You are here
Python简介 廖雪峰的官方网站7 安装mysql 有大用

安装MySQL驱动
使用python 连接 mysql 有两个库,一个是 mysql-python ;另外一个是 mysql-connector使用的时候要区分开。使用哪个安装哪个。
1)mysql-connector 应该可以到 http://dev.mysql.com/downloads/connector/python/2.0.html (mysql的官网)上下
下面这个肯定可以 MySQL-python-1.2.3.win-amd64-py2.7.exe
( http://www.codegood.com/archives/129 )google 下 "MySQL-python" "MySQL-python download"
"mysql-connector-python" "mysql-connector-python download"
会发现很多有用的的东西
2)mysql-python
我的,win7,64位,2.7版本
MySQL-python-1.2.3.win-amd64-py2.7.exe
( http://www.codegood.com/archives/129 )使用python 连接 mysql 有两个库,一个是 mysql-python ;另外一个是 mysql-connector
使用的时候要区分开。使用哪个安装哪个。
常用内建模块
Python之所以自称“batteries included”,就是因为内置了许多非常有用的模块,无需额外安装和配置,即可直接使用。
本章将介绍一些常用的内建模块。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386832257831f46c9ba77b3e468a82e015f5ba415612000
collections
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
定义一个class又小题大做了,这时,namedtuple就派上了用场:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
可以验证创建的Point对象是tuple的一种子类:
>>> isinstance(p, Point)
True
>>> isinstance(p, tuple)
True
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
# namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print 'remove:', last
if containsKey:
del self[key]
print 'set:', (key, value)
else:
print 'add:', (key, value)
OrderedDict.__setitem__(self, key, value)
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'programming':
... c[ch] = c[ch] + 1
...
>>> c
Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
Counter实际上也是dict的一个子类,上面的结果可以看出,字符'g'、'm'、'r'各出现了两次,其他字符各出现了一次。
小结
collections模块提供了一些有用的集合类,可以根据需要选用。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001411031239400f7...
base64
Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含64个字符的数组:
['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit:
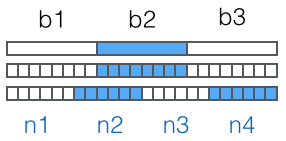
这样我们得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
Python内置的base64可以直接进行base64的编解码:
>>> import base64
>>> base64.b64encode('binary\x00string')
'YmluYXJ5AHN0cmluZw=='
>>> base64.b64decode('YmluYXJ5AHN0cmluZw==')
'binary\x00string'
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_:
>>> base64.b64encode('i\xb7\x1d\xfb\xef\xff')
'abcd++//'
>>> base64.urlsafe_b64encode('i\xb7\x1d\xfb\xef\xff')
'abcd--__'
>>> base64.urlsafe_b64decode('abcd--__')
'i\xb7\x1d\xfb\xef\xff'
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
Base64是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。
Base64适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:
# 标准Base64:
'abcd' -> 'YWJjZA=='
# 自动去掉=:
'abcd' -> 'YWJjZA'
去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
请写一个能处理去掉=的base64解码函数:
>>> base64.b64decode('YWJjZA==')
'abcd'
>>> base64.b64decode('YWJjZA')
Traceback (most recent call last):
...
TypeError: Incorrect padding
>>> safe_b64decode('YWJjZA')
'abcd'
小结
Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001399413803339f4...
struct
准确地讲,Python没有专门处理字节的数据类型。但由于str既是字符串,又可以表示字节,所以,字节数组=str。而在C语言中,我们可以很方便地用struct、union来处理字节,以及字节和int,float的转换。
在Python中,比方说要把一个32位无符号整数变成字节,也就是4个长度的str,你得配合位运算符这么写:
>>> n = 10240099
>>> b1 = chr((n & 0xff000000) >> 24)
>>> b2 = chr((n & 0xff0000) >> 16)
>>> b3 = chr((n & 0xff00) >> 8)
>>> b4 = chr(n & 0xff)
>>> s = b1 + b2 + b3 + b4
>>> s
'\x00\x9c@c'
非常麻烦。如果换成浮点数就无能为力了。
好在Python提供了一个struct模块来解决str和其他二进制数据类型的转换。
struct的pack函数把任意数据类型变成字符串:
>>> import struct
>>> struct.pack('>I', 10240099)
'\x00\x9c@c'
pack的第一个参数是处理指令,'>I'的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
后面的参数个数要和处理指令一致。
unpack把str变成相应的数据类型:
>>> struct.unpack('>IH', '\xf0\xf0\xf0\xf0\x80\x80')
(4042322160, 32896)
根据>IH的说明,后面的str依次变为I:4字节无符号整数和H:2字节无符号整数。
所以,尽管Python不适合编写底层操作字节流的代码,但在对性能要求不高的地方,利用struct就方便多了。
struct模块定义的数据类型可以参考Python官方文档:
https://docs.python.org/2/library/struct.html#format-characters
Windows的位图文件(.bmp)是一种非常简单的文件格式,我们来用struct分析一下。
首先找一个bmp文件,没有的话用“画图”画一个。
读入前30个字节来分析:
>>> s = '\x42\x4d\x38\x8c\x0a\x00\x00\x00\x00\x00\x36\x00\x00\x00\x28\x00\x00\x00\x80\x02\x00\x00\x68\x01\x00\x00\x01\x00\x18\x00'
BMP格式采用小端方式存储数据,文件头的结构按顺序如下:
两个字节:'BM'表示Windows位图,'BA'表示OS/2位图; 一个4字节整数:表示位图大小; 一个4字节整数:保留位,始终为0; 一个4字节整数:实际图像的偏移量; 一个4字节整数:Header的字节数; 一个4字节整数:图像宽度; 一个4字节整数:图像高度; 一个2字节整数:始终为1; 一个2字节整数:颜色数。
所以,组合起来用unpack读取:
>>> struct.unpack('<ccIIIIIIHH', s)
('B', 'M', 691256, 0, 54, 40, 640, 360, 1, 24)
结果显示,'B'、'M'说明是Windows位图,位图大小为640x360,颜色数为24。
请编写一个bmpinfo.py,可以检查任意文件是否是位图文件,如果是,打印出图片大小和颜色数。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0013994173393204e...
hashlib
摘要算法简介
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
举个例子,你写了一篇文章,内容是一个字符串'how to use python hashlib - by Michael',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'。如果有人篡改了你的文章,并发表为'how to use python hashlib - by Bob',你可以一下子指出Bob篡改了你的文章,因为根据'how to use python hashlib - by Bob'计算出的摘要不同于原始文章的摘要。
可见,摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?')
print md5.hexdigest()
计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 = hashlib.md5()
md5.update('how to use md5 in ')
md5.update('python hashlib?')
print md5.hexdigest()
试试改动一个字母,看看计算的结果是否完全不同。
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in ')
sha1.update('python hashlib?')
print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要?完全有可能,因为任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。这种情况称为碰撞,比如Bob试图根据你的摘要反推出一篇文章'how to learn hashlib in python - by Bob',并且这篇文章的摘要恰好和你的文章完全一致,这种情况也并非不可能出现,但是非常非常困难。
摘要算法应用
摘要算法能应用到什么地方?举个常用例子:
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password
--------+----------
michael | 123456
bob | abc999
alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。
正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password
---------+---------------------------------
michael | e10adc3949ba59abbe56e057f20f883e
bob | 878ef96e86145580c38c87f0410ad153
alice | 99b1c2188db85afee403b1536010c2c9
当用户登录时,首先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明口令输入正确,如果不一致,口令肯定错误。
练习:根据用户输入的口令,计算出存储在数据库中的MD5口令:
def calc_md5(password):
pass
存储MD5的好处是即使运维人员能访问数据库,也无法获知用户的明文口令。
练习:设计一个验证用户登录的函数,根据用户输入的口令是否正确,返回True或False:
db = {
'michael': 'e10adc3949ba59abbe56e057f20f883e',
'bob': '878ef96e86145580c38c87f0410ad153',
'alice': '99b1c2188db85afee403b1536010c2c9'
}
def login(user, password):
pass
采用MD5存储口令是否就一定安全呢?也不一定。假设你是一个黑客,已经拿到了存储MD5口令的数据库,如何通过MD5反推用户的明文口令呢?暴力破解费事费力,真正的黑客不会这么干。
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456'
'21218cca77804d2ba1922c33e0151105': '888888'
'5f4dcc3b5aa765d61d8327deb882cf99': 'password'
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
def calc_md5(password):
return get_md5(password + 'the-Salt')
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
练习:根据用户输入的登录名和口令模拟用户注册,计算更安全的MD5:
db = {}
def register(username, password):
db[username] = get_md5(password + username + 'the-Salt')
然后,根据修改后的MD5算法实现用户登录的验证:
def login(username, password):
pass
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0013868328251266d...
XML
XML虽然比JSON复杂,在Web中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作XML。
DOM vs SAX
操作XML有两种方法:DOM和SAX。DOM会把整个XML读入内存,解析为树,因此占用内存大,解析慢,优点是可以任意遍历树的节点。SAX是流模式,边读边解析,占用内存小,解析快,缺点是我们需要自己处理事件。
正常情况下,优先考虑SAX,因为DOM实在太占内存。
在Python中使用SAX解析XML非常简洁,通常我们关心的事件是start_element,end_element和char_data,准备好这3个函数,然后就可以解析xml了。
举个例子,当SAX解析器读到一个节点时:
<a href="/">python</a>
会产生3个事件:
start_element事件,在读取
<a href="/">时;char_data事件,在读取
python时;end_element事件,在读取
</a>时。
用代码实验一下:
from xml.parsers.expat import ParserCreate
class DefaultSaxHandler(object):
def start_element(self, name, attrs):
print('sax:start_element: %s, attrs: %s' % (name, str(attrs)))
def end_element(self, name):
print('sax:end_element: %s' % name)
def char_data(self, text):
print('sax:char_data: %s' % text)
xml = r'''<?xml version="1.0"?>
<ol>
<li><a href="/python">Python</a></li>
<li><a href="/ruby">Ruby</a></li>
</ol>
'''
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.returns_unicode = True
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
parser.Parse(xml)
当设置returns_unicode为True时,返回的所有element名称和char_data都是unicode,处理国际化更方便。
需要注意的是读取一大段字符串时,CharacterDataHandler可能被多次调用,所以需要自己保存起来,在EndElementHandler里面再合并。
除了解析XML外,如何生成XML呢?99%的情况下需要生成的XML结构都是非常简单的,因此,最简单也是最有效的生成XML的方法是拼接字符串:
L = []
L.append(r'<?xml version="1.0"?>')
L.append(r'<root>')
L.append(encode('some & data'))
L.append(r'</root>')
return ''.join(L)
如果要生成复杂的XML呢?建议你不要用XML,改成JSON。
小结
解析XML时,注意找出自己感兴趣的节点,响应事件时,把节点数据保存起来。解析完毕后,就可以处理数据。
练习一下解析Yahoo的XML格式的天气预报,获取当天和最近几天的天气:
http://weather.yahooapis.com/forecastrss?u=c&w=2151330
参数w是城市代码,要查询某个城市代码,可以在weather.yahoo.com搜索城市,浏览器地址栏的URL就包含城市代码。
HTMLParser
如果我们要编写一个搜索引擎,第一步是用爬虫把目标网站的页面抓下来,第二步就是解析该HTML页面,看看里面的内容到底是新闻、图片还是视频。
假设第一步已经完成了,第二步应该如何解析HTML呢?
