以下为学习整理内容,供自己翻阅和他人翻阅使用
星号 问号 感叹号 括号 尖括号 小括号 中括号 大括号 花括号 中短横
通配符(shell)
* 匹配任意多的字符(包括0个和1个)
? 匹配任意单个字符(不包括0个)
[characters] 匹配任意一个属于字符集中的字符
[^characters]或[!characters] 匹配任意一个不属于字符集中的字符
[[:class:]] 匹配任意一个属于指定字符类中的字符
{string1,string2,...} 匹配 sring1 或 string2 (或更多)其一字符串
字符类
[:alpha:] 英文大小写字符,亦A-Z a-z
[:alnum:] 英文大小写字符以及数字:亦A-Z a-z 0-9
[:blank:] 空格键与tab键
[:cntrl:] 键盘的控制按键
[:digit:] 数字,亦0-9
[:graph:] 除去空格符(空格键和tab键)外的其ls它所有符号
[:lower:] 代表小写字符,亦:a-z
[:print:] 任何可以被打印出来的字符
[:punct:] 标点符号
[:upper:] 大写字符,亦:A-Z
[:space:] 空白符
[:xdigit:] 16进位的数字类型,0-9,A-F,a-f的数字与字符
一些通配符的使用案例图
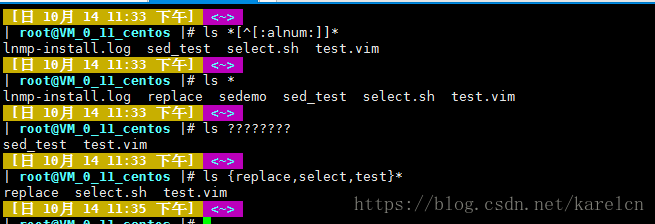

特殊符号(shell Meta字符)
IFS 由空格键、tab键、enter键三者之一组成
CR 由回车<enter>键产生
= 设定变量
$ 取用变量值或者运算值前导符
>,>> 数据流,重定向 输出导向(stdout) > 重定向取代,>>重定向增加
<,<< 数据流,重定向 输入导向(stdin) < 重定向文件内容 ,<< 键盘输入内容
| 管道符号,管线(pipe),分隔管线命令的界定
& 重导向文件描述符号(file descriptor) 例: &> 或者 2>&1 将标准输入输出文件重定向一个文件中
或者作为工作控制,将命令置于背景(后台)执行
() 将其内的命令置于子shell(nested subshell)执行
或用于运算
或命令的替换
{} 将其内的命令置于非命名函数(non-named function)中执行
或用在变量替换的界定范围,例:${PATH}:~/bin
; 连续指令分隔符,与管线不同,他是命令分隔符,不进行过滤处理
' ' 单引号,不具有变量置换(解析)功能($变为纯文本);硬转义,其内部所有的shell 元字符、通配符都会被关掉。
" " 双引号,具有变量置换(解析)功能($可保留相关功能);软转义,其内部只允许出现特定的shell 元字符
` ` 反引号,放置的命令可先执行的指令,与$(指令)功能相同
&& 逻辑运算与,在前一个命令结束时,若返回值为真(true),继续执行下一个命令
|| 逻辑运算或,在前一个命令结束时,若返回值为假(false),继续执行下一个命令
! 逻辑运算非
# 批注符号,常用在脚本中,视为说明,不执行
\ 跳脱字符,将特殊字符或者通配符还原成一般字符
/ 根目录符号,或者路径分隔符
~ 当前用户家目录
转义字符
\b 退格字符
\f 走纸符
\n 换行符
\r 回车符
\t 水平制表符
\v 垂直制表符
\ddd 1-3位八进制值
\xhex 十六进制值
\c 任何字面字符
正则表达式
linux中支持正则的编辑工具
编辑工具 基本正则表达式 扩展正则表达式
grep 支持 不支持
egrep 支持 支持
vi 支持 不支持
vim 支持 支持
sed 支持 不支持(-r选项支持)
awk 支持 支持
==基本正则表达式(元字符)==
^ 匹配指向一行的开头;
在awk中匹配字符串的开始,即使字符串包含嵌入的换行符
$ 匹配指向一行的结尾
在awk中匹配字符串的结尾,即使字符串包含嵌入的换行符
. 匹配任意单个字符(除了换行符外)
awk中,可以匹配换行符
c 匹配字母c
* 匹配前一个字符出现0次或多次
.* 匹配任意多个字符
[ ] 匹配集合中的任意单个字符,括号中为一个集合
[^ ]匹配否定,对括号中的集合取反
[ - ] 匹配连字符两边范围内
[[:class:]] 匹配字符类中的任意一个字符
\ 匹配转义后的特殊字符
\{n,m\} 匹配前面某个范围内单个字符重复n到m任意次数
\{n,\} 匹配前面某个范围内单个字符至少重复n次
\{n\} 匹配前面某个字符重复n次
\( \) 将\(与\)之间的内容存储在“保留空间”,最大存储9个
\n n表示1-9数字通过\1到9调用“保留空间”的内容
==扩展正则表达式(元字符)==
+ 匹配前面的正则表达式的一次或多次出现
? 匹配前面的正则表达式的零次或一次出现
| 匹配逻辑或,指定可以匹配其前面或后面的正则表达式
( ) 对正则表达式分组,正则集合
{n,m} 等同于基本表达式\{n,m\}
来自 https://blog.csdn.net/karelcn/article/details/83052395