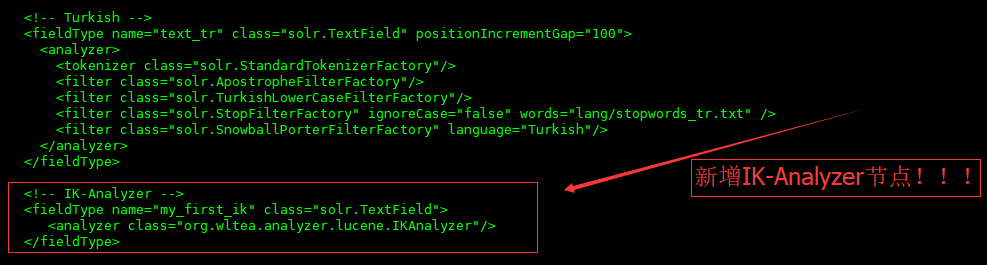
新增业务字段;
加入如下实例内容:
<field name="my_name" type="my_first_ik" indexed="true" stored="true"/>
<field name="my_age" type="my_first_ik" indexed="true" stored="true"/>
<field name="my_hobby" type="my_first_ik" indexed="true" stored="false"/>
<field name="my_copy_alls" type="my_first_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="my_name" dest="my_copy_alls"/>
<copyField source="my_age" dest="my_copy_alls"/>
<copyField source="my_hobby" dest="my_copy_alls"/>
如下图:

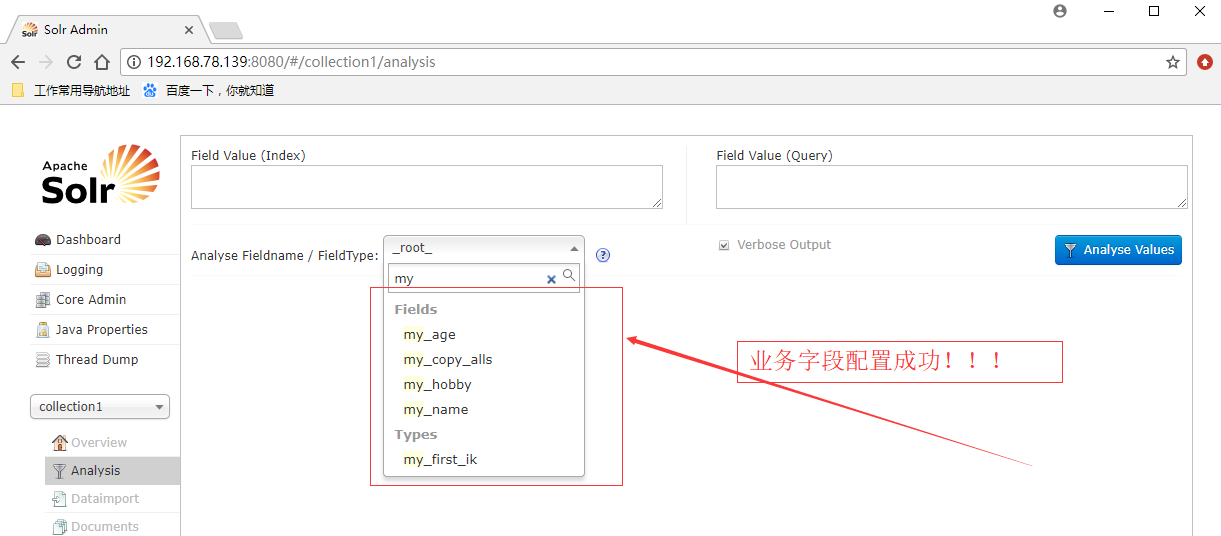
业务字段配置好后,重启Tomcat服务,就可以在solr的控制台中看到自己配置的业务字段名了,如下图:
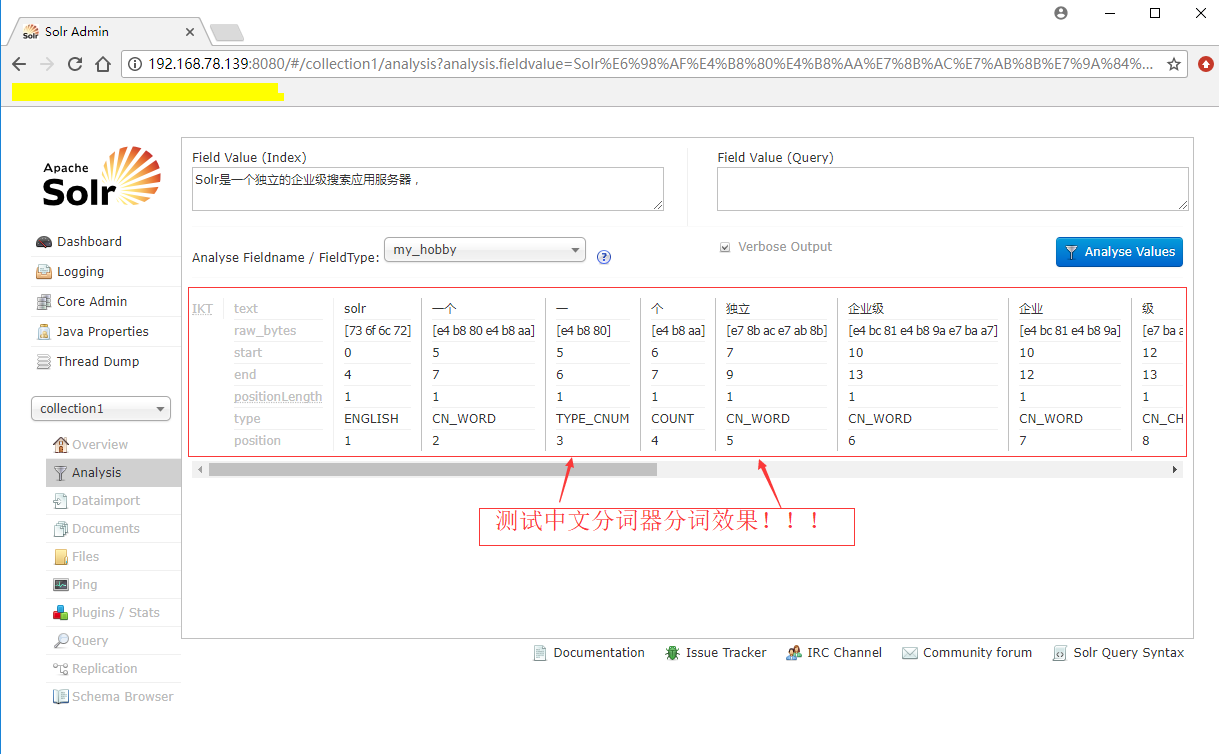
IK-Analyzer中文分词器配置完成后,复制一句话进去进行测试,测试结果如下图,说明我们的IK-Analyzer的中文分词器就配置成功了,如下图:
上一篇关于 《 Linux下Solr4.10.4搜索引擎的安装与部署图文详解 》
来自 https://blog.csdn.net/hello_world_qwp/article/details/78890904