HTML本质上是XML的子集,但是HTML的语法没有XML那么严格,所以不能用标准的DOM或SAX来解析HTML。
好在Python提供了HTMLParser来非常方便地解析HTML,只需简单几行代码:
from HTMLParser import HTMLParser
from htmlentitydefs import name2codepoint
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print('<%s>' % tag)
def handle_endtag(self, tag):
print('</%s>' % tag)
def handle_startendtag(self, tag, attrs):
print('<%s/>' % tag)
def handle_data(self, data):
print('data')
def handle_comment(self, data):
print('<!-- -->')
def handle_entityref(self, name):
print('&%s;' % name)
def handle_charref(self, name):
print('&#%s;' % name)
parser = MyHTMLParser()
parser.feed('<html><head></head><body><p>Some <a href=\"#\">html</a> tutorial...<br>END</p></body></html>')
feed()方法可以多次调用,也就是不一定一次把整个HTML字符串都塞进去,可以一部分一部分塞进去。
特殊字符有两种,一种是英文表示的 ,一种是数字表示的Ӓ,这两种字符都可以通过Parser解析出来。
小结
找一个网页,例如https://www.python.org/events/python-events/,用浏览器查看源码并复制,然后尝试解析一下HTML,输出Python官网发布的会议时间、名称和地点。
常用第三方模块
除了内建的模块外,Python还有大量的第三方模块。
基本上,所有的第三方模块都会在PyPI - the Python Package Index上注册,只要找到对应的模块名字,即可用easy_install或者pip安装。
本章介绍常用的第三方模块。
PIL
PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用。
安装PIL
在Debian/Ubuntu Linux下直接通过apt安装:
$ sudo apt-get install python-imaging
Mac和其他版本的Linux可以直接使用easy_install或pip安装,安装前需要把编译环境装好:
$ sudo easy_install PIL
如果安装失败,根据提示先把缺失的包(比如openjpeg)装上。
Windows平台就去PIL官方网站下载exe安装包。
操作图像
来看看最常见的图像缩放操作,只需三四行代码:
import Image
# 打开一个jpg图像文件,注意路径要改成你自己的:
im = Image.open('/Users/michael/test.jpg')
# 获得图像尺寸:
w, h = im.size
# 缩放到50%:
im.thumbnail((w//2, h//2))
# 把缩放后的图像用jpeg格式保存:
im.save('/Users/michael/thumbnail.jpg', 'jpeg')
其他功能如切片、旋转、滤镜、输出文字、调色板等一应俱全。
比如,模糊效果也只需几行代码:
import Image, ImageFilter
im = Image.open('/Users/michael/test.jpg')
im2 = im.filter(ImageFilter.BLUR)
im2.save('/Users/michael/blur.jpg', 'jpeg')
效果如下:

PIL的ImageDraw提供了一系列绘图方法,让我们可以直接绘图。比如要生成字母验证码图片:
import Image, ImageDraw, ImageFont, ImageFilter
import random
# 随机字母:
def rndChar():
return chr(random.randint(65, 90))
# 随机颜色1:
def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))
# 随机颜色2:
def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))
# 240 x 60:
width = 60 * 4
height = 60
image = Image.new('RGB', (width, height), (255, 255, 255))
# 创建Font对象:
font = ImageFont.truetype('Arial.ttf', 36)
# 创建Draw对象:
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save('code.jpg', 'jpeg');
我们用随机颜色填充背景,再画上文字,最后对图像进行模糊,得到验证码图片如下:

如果运行的时候报错:
IOError: cannot open resource
这是因为PIL无法定位到字体文件的位置,可以根据操作系统提供绝对路径,比如:
'/Library/Fonts/Arial.ttf'
要详细了解PIL的强大功能,请请参考PIL官方文档:
图形界面
Python支持多种图形界面的第三方库,包括:
Tk
wxWidgets
Qt
GTK
等等。
但是Python自带的库是支持Tk的Tkinter,使用Tkinter,无需安装任何包,就可以直接使用。本章简单介绍如何使用Tkinter进行GUI编程。
Tkinter
我们来梳理一下概念:
我们编写的Python代码会调用内置的Tkinter,Tkinter封装了访问Tk的接口;
Tk是一个图形库,支持多个操作系统,使用Tcl语言开发;
Tk会调用操作系统提供的本地GUI接口,完成最终的GUI。
所以,我们的代码只需要调用Tkinter提供的接口就可以了。
第一个GUI程序
使用Tkinter十分简单,我们来编写一个GUI版本的“Hello, world!”。
第一步是导入Tkinter包的所有内容:
from Tkinter import *
第二步是从Frame派生一个Application类,这是所有Widget的父容器:
class Application(Frame):
def __init__(self, master=None):
Frame.__init__(self, master)
self.pack()
self.createWidgets()
def createWidgets(self):
self.helloLabel = Label(self, text='Hello, world!')
self.helloLabel.pack()
self.quitButton = Button(self, text='Quit', command=self.quit)
self.quitButton.pack()
在GUI中,每个Button、Label、输入框等,都是一个Widget。Frame则是可以容纳其他Widget的Widget,所有的Widget组合起来就是一棵树。
pack()方法把Widget加入到父容器中,并实现布局。pack()是最简单的布局,grid()可以实现更复杂的布局。
在createWidgets()方法中,我们创建一个Label和一个Button,当Button被点击时,触发self.quit()使程序退出。
第三步,实例化Application,并启动消息循环:
app = Application()
# 设置窗口标题:
app.master.title('Hello World')
# 主消息循环:
app.mainloop()
GUI程序的主线程负责监听来自操作系统的消息,并依次处理每一条消息。因此,如果消息处理非常耗时,就需要在新线程中处理。
运行这个GUI程序,可以看到下面的窗口:
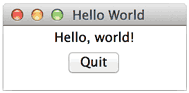
点击“Quit”按钮或者窗口的“x”结束程序。
输入文本
我们再对这个GUI程序改进一下,加入一个文本框,让用户可以输入文本,然后点按钮后,弹出消息对话框。
from Tkinter import *
import tkMessageBox
class Application(Frame):
def __init__(self, master=None):
Frame.__init__(self, master)
self.pack()
self.createWidgets()
def createWidgets(self):
self.nameInput = Entry(self)
self.nameInput.pack()
self.alertButton = Button(self, text='Hello', command=self.hello)
self.alertButton.pack()
def hello(self):
name = self.nameInput.get() or 'world'
tkMessageBox.showinfo('Message', 'Hello, %s' % name)
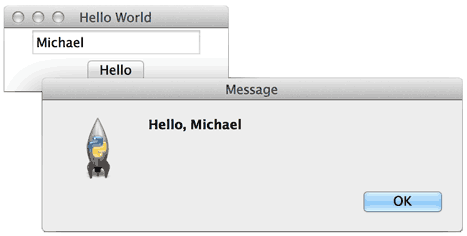
当用户点击按钮时,触发hello(),通过self.nameInput.get()获得用户输入的文本后,使用tkMessageBox.showinfo()可以弹出消息对话框。
程序运行结果如下:
小结
Python内置的Tkinter可以满足基本的GUI程序的要求,如果是非常复杂的GUI程序,建议用操作系统原生支持的语言和库来编写。
源码参考:https://github.com/michaelliao/learn-python/tree/master/gui
网络编程
自从互联网诞生以来,现在基本上所有的程序都是网络程序,很少有单机版的程序了。
计算机网络就是把各个计算机连接到一起,让网络中的计算机可以互相通信。网络编程就是如何在程序中实现两台计算机的通信。
举个例子,当你使用浏览器访问新浪网时,你的计算机就和新浪的某台服务器通过互联网连接起来了,然后,新浪的服务器把网页内容作为数据通过互联网传输到你的电脑上。
由于你的电脑上可能不止浏览器,还有QQ、Skype、Dropbox、邮件客户端等,不同的程序连接的别的计算机也会不同,所以,更确切地说,网络通信是两台计算机上的两个进程之间的通信。比如,浏览器进程和新浪服务器上的某个Web服务进程在通信,而QQ进程是和腾讯的某个服务器上的某个进程在通信。

网络编程对所有开发语言都是一样的,Python也不例外。用Python进行网络编程,就是在Python程序本身这个进程内,连接别的服务器进程的通信端口进行通信。
本章我们将详细介绍Python网络编程的概念和最主要的两种网络类型的编程。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/00138683226192949...
TCP/IP简介
虽然大家现在对互联网很熟悉,但是计算机网络的出现比互联网要早很多。
计算机为了联网,就必须规定通信协议,早期的计算机网络,都是由各厂商自己规定一套协议,IBM、Apple和Microsoft都有各自的网络协议,互不兼容,这就好比一群人有的说英语,有的说中文,有的说德语,说同一种语言的人可以交流,不同的语言之间就不行了。
为了把全世界的所有不同类型的计算机都连接起来,就必须规定一套全球通用的协议,为了实现互联网这个目标,互联网协议簇(Internet Protocol Suite)就是通用协议标准。Internet是由inter和net两个单词组合起来的,原意就是连接“网络”的网络,有了Internet,任何私有网络,只要支持这个协议,就可以联入互联网。
因为互联网协议包含了上百种协议标准,但是最重要的两个协议是TCP和IP协议,所以,大家把互联网的协议简称TCP/IP协议。
通信的时候,双方必须知道对方的标识,好比发邮件必须知道对方的邮件地址。互联网上每个计算机的唯一标识就是IP地址,类似123.123.123.123。如果一台计算机同时接入到两个或更多的网络,比如路由器,它就会有两个或多个IP地址,所以,IP地址对应的实际上是计算机的网络接口,通常是网卡。
IP协议负责把数据从一台计算机通过网络发送到另一台计算机。数据被分割成一小块一小块,然后通过IP包发送出去。由于互联网链路复杂,两台计算机之间经常有多条线路,因此,路由器就负责决定如何把一个IP包转发出去。IP包的特点是按块发送,途径多个路由,但不保证能到达,也不保证顺序到达。
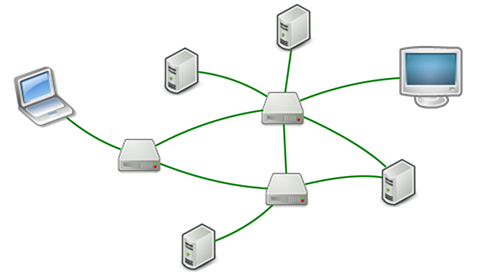
TCP协议则是建立在IP协议之上的。TCP协议负责在两台计算机之间建立可靠连接,保证数据包按顺序到达。TCP协议会通过握手建立连接,然后,对每个IP包编号,确保对方按顺序收到,如果包丢掉了,就自动重发。
许多常用的更高级的协议都是建立在TCP协议基础上的,比如用于浏览器的HTTP协议、发送邮件的SMTP协议等。
一个IP包除了包含要传输的数据外,还包含源IP地址和目标IP地址,源端口和目标端口。
端口有什么作用?在两台计算机通信时,只发IP地址是不够的,因为同一台计算机上跑着多个网络程序。一个IP包来了之后,到底是交给浏览器还是QQ,就需要端口号来区分。每个网络程序都向操作系统申请唯一的端口号,这样,两个进程在两台计算机之间建立网络连接就需要各自的IP地址和各自的端口号。
一个进程也可能同时与多个计算机建立链接,因此它会申请很多端口。
了解了TCP/IP协议的基本概念,IP地址和端口的概念,我们就可以开始进行网络编程了。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0013868324942775d...
