参考链接:
https://blog.csdn.net/TSZ0000/article/details/87188128
在linux文件系统ext4中,如果一个目录下面文件数量太多(上W个),则在执行ls命令的时候,会非常慢, 原因有3点
原因1:
linux的ext4文件系统设计上,inode和文件名字是分离的, 即一个文件的文件名字是保存在父目录的数据块中
而,父目录的data block中存放的是 ext4_dir_entry_2 这个结构体的数组
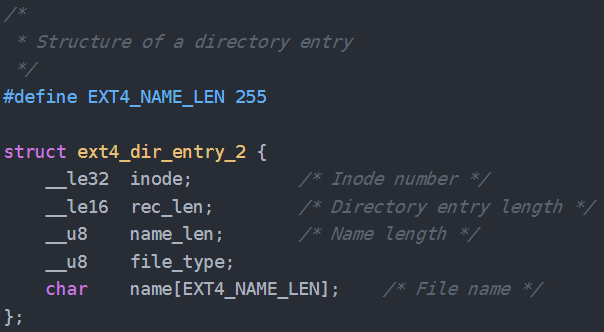
其中 name 就是文件名, inode就是这个文件的inode
所以,如果目录里面文件数量太多,就是导致这个目录的 data block 非常大, 查找文件,则是通过遍历name的方式进行,所以就导致效率很慢
虽然ext4增加了hash方式,但是只是针对当文件数量超过 一个 data block 时才有效,其目的主要是为了避免 按照name 把所有的data block都遍历一遍, 把遍历范围限制在一个data block内
原因2:
ls 命令通常情况下是需要 对name进行排序, 因此需要把所有的 文件信息都拿到内存中之后,再进行排序
因此会占用比较大的内存,并且速度会非常慢
所以这也是,为啥 执行 ls -1 -f 命令的时候, 速度要快很多, 内存占用也非常小的原因
-f 表示 不排序
-1 表示一行只输出一个文件名字
原因3:
文件的名字是存放在 父目录的 data block中
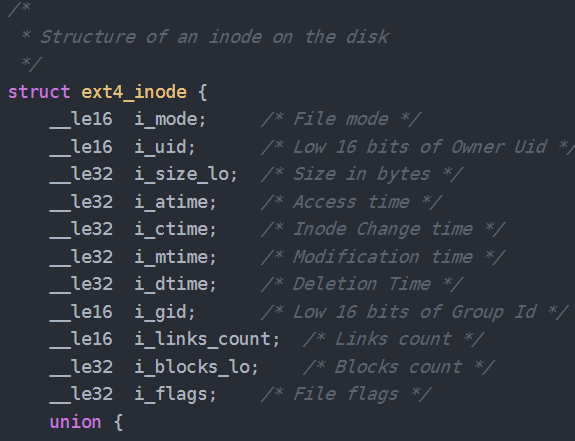
而文件的状态 atime,ctime, mtime, owner,group, perm, size等信息,都是存放在文件的inode中
因此,在遍历父目录的data block的时候, 也需要访问文件自身的inode信息
由于文件数量非常大, inode信息不一定连续, 可能会产生大量的随机IO, 并且每次的IO数据量都很小, 短时间内也无法进行合并读
随机IO多了, 性能就会下降,但是数据量其实非常小
参见inode的数据结构
https://blog.csdn.net/TSZ0000/article/details/87188128