You are here
在Oracle中,绑定变量是什么?绑定变量有什么优缺点? 有大用
在Oracle中,绑定变量是什么?绑定变量有什么优缺点?
绑定变量这节的内容较多,下面给出这节涉及到的关系图: (一)绑定变量的含义及优缺点 通常在高并发的OLTP系统中,可能会出现这样的现象,单个SQL的写法、执行计划、性能都是没问题的,但整个系统的性能就是很差,这表现在当系统并发的数量增加时,整个系统负载很高,CPU占用率接近100%。其实,这种系统性能随着并发量的递增而显著降低的现象,往往是因为这些系统没有使用绑定变量而产生了大量的硬解析所致。因为同一条SQL语句仅仅由于谓词部分变量的不同而在执行的时候就需要重新进行一次硬解析,造成SQL执行计划不能共享,这极大地耗费了系统时间和系统CPU资源。那么怎样才能降低OLTP应用系统的硬解析的数量呢?答案就是使用绑定变量。高并发的OLTP系统若没有使用绑定变量则会导致硬解析很大,这在AWR中的Load Profile部分可以很容易的看出来。 使用绑定变量能够有效降低系统硬解析的数量。对于同一类型的SQL语句若使用了绑定变量,则SQL文本就变得完全相同了,据此计算出来的哈希值也就完全相同,这就具备了可以重用解析树和执行计划的基础条件。这里的同一类型的SQL语句指的是除SQL文本中对应的输入值不同外其它部分都一模一样的SQL语句。例如,银行的查询余额的SQL语句,在成千上万次查询中都只是账户名不同,而SQL语句的其它部分都一样。若没有使用绑定变量,则每查询一次都必须进行一次硬解析。如果使用了绑定变量,假设每次可以节省0.001秒,那么在高并发下上千万次查询节省下来的时间将是非常大的,这在无形中就提高了系统的响应时间。 绑定变量(Bind Variable)其实质是变量,类似于经常使用的替代变量,只不过替代变量使用“&”作为占位符,而绑定变量使用英文冒号(:)作为占位符,替代变量使用方式为&VARIABLE_PARA,相应的绑定变量则为:BIND_VARIABLE_PARA。绑定变量通常出现在SQL文本中,用于替换WHERE或VALUES子句中的具体值。 绑定变量的优点如下所示: ① 可以在库缓存(Library Cache)中共享游标,避免硬解析以及与之相关的额外开销。换句话说,绑定变量可以有效地减少SQL硬解析的次数,从而减少系统资源开销,这也是使用绑定变量最大的作用。 ② 在大批量数据操作时,可以大量减少闩锁的使用,从而避免闩锁(Latch)的争用。 ③ 提高了代码的可读性(避免拼接式的硬编码)和安全性(防止SQL注入)。 绑定变量的缺点主要体现在当使用绑定变量时,查询优化器会忽略其具体值,因此,其预估的准确性远不如使用字面量值真实。当表的列上存在数据倾斜(表上的数据非均匀分布)时,Oracle可能会提供错误的执行计划,从而使得非高效的执行计划被使用。 需要注意的是,目标SQL中的绑定变量个数不宜太多,否则可能会导致目标SQL总的执行时间大幅度增长。增长的时间主要耗费在执行目标SQL时对每一个绑定变量都用其实际的值来替换(这个过程就是所谓的绑定变量值替换),目标SQL的SQL文本中的绑定变量的个数越多,这个替换过程所耗费的时间就越长,该SQL总的执行时间也就越长。 (二)绑定变量的适用场合 对于绑定变量应该根据系统的类型来决定是否使用绑定变量,如下所示: l 在高并发的OLTP系统中,SQL语句重复执行频度高,但处理的数据量较少,结果集也相对较小,尤其是使用表上的索引来缩小中间结果集,其解析时间通常会接近或高于执行时间,因此,在该场合一定要使用绑定变量,并且最好是使用批量绑定,因为可以有效降低系统硬解析的数量,这也是OLTP类型的系统在数据库端具备良好的性能和可扩展性的前提条件。 l 在OLAP/DSS系统中,SQL语句执行次数相对较少,但返回的数据量较大,其SQL语句执行时间远高于其解析时间,硬解析对系统性能的影响是微乎其微的,因此,使用绑定变量对于总的执行时间影响不大,对系统性能的提升也非常有限。 l 对于OLAP和OLTP混合型的应用系统,如果有循环,不管这个循环是在前台代码还是在后台PL/SQL代码中,循环内部的SQL语句一定要使用绑定变量,并且最好是使用批量绑定:至于循环外部的SQL语句,可以不使用绑定变量。 需要注意的是,对于实际的数据库对象,例如表、视图等,不能使用绑定变量替换,只能替换字面量。如果对象名是在运行时生成的,那么需要对其用字符串拼接,同时,SQL只会匹配已经在共享池中存在且相同的对象名。 (三)绑定变量的使用方法 对于上述这种使用绑定变量的方式,关键字“USING”后传入的绑定变量具体输入值只与对应绑定变量在目标SQL中所处的位置有关,而与其名称无关,这意味着只要目标SQL中绑定变量所处的位置不同,它们所对应的绑定变量名称是可以相同的。上述代码执行结果为2,查询: 上述PL/SQL代码实现的是,删除表T_EMP_LHR里列EMPNO的值为7369的记录,并且将该记录的列ENAME的值打印出来。 c. 在PL/SQL中通过批量绑定的方式使用绑定变量。 PL/SQL中的“批量绑定”是一种优化后的使用绑定变量的方式。批量绑定的优势在于它是一次处理一批数据,而不是像常规方式那样一次只处理一条数据,所以它能够有效减少PL/SQL引擎和SQL引擎上下文切换的次数。批量绑定的主要方式是使用BULK COLLECT INTO和FORALL的方式来实现,下面给出一个示例: 其它示例可以参考【3.1.10.2 如何使用批量动态SQL(FORALL及BULK子句的使用)?】。 ③ 在Java中使用绑定变量 在Java中也有绑定变量和批量绑定的用法,本书不再详解。 真题1、下面有关SQL绑定变量的描述中,错误的是() A、绑定变量是指在SQL语句中使用变量,改变变量的值来改变SQL语句的执行结果 B、使用绑定变量,可以减少SQL语句的解析,能减少数据库引擎消耗在SQL语句解析上的资源 C、使用绑定变量,提高了编程效率和可靠性,减少访问数据库的次数 D、使用绑定变量,查询优化器会预估的比字面变量更加真实 答案:D。 绑定变量是相对文本变量来讲的,所谓文本变量是指在SQL中直接书写查询条件,这样的SQL在不同条件下需要反复解析,绑定变量是指使用变量来代替直接书写条件,查询绑定变量在运行时传递,然后绑定执行。优点是减少硬解析,降低CPU的争用,节省Shared Pool;缺点是不能使用固定的执行计划,SQL优化比较困难。 本题中,对于选项A,绑定变量就是之前不知道具体的值,只有运行的时候才知道值,改变变量的值来改变SQL语句的执行结果。所以,选项A错误。 对于选项B,使用绑定变量,可以减少SQL语句的解析,说法正确。所以,选项B错误。 对于选项C,使用绑定变量,减少解析次数,提高了编程效率和可靠性。所以,选项C错误。 对于选项D,使用绑定变量,查询优化器不知道具体的值,所以,其执行计划也不真实。所以,选项D正确。 所以,本题的答案为D。 本文选自《Oracle程序员面试笔试宝典》,作者:李华荣。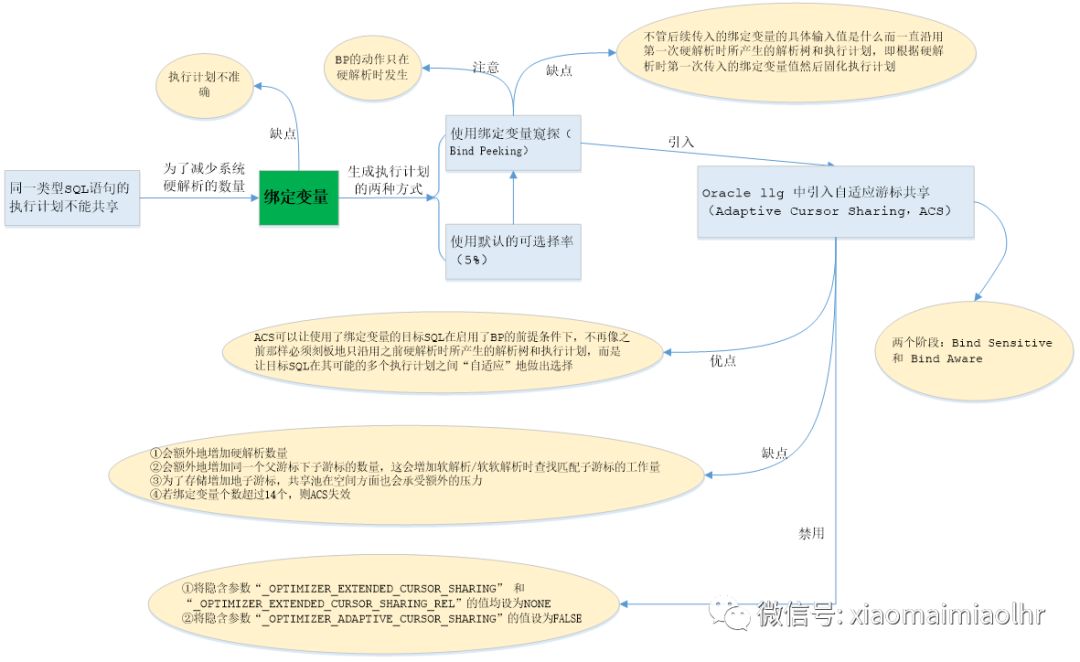
1--① 在SQL中,用法如下所示:
2var v_empno number; --声明变量
3exec :v_empno :=7369; --变量赋值
4select * from scott.emp where empno=:v_empno;--使用绑定变量
5
6--② 在PL/SQL中,有如下几种用法:
7-----a.在静态SQL中使用绑定变量:
8DECLARE
9 V_NAME VARCHAR2(10);
10BEGIN
11 EXECUTE IMMEDIATE 'select ename from scott.emp where empno=:1' INTO V_NAME USING 7369;
12 DBMS_OUTPUT.PUT_LINE(V_NAME);
13END;
14-----b.在动态SQL中使用绑定变量:
15DROP TABLE T_EMP_LHR;
16CREATE TABLE T_EMP_LHR AS SELECT * FROM SCOTT.EMP;
17DECLARE
18 V_SQL1 VARCHAR2(4000);
19 V_SQL2 VARCHAR2(4000);
20 V_TMP1 NUMBER;
21 V_TMP2 NUMBER;
22BEGIN
23 V_SQL1:='INSERT INTO T_EMP_LHR(empno,ename,job) values(:1,:2,:3)';
24 EXECUTE IMMEDIATE V_SQL1 USING 6666,'lhr6','DBA';
25 V_TMP1:=SQL%ROWCOUNT;
26 V_SQL2:='INSERT INTO T_EMP_LHR(empno,ename,job) values(:1,:1,:1)';
27 EXECUTE IMMEDIATE V_SQL2 USING 6667,'lhr7','DBA';
28 V_TMP2:=SQL%ROWCOUNT;
29 DBMS_OUTPUT.PUT_LINE(V_TMP1+V_TMP2);
30END;
31 1LHR@orclasm > SELECT * FROM T_EMP_LHR t WHERE t.job='DBA';
2
3 EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
4---------- ---------- --------- ---------- ------------------- ---------- ---------- ----------
5 6666 lhr6 DBA
6 6667 lhr7 DBA
7
8--再给出一个示例:
9DECLARE
10 V_COLUNMS VARCHAR2(30) :='EMPNO';
11 V_SQL VARCHAR2(4000);
12 V_ENAME VARCHAR2(20);
13BEGIN
14 V_SQL:='DELETE FROM T_EMP_LHR WHERE '||V_COLUNMS||'=:1 RETURNING ENAME INTO :2';
15 EXECUTE IMMEDIATE V_SQL USING 7369 RETURNING INTO V_ENAME;
16 DBMS_OUTPUT.PUT_LINE(V_ENAME);
17END; 1DECLARE
2 TYPE EMPCURTYPE IS REF CURSOR; --定义游标类型及游标变量
3 EMP_CV EMPCURTYPE;
4 TYPE ENAME_TABLE_TYPE IS TABLE OF T_EMP_LHR.ENAME%TYPE INDEX BY BINARY_INTEGER; --定义结果集类型及变量
5 ENAME_TABLE ENAME_TABLE_TYPE;
6 SQL_STAT VARCHAR2(120);
7 CN_BATCH_SIZE CONSTANT PLS_INTEGER := 1000;
8BEGIN
9 SQL_STAT := 'SELECT ENAME FROM T_EMP_LHR WHERE DEPTNO > :1'; --动态SQL字符串
10 OPEN EMP_CV FOR SQL_STAT USING 1; --从动态SQL中打开游标
11 LOOP
12 FETCH EMP_CV BULK COLLECT INTO ENAME_TABLE LIMIT CN_BATCH_SIZE; --使用BULK COLLECT INTO提取结果集
13 FOR I IN 1 .. ENAME_TABLE.COUNT LOOP
14 DBMS_OUTPUT.PUT_LINE('Employee Name is ' || ENAME_TABLE(I));
15 END LOOP;
16 EXIT WHEN ENAME_TABLE.COUNT < CN_BATCH_SIZE;
17 END LOOP;
18 CLOSE EMP_CV;
19END;
来自 https://www.modb.pro/db/14349