TCP编程
Socket是网络编程的一个抽象概念。通常我们用一个Socket表示“打开了一个网络链接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,再指定协议类型即可。
客户端
大多数连接都是可靠的TCP连接。创建TCP连接时,主动发起连接的叫客户端,被动响应连接的叫服务器。
举个例子,当我们在浏览器中访问新浪时,我们自己的计算机就是客户端,浏览器会主动向新浪的服务器发起连接。如果一切顺利,新浪的服务器接受了我们的连接,一个TCP连接就建立起来的,后面的通信就是发送网页内容了。
所以,我们要创建一个基于TCP连接的Socket,可以这样做:
# 导入socket库:
import socket
# 创建一个socket:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('www.sina.com.cn', 80))
创建Socket时,AF_INET指定使用IPv4协议,如果要用更先进的IPv6,就指定为AF_INET6。SOCK_STREAM指定使用面向流的TCP协议,这样,一个Socket对象就创建成功,但是还没有建立连接。
客户端要主动发起TCP连接,必须知道服务器的IP地址和端口号。新浪网站的IP地址可以用域名www.sina.com.cn自动转换到IP地址,但是怎么知道新浪服务器的端口号呢?
答案是作为服务器,提供什么样的服务,端口号就必须固定下来。由于我们想要访问网页,因此新浪提供网页服务的服务器必须把端口号固定在80端口,因为80端口是Web服务的标准端口。其他服务都有对应的标准端口号,例如SMTP服务是25端口,FTP服务是21端口,等等。端口号小于1024的是Internet标准服务的端口,端口号大于1024的,可以任意使用。
因此,我们连接新浪服务器的代码如下:
s.connect(('www.sina.com.cn', 80))
注意参数是一个tuple,包含地址和端口号。
建立TCP连接后,我们就可以向新浪服务器发送请求,要求返回首页的内容:
# 发送数据:
s.send('GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n')
TCP连接创建的是双向通道,双方都可以同时给对方发数据。但是谁先发谁后发,怎么协调,要根据具体的协议来决定。例如,HTTP协议规定客户端必须先发请求给服务器,服务器收到后才发数据给客户端。
发送的文本格式必须符合HTTP标准,如果格式没问题,接下来就可以接收新浪服务器返回的数据了:
# 接收数据:
buffer = []
while True:
# 每次最多接收1k字节:
d = s.recv(1024)
if d:
buffer.append(d)
else:
break
data = ''.join(buffer)
接收数据时,调用recv(max)方法,一次最多接收指定的字节数,因此,在一个while循环中反复接收,直到recv()返回空数据,表示接收完毕,退出循环。
当我们接收完数据后,调用close()方法关闭Socket,这样,一次完整的网络通信就结束了:
# 关闭连接:
s.close()
接收到的数据包括HTTP头和网页本身,我们只需要把HTTP头和网页分离一下,把HTTP头打印出来,网页内容保存到文件:
header, html = data.split('\r\n\r\n', 1)
print header
# 把接收的数据写入文件:
with open('sina.html', 'wb') as f:
f.write(html)
现在,只需要在浏览器中打开这个sina.html文件,就可以看到新浪的首页了。
服务器
和客户端编程相比,服务器编程就要复杂一些。
服务器进程首先要绑定一个端口并监听来自其他客户端的连接。如果某个客户端连接过来了,服务器就分配一个随机端口号与该客户端建立连接,随后的通信就靠这个端口了。
所以,服务器会打开固定端口(比如80)监听,每来一个客户端连接,就打开一个新端口号创建该连接。由于服务器会有大量来自客户端的连接,但是每个连接都会分配不同的端口号,所以,服务器要给哪个客户端发数据,只要发到分配的端口就行。
但是服务器还需要同时响应多个客户端的请求,所以,每个连接都需要一个新的进程或者新的线程来处理,否则,服务器一次就只能服务一个客户端了。
我们来编写一个简单的服务器程序,它接收客户端连接,把客户端发过来的字符串加上Hello再发回去。
首先,创建一个基于IPv4和TCP协议的Socket:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
然后,我们要绑定监听的地址和端口。服务器可能有多块网卡,可以绑定到某一块网卡的IP地址上,也可以用0.0.0.0绑定到所有的网络地址,还可以用127.0.0.1绑定到本机地址。127.0.0.1是一个特殊的IP地址,表示本机地址,如果绑定到这个地址,客户端必须同时在本机运行才能连接,也就是说,外部的计算机无法连接进来。
端口号需要预先指定。因为我们写的这个服务不是标准服务,所以用9999这个端口号。请注意,小于1024的端口号必须要有管理员权限才能绑定:
# 监听端口:
s.bind(('127.0.0.1', 9999))
紧接着,调用listen()方法开始监听端口,传入的参数指定等待连接的最大数量:
s.listen(5)
print 'Waiting for connection...'
接下来,服务器程序通过一个永久循环来接受来自客户端的连接,accept()会等待并返回一个客户端的连接:
while True:
# 接受一个新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=tcplink, args=(sock, addr))
t.start()
每个连接都必须创建新线程(或进程)来处理,否则,单线程在处理连接的过程中,无法接受其他客户端的连接:
def tcplink(sock, addr):
print 'Accept new connection from %s:%s...' % addr
sock.send('Welcome!')
while True:
data = sock.recv(1024)
time.sleep(1)
if data == 'exit' or not data:
break
sock.send('Hello, %s!' % data)
sock.close()
print 'Connection from %s:%s closed.' % addr
连接建立后,服务器首先发一条欢迎消息,然后等待客户端数据,并加上Hello再发送给客户端。如果客户端发送了exit字符串,就直接关闭连接。
要测试这个服务器程序,我们还需要编写一个客户端程序:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('127.0.0.1', 9999))
# 接收欢迎消息:
print s.recv(1024)
for data in ['Michael', 'Tracy', 'Sarah']:
# 发送数据:
s.send(data)
print s.recv(1024)
s.send('exit')
s.close()
我们需要打开两个命令行窗口,一个运行服务器程序,另一个运行客户端程序,就可以看到效果了:
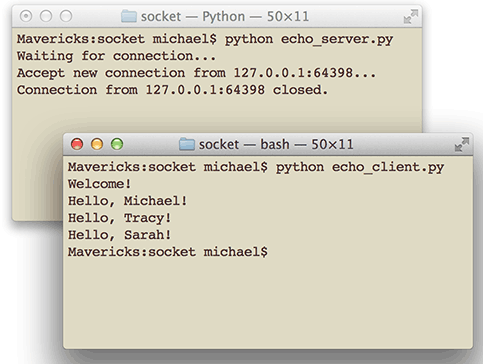
需要注意的是,客户端程序运行完毕就退出了,而服务器程序会永远运行下去,必须按Ctrl+C退出程序。
小结
用TCP协议进行Socket编程在Python中十分简单,对于客户端,要主动连接服务器的IP和指定端口,对于服务器,要首先监听指定端口,然后,对每一个新的连接,创建一个线程或进程来处理。通常,服务器程序会无限运行下去。
同一个端口,被一个Socket绑定了以后,就不能被别的Socket绑定了。
源码参考:https://github.com/michaelliao/learn-python/tree/master/socket
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386832511628f1...
UDP编程
TCP是建立可靠连接,并且通信双方都可以以流的形式发送数据。相对TCP,UDP则是面向无连接的协议。
使用UDP协议时,不需要建立连接,只需要知道对方的IP地址和端口号,就可以直接发数据包。但是,能不能到达就不知道了。
虽然用UDP传输数据不可靠,但它的优点是和TCP比,速度快,对于不要求可靠到达的数据,就可以使用UDP协议。
我们来看看如何通过UDP协议传输数据。和TCP类似,使用UDP的通信双方也分为客户端和服务器。服务器首先需要绑定端口:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定端口:
s.bind(('127.0.0.1', 9999))
创建Socket时,SOCK_DGRAM指定了这个Socket的类型是UDP。绑定端口和TCP一样,但是不需要调用listen()方法,而是直接接收来自任何客户端的数据:
print 'Bind UDP on 9999...'
while True:
# 接收数据:
data, addr = s.recvfrom(1024)
print 'Received from %s:%s.' % addr
s.sendto('Hello, %s!' % data, addr)
recvfrom()方法返回数据和客户端的地址与端口,这样,服务器收到数据后,直接调用sendto()就可以把数据用UDP发给客户端。
注意这里省掉了多线程,因为这个例子很简单。
客户端使用UDP时,首先仍然创建基于UDP的Socket,然后,不需要调用connect(),直接通过sendto()给服务器发数据:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
for data in ['Michael', 'Tracy', 'Sarah']:
# 发送数据:
s.sendto(data, ('127.0.0.1', 9999))
# 接收数据:
print s.recv(1024)
s.close()
从服务器接收数据仍然调用recv()方法。
仍然用两个命令行分别启动服务器和客户端测试,结果如下:
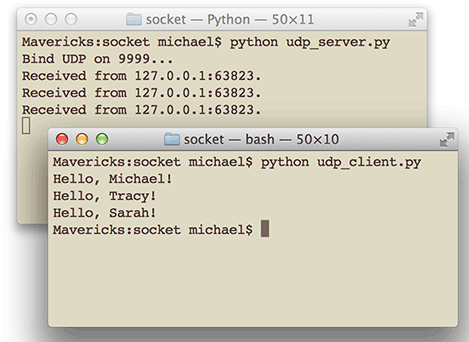
小结
UDP的使用与TCP类似,但是不需要建立连接。此外,服务器绑定UDP端口和TCP端口互不冲突,也就是说,UDP的9999端口与TCP的9999端口可以各自绑定。
源码参考:https://github.com/michaelliao/learn-python/tree/master/socket
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/00138683252644573...
