You are here
Solr 应用(五)-中文分词
星期四, 2019-03-21 11:54 — adminshiping1
上一节我们在演示查询的时候只使用一个 title:step 就查出了所有 title 包含 step 的记录,感觉有点类似数据库的 like 功能,主要是分词的匹配的原因,实际上分词匹配功能要远强于 sql 的 like 功能。既然分词这么重要在国内使用那肯定离不开中文分词,本文介绍如何配置使用(smartcn)
简介
solr5.0 默认的分词器是一元分词器,这个本来就是对英文进行分词的,英文大部分就是典型的根据空格进行分词,而中文如果按照这个规则,那么显然是要有很多的冗余词被分出来,一些没有用的虚词,数词,都会被分出来,影响效率不说,关键是分词效果不好,所以可以利用 solr 的同步发行包 smartcn 进行中文切词,smartcn 的分词准确率不错,但就是不能自己定义新的词库,不过 smartcn 是跟 solr 同步的,所以不需要额外的下载,只需在 solr 的例子中拷贝进去即可,下面给出路径图和安装 solr5.0 的 smartcn 分词过程
无论安装那种分词器,大部分都有2个步骤
拷贝jar包到solr的lib中
将 `solr-5.0.0\server\solr\test\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-5.0.0.jar` 拷贝到 `solr-5.0.0\server\solr\test\contrib\analysis-extras\lib` 目录下修改相关配置
solr-5.0.0\server\solr\test\conf\solrconfig.xml
<!-- annotating for smartcn, replaced by the blow config
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-velocity-\d.*\.jar" />
-->
<!-- smartcn config, instead of the previous code -->
<lib dir="E:\tools\solr-5.0.0\server\solr\test\contrib\analysis-extras\lib" regex=".*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\contrib\extraction\lib" regex=".*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\dist\" regex="solr-cell-\d.*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\contrib\clustering\lib\" regex=".*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\dist\" regex="solr-clustering-\d.*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\contrib\langid\lib\" regex=".*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\dist\" regex="solr-langid-\d.*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\contrib\velocity\lib" regex=".*\.jar" />
<lib dir="E:\tools\solr-5.0.0\server\solr\test\dist\" regex="solr-velocity-\d.*\.jar" />
solr-5.0.0\server\solr\test\conf\schema.xml
<!-- Smartcn -->
<fieldType name="text_smartcn" c l ass="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer c l ass="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter c l ass="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer c lass="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter c l ass="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>
将需要使用中文分词的字段类型改成 text_smartcn
<field name="goods_name" type="text_smartcn" indexed="true" stored="true"/>
最后来验证下中文分词安装是否成功
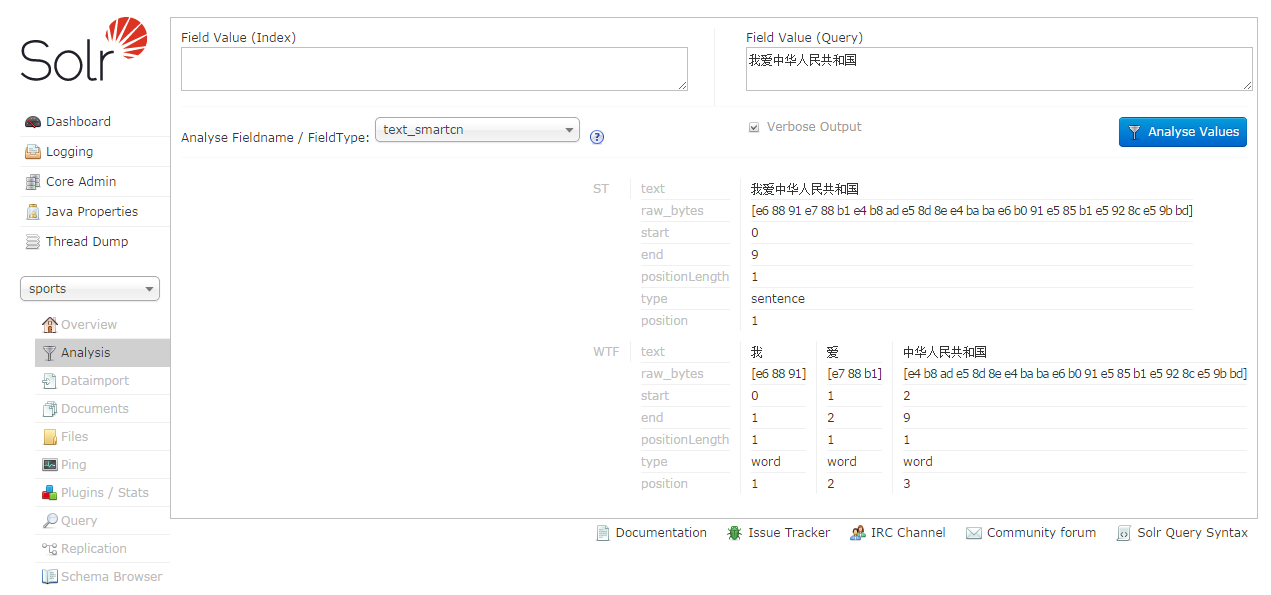
除了中文分词,另外还有一个拼音分词,这个网上可以搜到,需要下载一个 jar 包,其他配置、使用都跟上面类似,有兴趣的可以自己去试下。
来自 http://www.blogways.net/blog/2015/05/06/solr-usage-5.html
普通分类: