You are here
Solr配置中文分词器
请教solr中文分词的配置问题
| 赞成!0否决! | 大家好,我已经配置好dp7.23+solr4.2.1版本的连接问题,
但是在中文分词的配置上遇到了麻烦。 我在schema.xml上写 <fieldType name="text_ik_test" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>这样是没有问题的吧~如下图,测试是通过的。
但是上面的配置,似乎没搞索引哎! 于是,我改成 <fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/> <tokenizer class="org.wltea.analyzer.lucene.IKAnalyzer"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> </analyzer> <analyzer type="query"> <charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/> <tokenizer class="org.wltea.analyzer.lucene.IKAnalyzer"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>重启后,就报错了。
竟然说插件初始化错误,google了半天,不明所以。特来问问,请问有知道怎么解决的同学吗?麻烦帮我看下怎么解决,谢谢 drupal7solr | ||
 北极狐LV 7
|
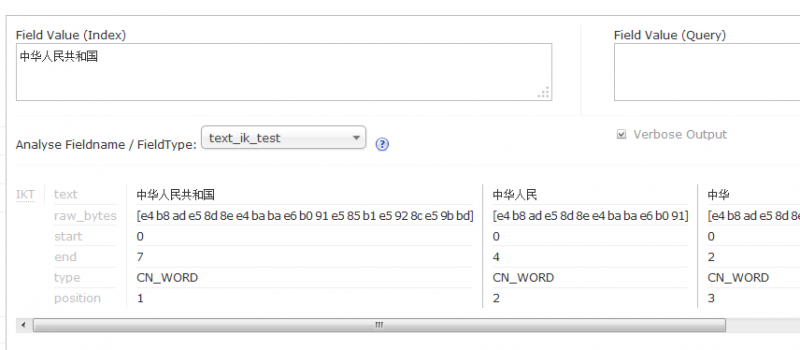
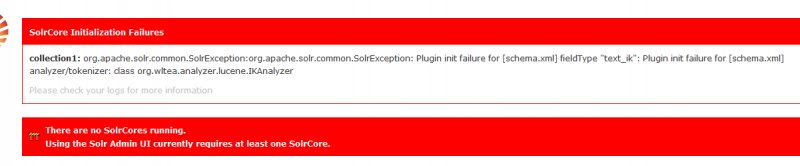
3 个回答
| 赞成!0否决! | 可以创建一个名为text的字段类型,如下: <types> <fieldType name="text" class="solr.TextField" sortMissingLast="true" omitNorms="true"> <analyzer class="org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer"/> </fieldType> <fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/> </types>在fieldType里我们就可以加入要用到的中文分词器,SmartChineseAnalyzer是Lucene自带的一款基于统计规则来分词的中文分词器。 上面是定义了一个string的字段类型,这个类型的字段是不会用到中文分词器的。 然后定义三个字段id、title、text <fields> <field name="id" type="string" indexed="true" stored="true" required="true" /> <field name="title" type="text" indexed="true" stored="true"/> <field name="text" type="text" indexed="true" stored="true" multiValued="true"/> </fields>Id的字段类型为上面定义的string,其余两个字段为上面定义的text,也就是这两个字段将采用中文分词器进行分词。 下面再定义其它的一些内容: <uniqueKey>id</uniqueKey> <defaultSearchField>text</defaultSearchField> <solrQueryParser defaultOperator="AND"/>上面表示索引主键为id,默认的搜索字段为text,搜索为与搜索。 完整的schema.xml内容为: <?xml version="1.0" encoding="UTF-8" ?> <schema name="example" version="1.5"> <types> <fieldType name="text" class="solr.TextField" sortMissingLast="true" omitNorms="true"> <analyzer class="org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer"/> </fieldType> <fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/> </types> <fields> <field name="id" type="string" indexed="true" stored="true" required="true" /> <field name="title" type="text" indexed="true" stored="true" multiValued="true" omitNorms="true"/> <field name="text" type="text" indexed="true" stored="true" multiValued="true"/> </fields> <uniqueKey>id</uniqueKey> <defaultSearchField>text</defaultSearchField> <solrQueryParser defaultOperator="AND"/> </schema>注如果报错:Unknown FieldType: ‘string’ used in QueryElevationComponent,则是因为在配置中必须有一个字段的类型配置为string,如: 1 <field name="id" type="string" indexed="true" stored="true" required="true" /> | ||||||||||
 孤魂LV 10
|
| 赞成!0否决! | http://outofmemory.cn/code-snippet/3659/Solr-configuration-zhongwen-fenc... 怎么和这个一模一样?谢谢你的好意了,不过你也太低估人家的搜索能力了吧。 我是搜索了很久,得不到要领,才上来问的。再一次谢谢! |
 北极狐LV 7
|
来自 http://www.drupalla.com/node/2843