电子邮件
Email的历史比Web还要久远,直到现在,Email也是互联网上应用非常广泛的服务。
几乎所有的编程语言都支持发送和接收电子邮件,但是,先等等,在我们开始编写代码之前,有必要搞清楚电子邮件是如何在互联网上运作的。
我们来看看传统邮件是如何运作的。假设你现在在北京,要给一个香港的朋友发一封信,怎么做呢?
首先你得写好信,装进信封,写上地址,贴上邮票,然后就近找个邮局,把信仍进去。
信件会从就近的小邮局转运到大邮局,再从大邮局往别的城市发,比如先发到天津,再走海运到达香港,也可能走京九线到香港,但是你不用关心具体路线,你只需要知道一件事,就是信件走得很慢,至少要几天时间。
信件到达香港的某个邮局,也不会直接送到朋友的家里,因为邮局的叔叔是很聪明的,他怕你的朋友不在家,一趟一趟地白跑,所以,信件会投递到你的朋友的邮箱里,邮箱可能在公寓的一层,或者家门口,直到你的朋友回家的时候检查邮箱,发现信件后,就可以取到邮件了。
电子邮件的流程基本上也是按上面的方式运作的,只不过速度不是按天算,而是按秒算。
现在我们回到电子邮件,假设我们自己的电子邮件地址是me@163.com,对方的电子邮件地址是friend@sina.com(注意地址都是虚构的哈),现在我们用Outlook或者Foxmail之类的软件写好邮件,填上对方的Email地址,点“发送”,电子邮件就发出去了。这些电子邮件软件被称为MUA:Mail User Agent——邮件用户代理。
Email从MUA发出去,不是直接到达对方电脑,而是发到MTA:Mail Transfer Agent——邮件传输代理,就是那些Email服务提供商,比如网易、新浪等等。由于我们自己的电子邮件是163.com,所以,Email首先被投递到网易提供的MTA,再由网易的MTA发到对方服务商,也就是新浪的MTA。这个过程中间可能还会经过别的MTA,但是我们不关心具体路线,我们只关心速度。
Email到达新浪的MTA后,由于对方使用的是@sina.com的邮箱,因此,新浪的MTA会把Email投递到邮件的最终目的地MDA:Mail Delivery Agent——邮件投递代理。Email到达MDA后,就静静地躺在新浪的某个服务器上,存放在某个文件或特殊的数据库里,我们将这个长期保存邮件的地方称之为电子邮箱。
同普通邮件类似,Email不会直接到达对方的电脑,因为对方电脑不一定开机,开机也不一定联网。对方要取到邮件,必须通过MUA从MDA上把邮件取到自己的电脑上。
所以,一封电子邮件的旅程就是:
发件人 -> MUA -> MTA -> MTA -> 若干个MTA -> MDA <- MUA <- 收件人
有了上述基本概念,要编写程序来发送和接收邮件,本质上就是:
编写MUA把邮件发到MTA;
编写MUA从MDA上收邮件。
发邮件时,MUA和MTA使用的协议就是SMTP:Simple Mail Transfer Protocol,后面的MTA到另一个MTA也是用SMTP协议。
收邮件时,MUA和MDA使用的协议有两种:POP:Post Office Protocol,目前版本是3,俗称POP3;IMAP:Internet Message Access Protocol,目前版本是4,优点是不但能取邮件,还可以直接操作MDA上存储的邮件,比如从收件箱移到垃圾箱,等等。
邮件客户端软件在发邮件时,会让你先配置SMTP服务器,也就是你要发到哪个MTA上。假设你正在使用163的邮箱,你就不能直接发到新浪的MTA上,因为它只服务新浪的用户,所以,你得填163提供的SMTP服务器地址:smtp.163.com,为了证明你是163的用户,SMTP服务器还要求你填写邮箱地址和邮箱口令,这样,MUA才能正常地把Email通过SMTP协议发送到MTA。
类似的,从MDA收邮件时,MDA服务器也要求验证你的邮箱口令,确保不会有人冒充你收取你的邮件,所以,Outlook之类的邮件客户端会要求你填写POP3或IMAP服务器地址、邮箱地址和口令,这样,MUA才能顺利地通过POP或IMAP协议从MDA取到邮件。
在使用Python收发邮件前,请先准备好至少两个电子邮件,如xxx@163.com,xxx@sina.com,xxx@qq.com等,注意两个邮箱不要用同一家邮件服务商。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0013868325601402299d1e941914a21990ac7861ef4bc2d000
SMTP发送邮件
SMTP是发送邮件的协议,Python内置对SMTP的支持,可以发送纯文本邮件、HTML邮件以及带附件的邮件。
Python对SMTP支持有smtplib和email两个模块,email负责构造邮件,smtplib负责发送邮件。
首先,我们来构造一个最简单的纯文本邮件:
from email.mime.text import MIMEText
msg = MIMEText('hello, send by Python...', 'plain', 'utf-8')
注意到构造MIMEText对象时,第一个参数就是邮件正文,第二个参数是MIME的subtype,传入'plain',最终的MIME就是'text/plain',最后一定要用utf-8编码保证多语言兼容性。
然后,通过SMTP发出去:
# 输入Email地址和口令:
from_addr = raw_input('From: ')
password = raw_input('Password: ')
# 输入SMTP服务器地址:
smtp_server = raw_input('SMTP server: ')
# 输入收件人地址:
to_addr = raw_input('To: ')
import smtplib
server = smtplib.SMTP(smtp_server, 25) # SMTP协议默认端口是25
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()
我们用set_debuglevel(1)就可以打印出和SMTP服务器交互的所有信息。SMTP协议就是简单的文本命令和响应。login()方法用来登录SMTP服务器,sendmail()方法就是发邮件,由于可以一次发给多个人,所以传入一个list,邮件正文是一个str,as_string()把MIMEText对象变成str。
如果一切顺利,就可以在收件人信箱中收到我们刚发送的Email:
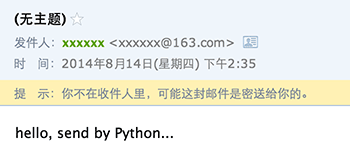
仔细观察,发现如下问题:
- 邮件没有主题;
- 收件人的名字没有显示为友好的名字,比如
Mr Green <green@example.com>; - 明明收到了邮件,却提示不在收件人中。
这是因为邮件主题、如何显示发件人、收件人等信息并不是通过SMTP协议发给MTA,而是包含在发给MTA的文本中的,所以,我们必须把From、To和Subject添加到MIMEText中,才是一封完整的邮件:
# -*- coding: utf-8 -*-
from email import encoders
from email.header import Header
from email.mime.text import MIMEText
from email.utils import parseaddr, formataddr
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr(( \
Header(name, 'utf-8').encode(), \
addr.encode('utf-8') if isinstance(addr, unicode) else addr))
from_addr = raw_input('From: ')
password = raw_input('Password: ')
to_addr = raw_input('To: ')
smtp_server = raw_input('SMTP server: ')
msg = MIMEText('hello, send by Python...', 'plain', 'utf-8')
msg['From'] = _format_addr(u'Python爱好者 <%s>' % from_addr)
msg['To'] = _format_addr(u'管理员 <%s>' % to_addr)
msg['Subject'] = Header(u'来自SMTP的问候……', 'utf-8').encode()
server = smtplib.SMTP(smtp_server, 25)
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()
我们编写了一个函数_format_addr()来格式化一个邮件地址。注意不能简单地传入name <addr@example.com>,因为如果包含中文,需要通过Header对象进行编码。
msg['To']接收的是字符串而不是list,如果有多个邮件地址,用,分隔即可。
再发送一遍邮件,就可以在收件人邮箱中看到正确的标题、发件人和收件人:
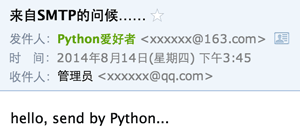
你看到的收件人的名字很可能不是我们传入的管理员,因为很多邮件服务商在显示邮件时,会把收件人名字自动替换为用户注册的名字,但是其他收件人名字的显示不受影响。
如果我们查看Email的原始内容,可以看到如下经过编码的邮件头:
From: =?utf-8?b?UHl0aG9u54ix5aW96ICF?= <xxxxxx@163.com>
To: =?utf-8?b?566h55CG5ZGY?= <xxxxxx@qq.com>
Subject: =?utf-8?b?5p2l6IeqU01UUOeahOmXruWAmeKApuKApg==?=
这就是经过Header对象编码的文本,包含utf-8编码信息和Base64编码的文本。如果我们自己来手动构造这样的编码文本,显然比较复杂。
发送HTML邮件
如果我们要发送HTML邮件,而不是普通的纯文本文件怎么办?方法很简单,在构造MIMEText对象时,把HTML字符串传进去,再把第二个参数由plain变为html就可以了:
msg = MIMEText('<html><body><h1>Hello</h1>' +
'<p>send by <a href="http://www.python.org">Python</a>...</p>' +
'</body></html>', 'html', 'utf-8')
再发送一遍邮件,你将看到以HTML显示的邮件:
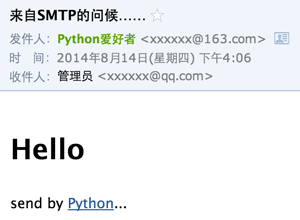
发送附件
如果Email中要加上附件怎么办?带附件的邮件可以看做包含若干部分的邮件:文本和各个附件本身,所以,可以构造一个MIMEMultipart对象代表邮件本身,然后往里面加上一个MIMEText作为邮件正文,再继续往里面加上表示附件的MIMEBase对象即可:
# 邮件对象:
msg = MIMEMultipart()
msg['From'] = _format_addr(u'Python爱好者 <%s>' % from_addr)
msg['To'] = _format_addr(u'管理员 <%s>' % to_addr)
msg['Subject'] = Header(u'来自SMTP的问候……', 'utf-8').encode()
# 邮件正文是MIMEText:
msg.attach(MIMEText('send with file...', 'plain', 'utf-8'))
# 添加附件就是加上一个MIMEBase,从本地读取一个图片:
with open('/Users/michael/Downloads/test.png', 'rb') as f:
# 设置附件的MIME和文件名,这里是png类型:
mime = MIMEBase('image', 'png', filename='test.png')
# 加上必要的头信息:
mime.add_header('Content-Disposition', 'attachment', filename='test.png')
mime.add_header('Content-ID', '<0>')
mime.add_header('X-Attachment-Id', '0')
# 把附件的内容读进来:
mime.set_payload(f.read())
# 用Base64编码:
encoders.encode_base64(mime)
# 添加到MIMEMultipart:
msg.attach(mime)
然后,按正常发送流程把msg(注意类型已变为MIMEMultipart)发送出去,就可以收到如下带附件的邮件:
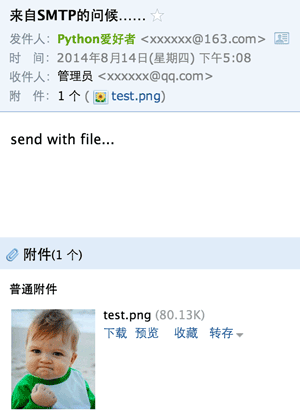
发送图片
如果要把一个图片嵌入到邮件正文中怎么做?直接在HTML邮件中链接图片地址行不行?答案是,大部分邮件服务商都会自动屏蔽带有外链的图片,因为不知道这些链接是否指向恶意网站。
要把图片嵌入到邮件正文中,我们只需按照发送附件的方式,先把邮件作为附件添加进去,然后,在HTML中通过引用src="cid:0"就可以把附件作为图片嵌入了。如果有多个图片,给它们依次编号,然后引用不同的cid:x即可。
把上面代码加入MIMEMultipart的MIMEText从plain改为html,然后在适当的位置引用图片:
msg.attach(MIMEText('<html><body><h1>Hello</h1>' +
'<p><img src="cid:0"></p>' +
'</body></html>', 'html', 'utf-8'))
再次发送,就可以看到图片直接嵌入到邮件正文的效果:
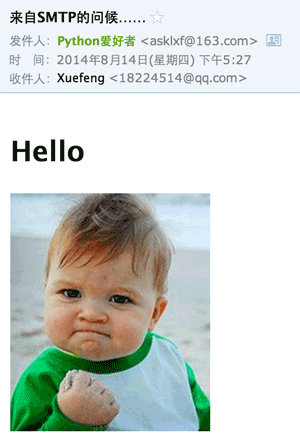
同时支持HTML和Plain格式
如果我们发送HTML邮件,收件人通过浏览器或者Outlook之类的软件是可以正常浏览邮件内容的,但是,如果收件人使用的设备太古老,查看不了HTML邮件怎么办?
办法是在发送HTML的同时再附加一个纯文本,如果收件人无法查看HTML格式的邮件,就可以自动降级查看纯文本邮件。
利用MIMEMultipart就可以组合一个HTML和Plain,要注意指定subtype是alternative:
msg = MIMEMultipart('alternative')
msg['From'] = ...
msg['To'] = ...
msg['Subject'] = ...
msg.attach(MIMEText('hello', 'plain', 'utf-8'))
msg.attach(MIMEText('<html><body><h1>Hello</h1></body></html>', 'html', 'utf-8'))
# 正常发送msg对象...
加密SMTP
使用标准的25端口连接SMTP服务器时,使用的是明文传输,发送邮件的整个过程可能会被窃听。要更安全地发送邮件,可以加密SMTP会话,实际上就是先创建SSL安全连接,然后再使用SMTP协议发送邮件。
某些邮件服务商,例如Gmail,提供的SMTP服务必须要加密传输。我们来看看如何通过Gmail提供的安全SMTP发送邮件。
必须知道,Gmail的SMTP端口是587,因此,修改代码如下:
smtp_server = 'smtp.gmail.com'
smtp_port = 587
server = smtplib.SMTP(smtp_server, smtp_port)
server.starttls()
# 剩下的代码和前面的一模一样:
server.set_debuglevel(1)
...
只需要在创建SMTP对象后,立刻调用starttls()方法,就创建了安全连接。后面的代码和前面的发送邮件代码完全一样。
如果因为网络问题无法连接Gmail的SMTP服务器,请相信我们的代码是没有问题的,你需要对你的网络设置做必要的调整。
小结
使用Python的smtplib发送邮件十分简单,只要掌握了各种邮件类型的构造方法,正确设置好邮件头,就可以顺利发出。
构造一个邮件对象就是一个Messag对象,如果构造一个MIMEText对象,就表示一个文本邮件对象,如果构造一个MIMEImage对象,就表示一个作为附件的图片,要把多个对象组合起来,就用MIMEMultipart对象,而MIMEBase可以表示任何对象。它们的继承关系如下:
Message
+- MIMEBase
+- MIMEMultipart
+- MIMENonMultipart
+- MIMEMessage
+- MIMEText
+- MIMEImage
这种嵌套关系就可以构造出任意复杂的邮件。你可以通过email.mime文档查看它们所在的包以及详细的用法。
源码参考:
https://github.com/michaelliao/learn-python/tree/master/email
POP3收取邮件
SMTP用于发送邮件,如果要收取邮件呢?
收取邮件就是编写一个MUA作为客户端,从MDA把邮件获取到用户的电脑或者手机上。收取邮件最常用的协议是POP协议,目前版本号是3,俗称POP3。
Python内置一个poplib模块,实现了POP3协议,可以直接用来收邮件。
注意到POP3协议收取的不是一个已经可以阅读的邮件本身,而是邮件的原始文本,这和SMTP协议很像,SMTP发送的也是经过编码后的一大段文本。
要把POP3收取的文本变成可以阅读的邮件,还需要用email模块提供的各种类来解析原始文本,变成可阅读的邮件对象。
所以,收取邮件分两步:
第一步:用poplib把邮件的原始文本下载到本地;
第二部:用email解析原始文本,还原为邮件对象。
通过POP3下载邮件
POP3协议本身很简单,以下面的代码为例,我们来获取最新的一封邮件内容:
import poplib
# 输入邮件地址, 口令和POP3服务器地址:
email = raw_input('Email: ')
password = raw_input('Password: ')
pop3_server = raw_input('POP3 server: ')
# 连接到POP3服务器:
server = poplib.POP3(pop3_server)
# 可以打开或关闭调试信息:
# server.set_debuglevel(1)
# 可选:打印POP3服务器的欢迎文字:
print(server.getwelcome())
# 身份认证:
server.user(email)
server.pass_(password)
# stat()返回邮件数量和占用空间:
print('Messages: %s. Size: %s' % server.stat())
# list()返回所有邮件的编号:
resp, mails, octets = server.list()
# 可以查看返回的列表类似['1 82923', '2 2184', ...]
print(mails)
# 获取最新一封邮件, 注意索引号从1开始:
index = len(mails)
resp, lines, octets = server.retr(index)
# lines存储了邮件的原始文本的每一行,
# 可以获得整个邮件的原始文本:
msg_content = '\r\n'.join(lines)
# 稍后解析出邮件:
msg = Parser().parsestr(msg_content)
# 可以根据邮件索引号直接从服务器删除邮件:
# server.dele(index)
# 关闭连接:
server.quit()
用POP3获取邮件其实很简单,要获取所有邮件,只需要循环使用retr()把每一封邮件内容拿到即可。真正麻烦的是把邮件的原始内容解析为可以阅读的邮件对象。
解析邮件
解析邮件的过程和上一节构造邮件正好相反,因此,先导入必要的模块:
import email
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
只需要一行代码就可以把邮件内容解析为Message对象:
msg = Parser().parsestr(msg_content)
但是这个Message对象本身可能是一个MIMEMultipart对象,即包含嵌套的其他MIMEBase对象,嵌套可能还不止一层。
所以我们要递归地打印出Message对象的层次结构:
# indent用于缩进显示:
def print_info(msg, indent=0):
if indent == 0:
# 邮件的From, To, Subject存在于根对象上:
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header=='Subject':
# 需要解码Subject字符串:
value = decode_str(value)
else:
# 需要解码Email地址:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
print('%s%s: %s' % (' ' * indent, header, value))
if (msg.is_multipart()):
# 如果邮件对象是一个MIMEMultipart,
# get_payload()返回list,包含所有的子对象:
parts = msg.get_payload()
for n, part in enumerate(parts):
print('%spart %s' % (' ' * indent, n))
print('%s--------------------' % (' ' * indent))
# 递归打印每一个子对象:
print_info(part, indent + 1)
else:
# 邮件对象不是一个MIMEMultipart,
# 就根据content_type判断:
content_type = msg.get_content_type()
if content_type=='text/plain' or content_type=='text/html':
# 纯文本或HTML内容:
content = msg.get_payload(decode=True)
# 要检测文本编码:
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
print('%sText: %s' % (' ' * indent, content + '...'))
else:
# 不是文本,作为附件处理:
print('%sAttachment: %s' % (' ' * indent, content_type))
邮件的Subject或者Email中包含的名字都是经过编码后的str,要正常显示,就必须decode:
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
decode_header()返回一个list,因为像Cc、Bcc这样的字段可能包含多个邮件地址,所以解析出来的会有多个元素。上面的代码我们偷了个懒,只取了第一个元素。
文本邮件的内容也是str,还需要检测编码,否则,非UTF-8编码的邮件都无法正常显示:
def guess_charset(msg):
# 先从msg对象获取编码:
charset = msg.get_charset()
if charset is None:
# 如果获取不到,再从Content-Type字段获取:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
把上面的代码整理好,我们就可以来试试收取一封邮件。先往自己的邮箱发一封邮件,然后用浏览器登录邮箱,看看邮件收到没,如果收到了,我们就来用Python程序把它收到本地:
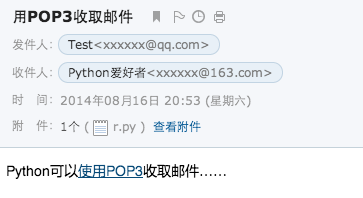
运行程序,结果如下:
+OK Welcome to coremail Mail Pop3 Server (163coms[...])
Messages: 126. Size: 27228317
From: Test <xxxxxx@qq.com>
To: Python爱好者 <xxxxxx@163.com>
Subject: 用POP3收取邮件
part 0
--------------------
part 0
--------------------
Text: Python可以使用POP3收取邮件……...
part 1
--------------------
Text: Python可以<a href="...">使用POP3</a>收取邮件……...
part 1
--------------------
Attachment: application/octet-stream
我们从打印的结构可以看出,这封邮件是一个MIMEMultipart,它包含两部分:第一部分又是一个MIMEMultipart,第二部分是一个附件。而内嵌的MIMEMultipart是一个alternative类型,它包含一个纯文本格式的MIMEText和一个HTML格式的MIMEText。
小结
用Python的poplib模块收取邮件分两步:第一步是用POP3协议把邮件获取到本地,第二步是用email模块把原始邮件解析为Message对象,然后,用适当的形式把邮件内容展示给用户即可。
源码参考:
https://github.com/michaelliao/learn-python/tree/master/email
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/00140824481921543...
访问数据库
程序运行的时候,数据都是在内存中的。当程序终止的时候,通常都需要将数据保存到磁盘上,无论是保存到本地磁盘,还是通过网络保存到服务器上,最终都会将数据写入磁盘文件。
而如何定义数据的存储格式就是一个大问题。如果我们自己来定义存储格式,比如保存一个班级所有学生的成绩单:
| 名字 | 成绩 |
|---|---|
| Michael | 99 |
| Bob | 85 |
| Bart | 59 |
| Lisa | 87 |
你可以用一个文本文件保存,一行保存一个学生,用,隔开:
Michael,99
Bob,85
Bart,59
Lisa,87
你还可以用JSON格式保存,也是文本文件:
[
{"name":"Michael","score":99},
{"name":"Bob","score":85},
{"name":"Bart","score":59},
{"name":"Lisa","score":87}
]
你还可以定义各种保存格式,但是问题来了:
存储和读取需要自己实现,JSON还是标准,自己定义的格式就各式各样了;
不能做快速查询,只有把数据全部读到内存中才能自己遍历,但有时候数据的大小远远超过了内存(比如蓝光电影,40GB的数据),根本无法全部读入内存。
为了便于程序保存和读取数据,而且,能直接通过条件快速查询到指定的数据,就出现了数据库(Database)这种专门用于集中存储和查询的软件。
数据库软件诞生的历史非常久远,早在1950年数据库就诞生了。经历了网状数据库,层次数据库,我们现在广泛使用的关系数据库是20世纪70年代基于关系模型的基础上诞生的。
关系模型有一套复杂的数学理论,但是从概念上是十分容易理解的。举个学校的例子:
假设某个XX省YY市ZZ县第一实验小学有3个年级,要表示出这3个年级,可以在Excel中用一个表格画出来:

每个年级又有若干个班级,要把所有班级表示出来,可以在Excel中再画一个表格:
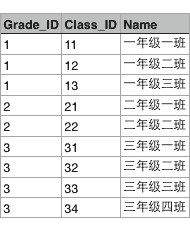
这两个表格有个映射关系,就是根据Grade_ID可以在班级表中查找到对应的所有班级:
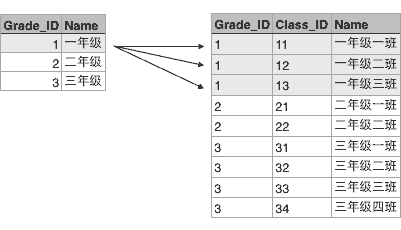
也就是Grade表的每一行对应Class表的多行,在关系数据库中,这种基于表(Table)的一对多的关系就是关系数据库的基础。
根据某个年级的ID就可以查找所有班级的行,这种查询语句在关系数据库中称为SQL语句,可以写成:
SELECT * FROM classes WHERE grade_id = '1';
结果也是一个表:
---------+----------+----------
grade_id | class_id | name
---------+----------+----------
1 | 11 | 一年级一班
---------+----------+----------
1 | 12 | 一年级二班
---------+----------+----------
1 | 13 | 一年级三班
---------+----------+----------
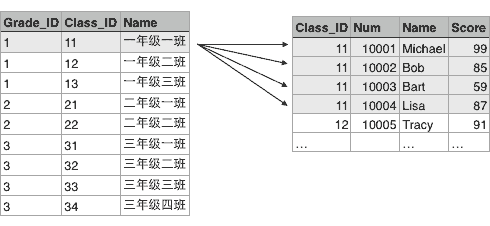
类似的,Class表的一行记录又可以关联到Student表的多行记录:
由于本教程不涉及到关系数据库的详细内容,如果你想从零学习关系数据库和基本的SQL语句,推荐Coursera课程:
英文:https://www.coursera.org/course/db
中文:http://c.open.163.com/coursera/courseIntro.htm?cid=12
NoSQL
你也许还听说过NoSQL数据库,很多NoSQL宣传其速度和规模远远超过关系数据库,所以很多同学觉得有了NoSQL是否就不需要SQL了呢?千万不要被他们忽悠了,连SQL都不明白怎么可能搞明白NoSQL呢?
数据库类别
既然我们要使用关系数据库,就必须选择一个关系数据库。目前广泛使用的关系数据库也就这么几种:
付费的商用数据库:
Oracle,典型的高富帅;
SQL Server,微软自家产品,Windows定制专款;
DB2,IBM的产品,听起来挺高端;
Sybase,曾经跟微软是好基友,后来关系破裂,现在家境惨淡。
这些数据库都是不开源而且付费的,最大的好处是花了钱出了问题可以找厂家解决,不过在Web的世界里,常常需要部署成千上万的数据库服务器,当然不能把大把大把的银子扔给厂家,所以,无论是Google、Facebook,还是国内的BAT,无一例外都选择了免费的开源数据库:
MySQL,大家都在用,一般错不了;
PostgreSQL,学术气息有点重,其实挺不错,但知名度没有MySQL高;
sqlite,嵌入式数据库,适合桌面和移动应用。
作为Python开发工程师,选择哪个免费数据库呢?当然是MySQL。因为MySQL普及率最高,出了错,可以很容易找到解决方法。而且,围绕MySQL有一大堆监控和运维的工具,安装和使用很方便。
为了能继续后面的学习,你需要从MySQL官方网站下载并安装MySQL Community Server 5.6,这个版本是免费的,其他高级版本是要收钱的(请放心,收钱的功能我们用不上)。
来自 http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0013868327777137a...
使用SQLite
SQLite是一种嵌入式数据库,它的数据库就是一个文件。由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成。
Python就内置了SQLite3,所以,在Python中使用SQLite,不需要安装任何东西,直接使用。
在使用SQLite前,我们先要搞清楚几个概念:
表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,比如学生的表,班级的表,学校的表,等等。表和表之间通过外键关联。
要操作关系数据库,首先需要连接到数据库,一个数据库连接称为Connection;
连接到数据库后,需要打开游标,称之为Cursor,通过Cursor执行SQL语句,然后,获得执行结果。
Python定义了一套操作数据库的API接口,任何数据库要连接到Python,只需要提供符合Python标准的数据库驱动即可。
由于SQLite的驱动内置在Python标准库中,所以我们可以直接来操作SQLite数据库。
我们在Python交互式命令行实践一下:
# 导入SQLite驱动:
>>> import sqlite3
# 连接到SQLite数据库
# 数据库文件是test.db
# 如果文件不存在,会自动在当前目录创建:
>>> conn = sqlite3.connect('test.db')
# 创建一个Cursor:
>>> cursor = conn.cursor()
# 执行一条SQL语句,创建user表:
>>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
<sqlite3.Cursor object at 0x10f8aa260>
# 继续执行一条SQL语句,插入一条记录:
>>> cursor.execute('insert into user (id, name) values (\'1\', \'Michael\')')
<sqlite3.Cursor object at 0x10f8aa260>
# 通过rowcount获得插入的行数:
>>> cursor.rowcount
1
# 关闭Cursor:
>>> cursor.close()
# 提交事务:
>>> conn.commit()
# 关闭Connection:
>>> conn.close()
我们再试试查询记录:
>>> conn = sqlite3.connect('test.db')
>>> cursor = conn.cursor()
# 执行查询语句:
>>> cursor.execute('select * from user where id=?', '1')
<sqlite3.Cursor object at 0x10f8aa340>
# 获得查询结果集:
>>> values = cursor.fetchall()
>>> values
[(u'1', u'Michael')]
>>> cursor.close()
>>> conn.close()
使用Python的DB-API时,只要搞清楚Connection和Cursor对象,打开后一定记得关闭,就可以放心地使用。
使用Cursor对象执行insert,update,delete语句时,执行结果由rowcount返回影响的行数,就可以拿到执行结果。
使用Cursor对象执行select语句时,通过featchall()可以拿到结果集。结果集是一个list,每个元素都是一个tuple,对应一行记录。
如果SQL语句带有参数,那么需要把参数按照位置传递给execute()方法,有几个?占位符就必须对应几个参数,例如:
cursor.execute('select * from user where id=?', '1')
SQLite支持常见的标准SQL语句以及几种常见的数据类型。具体文档请参阅SQLite官方网站。
小结
在Python中操作数据库时,要先导入数据库对应的驱动,然后,通过Connection对象和Cursor对象操作数据。
要确保打开的Connection对象和Cursor对象都正确地被关闭,否则,资源就会泄露。
如何才能确保出错的情况下也关闭掉Connection对象和Cursor对象呢?请回忆try...catch...finally...的用法。
使用MySQL
MySQL是Web世界中使用最广泛的数据库服务器。SQLite的特点是轻量级、可嵌入,但不能承受高并发访问,适合桌面和移动应用。而MySQL是为服务器端设计的数据库,能承受高并发访问,同时占用的内存也远远大于SQLite。
此外,MySQL内部有多种数据库引擎,最常用的引擎是支持数据库事务的InnoDB。
安装MySQL
可以直接从MySQL官方网站下载最新的Community Server 5.6.x版本。MySQL是跨平台的,选择对应的平台下载安装文件,安装即可。
安装时,MySQL会提示输入root用户的口令,请务必记清楚。如果怕记不住,就把口令设置为password。
在Windows上,安装时请选择UTF-8编码,以便正确地处理中文。
在Mac或Linux上,需要编辑MySQL的配置文件,把数据库默认的编码全部改为UTF-8。MySQL的配置文件默认存放在/etc/my.cnf或者/etc/mysql/my.cnf:
[client]
default-character-set = utf8
[mysqld]
default-storage-engine = INNODB
character-set-server = utf8
collation-server = utf8_general_ci
重启MySQL后,可以通过MySQL的客户端命令行检查编码:
$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor...
...
mysql> show variables like '%char%';
+--------------------------+--------------------------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql-5.1.65-osx10.6-x86_64/share/charsets/ |
+--------------------------+--------------------------------------------------------+
8 rows in set (0.00 sec)
看到utf8字样就表示编码设置正确。
安装MySQL驱动
应该可以到 http://dev.mysql.com/downloads/connector/python/2.0.html (mysql的官网)上下下面这个肯定可以 MySQL-python-1.2.3.win-amd64-py2.7.exe
( http://www.codegood.com/archives/129 )google 下 "MySQL-python" "MySQL-python download"
"mysql-connector-python" "mysql-connector-python download"
会发现很多有用的的东西
由于MySQL服务器以独立的进程运行,并通过网络对外服务,所以,需要支持Python的MySQL驱动来连接到MySQL服务器。
目前,有两个MySQL驱动:
mysql-connector-python:是MySQL官方的纯Python驱动;
MySQL-python:是封装了MySQL C驱动的Python驱动。
可以把两个都装上,使用的时候再决定用哪个:
$ easy_install mysql-connector-python
$ easy_install MySQL-python
我们以mysql-connector-python为例,演示如何连接到MySQL服务器的test数据库:
# 导入MySQL驱动:
>>> import mysql.connector
# 注意把password设为你的root口令:
>>> conn = mysql.connector.connect(user='root', password='password', database='test', use_unicode=True)
>>> cursor = conn.cursor()
# 创建user表:
>>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
# 插入一行记录,注意MySQL的占位符是%s:
>>> cursor.execute('insert into user (id, name) values (%s, %s)', ['1', 'Michael'])
>>> cursor.rowcount
1
# 提交事务:
>>> conn.commit()
>>> cursor.close()
# 运行查询:
>>> cursor = conn.cursor()
>>> cursor.execute('select * from user where id = %s', '1')
>>> values = cursor.fetchall()
>>> values
[(u'1', u'Michael')]
# 关闭Cursor和Connection:
>>> cursor.close()
True
>>> conn.close()
由于Python的DB-API定义都是通用的,所以,操作MySQL的数据库代码和SQLite类似。
小结
MySQL的SQL占位符是
%s;通常我们在连接MySQL时传入
use_unicode=True,让MySQL的DB-API始终返回Unicode。
使用SQLAlchemy
数据库表是一个二维表,包含多行多列。把一个表的内容用Python的数据结构表示出来的话,可以用一个list表示多行,list的每一个元素是tuple,表示一行记录,比如,包含id和name的user表:
[
('1', 'Michael'),
('2', 'Bob'),
('3', 'Adam')
]
Python的DB-API返回的数据结构就是像上面这样表示的。
但是用tuple表示一行很难看出表的结构。如果把一个tuple用class实例来表示,就可以更容易地看出表的结构来:
class User(object):
def __init__(self, id, name):
self.id = id
self.name = name
[
User('1', 'Michael'),
User('2', 'Bob'),
User('3', 'Adam')
]
这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?
但是由谁来做这个转换呢?所以ORM框架应运而生。
在Python中,最有名的ORM框架是SQLAlchemy。我们来看看SQLAlchemy的用法。
首先通过easy_install或者pip安装SQLAlchemy:
$ easy_install sqlalchemy
然后,利用上次我们在MySQL的test数据库中创建的user表,用SQLAlchemy来试试:
第一步,导入SQLAlchemy,并初始化DBSession:
# 导入:
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类:
Base = declarative_base()
# 定义User对象:
class User(Base):
# 表的名字:
__tablename__ = 'user'
# 表的结构:
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 初始化数据库连接:
engine = create_engine('mysql+mysqlconnector://root:password@localhost:3306/test')
# 创建DBSession类型:
DBSession = sessionmaker(bind=engine)
以上代码完成SQLAlchemy的初始化和具体每个表的class定义。如果有多个表,就继续定义其他class,例如School:
class School(Base):
__tablename__ = 'school'
id = ...
name = ...
create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
你只需要根据需要替换掉用户名、口令等信息即可。
下面,我们看看如何向数据库表中添加一行记录。
由于有了ORM,我们向数据库表中添加一行记录,可以视为添加一个User对象:
# 创建session对象:
session = DBSession()
# 创建新User对象:
new_user = User(id='5', name='Bob')
# 添加到session:
session.add(new_user)
# 提交即保存到数据库:
session.commit()
# 关闭session:
session.close()
可见,关键是获取session,然后把对象添加到session,最后提交并关闭。Session对象可视为当前数据库连接。
如何从数据库表中查询数据呢?有了ORM,查询出来的可以不再是tuple,而是User对象。SQLAlchemy提供的查询接口如下:
# 创建Session:
session = DBSession()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
user = session.query(User).filter(User.id=='5').one()
# 打印类型和对象的name属性:
print 'type:', type(user)
print 'name:', user.name
# 关闭Session:
session.close()
运行结果如下:
type: <class '__main__.User'>
name: Bob
可见,ORM就是把数据库表的行与相应的对象建立关联,互相转换。
由于关系数据库的多个表还可以用外键实现一对多、多对多等关联,相应地,ORM框架也可以提供两个对象之间的一对多、多对多等功能。
例如,如果一个User拥有多个Book,就可以定义一对多关系如下:
class User(Base):
__tablename__ = 'user'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 一对多:
books = relationship('Book')
class Book(Base):
__tablename__ = 'book'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# “多”的一方的book表是通过外键关联到user表的:
user_id = Column(String(20), ForeignKey('user.id'))
当我们查询一个User对象时,该对象的books属性将返回一个包含若干个Book对象的list。
小结
ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换。
正确使用ORM的前提是了解关系数据库的原理。
使用SQLAlchemy
数据库表是一个二维表,包含多行多列。把一个表的内容用Python的数据结构表示出来的话,可以用一个list表示多行,list的每一个元素是tuple,表示一行记录,比如,包含id和name的user表:
[
('1', 'Michael'),
('2', 'Bob'),
('3', 'Adam')
]
Python的DB-API返回的数据结构就是像上面这样表示的。
但是用tuple表示一行很难看出表的结构。如果把一个tuple用class实例来表示,就可以更容易地看出表的结构来:
class User(object):
def __init__(self, id, name):
self.id = id
self.name = name
[
User('1', 'Michael'),
User('2', 'Bob'),
User('3', 'Adam')
]
这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?
但是由谁来做这个转换呢?所以ORM框架应运而生。
在Python中,最有名的ORM框架是SQLAlchemy。我们来看看SQLAlchemy的用法。
首先通过easy_install或者pip安装SQLAlchemy:
$ easy_install sqlalchemy
然后,利用上次我们在MySQL的test数据库中创建的user表,用SQLAlchemy来试试:
第一步,导入SQLAlchemy,并初始化DBSession:
# 导入:
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类:
Base = declarative_base()
# 定义User对象:
class User(Base):
# 表的名字:
__tablename__ = 'user'
# 表的结构:
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 初始化数据库连接:
engine = create_engine('mysql+mysqlconnector://root:password@localhost:3306/test')
# 创建DBSession类型:
DBSession = sessionmaker(bind=engine)
以上代码完成SQLAlchemy的初始化和具体每个表的class定义。如果有多个表,就继续定义其他class,例如School:
class School(Base):
__tablename__ = 'school'
id = ...
name = ...
create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
你只需要根据需要替换掉用户名、口令等信息即可。
下面,我们看看如何向数据库表中添加一行记录。
由于有了ORM,我们向数据库表中添加一行记录,可以视为添加一个User对象:
# 创建session对象:
session = DBSession()
# 创建新User对象:
new_user = User(id='5', name='Bob')
# 添加到session:
session.add(new_user)
# 提交即保存到数据库:
session.commit()
# 关闭session:
session.close()
可见,关键是获取session,然后把对象添加到session,最后提交并关闭。Session对象可视为当前数据库连接。
如何从数据库表中查询数据呢?有了ORM,查询出来的可以不再是tuple,而是User对象。SQLAlchemy提供的查询接口如下:
# 创建Session:
session = DBSession()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
user = session.query(User).filter(User.id=='5').one()
# 打印类型和对象的name属性:
print 'type:', type(user)
print 'name:', user.name
# 关闭Session:
session.close()
运行结果如下:
type: <class '__main__.User'>
name: Bob
可见,ORM就是把数据库表的行与相应的对象建立关联,互相转换。
由于关系数据库的多个表还可以用外键实现一对多、多对多等关联,相应地,ORM框架也可以提供两个对象之间的一对多、多对多等功能。
例如,如果一个User拥有多个Book,就可以定义一对多关系如下:
class User(Base):
__tablename__ = 'user'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 一对多:
books = relationship('Book')
class Book(Base):
__tablename__ = 'book'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# “多”的一方的book表是通过外键关联到user表的:
user_id = Column(String(20), ForeignKey('user.id'))
当我们查询一个User对象时,该对象的books属性将返回一个包含若干个Book对象的list。
小结
ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换。
正确使用ORM的前提是了解关系数据库的原理。
Web开发
最早的软件都是运行在大型机上的,软件使用者通过“哑终端”登陆到大型机上去运行软件。后来随着PC机的兴起,软件开始主要运行在桌面上,而数据库这样的软件运行在服务器端,这种Client/Server模式简称CS架构。
随着互联网的兴起,人们发现,CS架构不适合Web,最大的原因是Web应用程序的修改和升级非常迅速,而CS架构需要每个客户端逐个升级桌面App,因此,Browser/Server模式开始流行,简称BS架构。
在BS架构下,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web页面,并把Web页面展示给用户即可。
当然,Web页面也具有极强的交互性。由于Web页面是用HTML编写的,而HTML具备超强的表现力,并且,服务器端升级后,客户端无需任何部署就可以使用到新的版本,因此,BS架构迅速流行起来。
今天,除了重量级的软件如Office,Photoshop等,大部分软件都以Web形式提供。比如,新浪提供的新闻、博客、微博等服务,均是Web应用。
Web应用开发可以说是目前软件开发中最重要的部分。Web开发也经历了好几个阶段:
静态Web页面:由文本编辑器直接编辑并生成静态的HTML页面,如果要修改Web页面的内容,就需要再次编辑HTML源文件,早期的互联网Web页面就是静态的;
CGI:由于静态Web页面无法与用户交互,比如用户填写了一个注册表单,静态Web页面就无法处理。要处理用户发送的动态数据,出现了Common Gateway Interface,简称CGI,用C/C++编写。
ASP/JSP/PHP:由于Web应用特点是修改频繁,用C/C++这样的低级语言非常不适合Web开发,而脚本语言由于开发效率高,与HTML结合紧密,因此,迅速取代了CGI模式。ASP是微软推出的用VBScript脚本编程的Web开发技术,而JSP用Java来编写脚本,PHP本身则是开源的脚本语言。
MVC:为了解决直接用脚本语言嵌入HTML导致的可维护性差的问题,Web应用也引入了Model-View-Controller的模式,来简化Web开发。ASP发展为ASP.Net,JSP和PHP也有一大堆MVC框架。
目前,Web开发技术仍在快速发展中,异步开发、新的MVVM前端技术层出不穷。
Python的诞生历史比Web还要早,由于Python是一种解释型的脚本语言,开发效率高,所以非常适合用来做Web开发。
Python有上百种Web开发框架,有很多成熟的模板技术,选择Python开发Web应用,不但开发效率高,而且运行速度快。
本章我们会详细讨论Python Web开发技术。
HTTP协议简介
在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来。而浏览器和服务器之间的传输协议是HTTP,所以:
HTML是一种用来定义网页的文本,会HTML,就可以编写网页;
HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信。
在举例子之前,我们需要安装Google的Chrome浏览器。
为什么要使用Chrome浏览器而不是IE呢?因为IE实在是太慢了,并且,IE对于开发和调试Web应用程序完全是一点用也没有。
我们需要在浏览器很方便地调试我们的Web应用,而Chrome提供了一套完整地调试工具,非常适合Web开发。
安装好Chrome浏览器后,打开Chrome,在菜单中选择“视图”,“开发者”,“开发者工具”,就可以显示开发者工具:
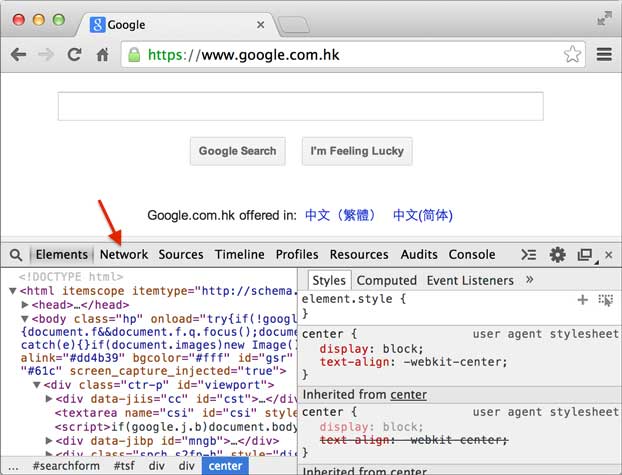
Elements显示网页的结构,Network显示浏览器和服务器的通信。我们点Network,确保第一个小红灯亮着,Chrome就会记录所有浏览器和服务器之间的通信:
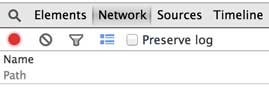
当我们在地址栏输入www.sina.com.cn时,浏览器将显示新浪的首页。在这个过程中,浏览器都干了哪些事情呢?通过Network的记录,我们就可以知道。在Network中,定位到第一条记录,点击,右侧将显示Request Headers,点击右侧的view source,我们就可以看到浏览器发给新浪服务器的请求:
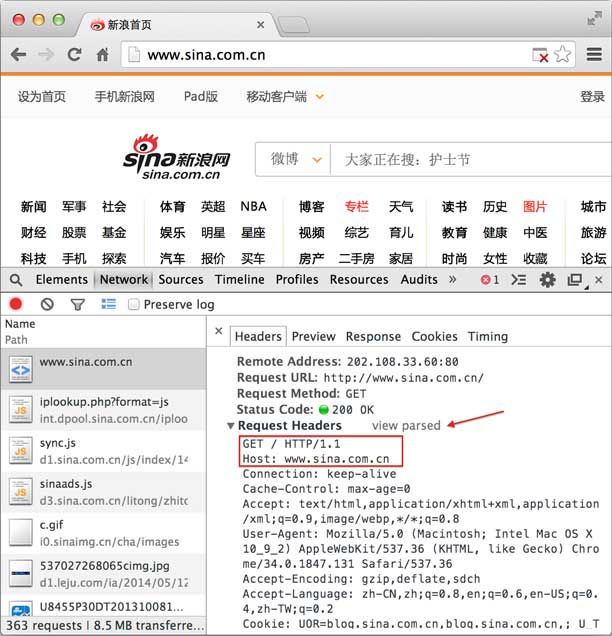
最主要的头两行分析如下,第一行:
GET / HTTP/1.1
GET表示一个获取请求,将从浏览器获得数据,/表示URL的路径,URL总是以/开头,/就表示首页,最后的HTTP/1.1指示采用的HTTP协议版本是1.1。
从第二行开始,每一行都类似于Xxx: abcdefg:
Host: www.sina.com.cn
表示请求的域名是www.sina.com.cn。如果一台服务器有多个网站,服务器就需要通过Host来区分浏览器请求的是哪个网站。
继续往下找到Response Headers,点击view source,显示服务器返回的原始响应数据:
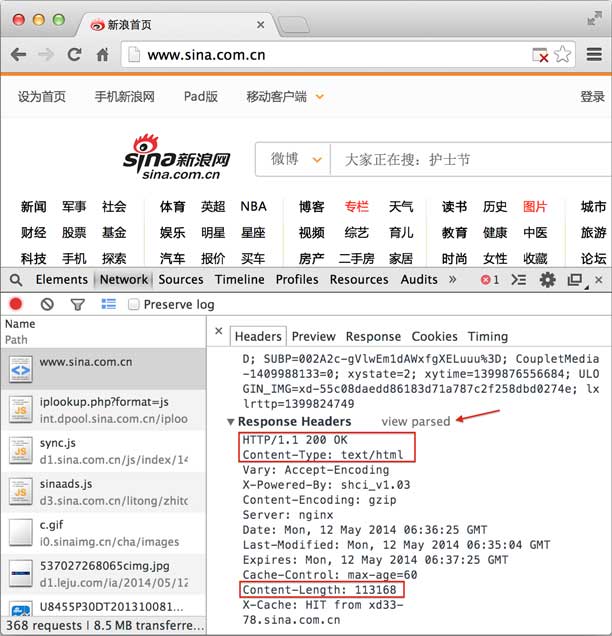
HTTP响应分为Header和Body两部分(Body是可选项),我们在Network中看到的Header最重要的几行如下:
200 OK
200表示一个成功的响应,后面的OK是说明。失败的响应有404 Not Found:网页不存在,500 Internal Server Error:服务器内部出错,等等。
Content-Type: text/html
Content-Type指示响应的内容,这里是text/html表示HTML网页。请注意,浏览器就是依靠Content-Type来判断响应的内容是网页还是图片,是视频还是音乐。浏览器并不靠URL来判断响应的内容,所以,即使URL是http://example.com/abc.jpg,它也不一定就是图片。
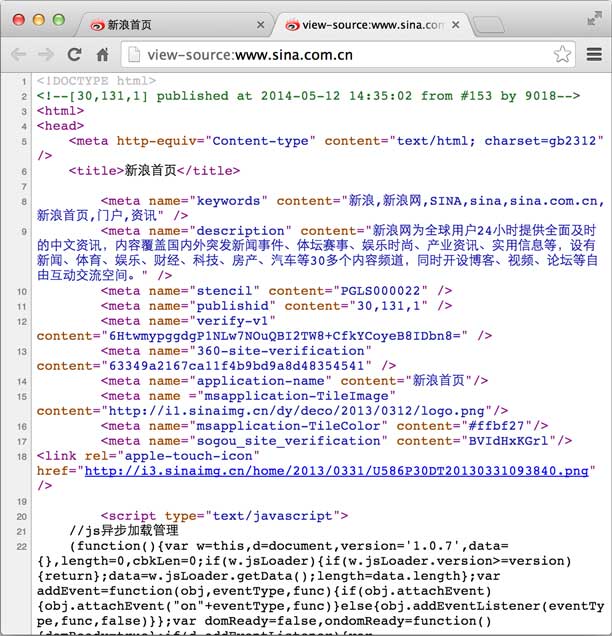
HTTP响应的Body就是HTML源码,我们在菜单栏选择“视图”,“开发者”,“查看网页源码”就可以在浏览器中直接查看HTML源码:
当浏览器读取到新浪首页的HTML源码后,它会解析HTML,显示页面,然后,根据HTML里面的各种链接,再发送HTTP请求给新浪服务器,拿到相应的图片、视频、Flash、JavaScript脚本、CSS等各种资源,最终显示出一个完整的页面。所以我们在Network下面能看到很多额外的HTTP请求。
HTTP请求
跟踪了新浪的首页,我们来总结一下HTTP请求的流程:
步骤1:浏览器首先向服务器发送HTTP请求,请求包括:
方法:GET还是POST,GET仅请求资源,POST会附带用户数据;
路径:/full/url/path;
域名:由Host头指定:Host: www.sina.com.cn
以及其他相关的Header;
如果是POST,那么请求还包括一个Body,包含用户数据。
步骤2:服务器向浏览器返回HTTP响应,响应包括:
响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误;
响应类型:由Content-Type指定;
以及其他相关的Header;
通常服务器的HTTP响应会携带内容,也就是有一个Body,包含响应的内容,网页的HTML源码就在Body中。
步骤3:如果浏览器还需要继续向服务器请求其他资源,比如图片,就再次发出HTTP请求,重复步骤1、2。
Web采用的HTTP协议采用了非常简单的请求-响应模式,从而大大简化了开发。当我们编写一个页面时,我们只需要在HTTP请求中把HTML发送出去,不需要考虑如何附带图片、视频等,浏览器如果需要请求图片和视频,它会发送另一个HTTP请求,因此,一个HTTP请求只处理一个资源。
HTTP协议同时具备极强的扩展性,虽然浏览器请求的是http://www.sina.com.cn/的首页,但是新浪在HTML中可以链入其他服务器的资源,比如<img src="http://i1.sinaimg.cn/home/2013/1008/U8455P30DT20131008135420.png">,从而将请求压力分散到各个服务器上,并且,一个站点可以链接到其他站点,无数个站点互相链接起来,就形成了World Wide Web,简称WWW。
HTTP格式
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。
HTTP协议是一种文本协议,所以,它的格式也非常简单。HTTP GET请求的格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
每个Header一行一个,换行符是\r\n。
HTTP POST请求的格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
当遇到连续两个\r\n时,Header部分结束,后面的数据全部是Body。
HTTP响应的格式:
200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
HTTP响应如果包含body,也是通过\r\n\r\n来分隔的。请再次注意,Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。
要详细了解HTTP协议,推荐“HTTP: The Definitive Guide”一书,非常不错,有中文译本:
HTML简介
网页就是HTML?这么理解大概没错。因为网页中不但包含文字,还有图片、视频、Flash小游戏,有复杂的排版、动画效果,所以,HTML定义了一套语法规则,来告诉浏览器如何把一个丰富多彩的页面显示出来。
HTML长什么样?上次我们看了新浪首页的HTML源码,如果仔细数数,竟然有6000多行!
所以,学HTML,就不要指望从新浪入手了。我们来看看最简单的HTML长什么样:
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>Hello, world!</h1>
</body>
</html>
可以用文本编辑器编写HTML,然后保存为hello.html,双击或者把文件拖到浏览器中,就可以看到效果:
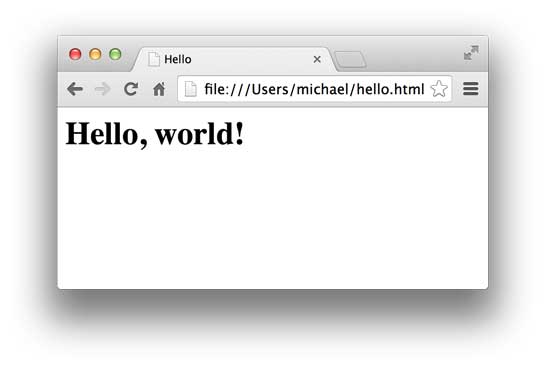
HTML文档就是一系列的Tag组成,最外层的Tag是<html>。规范的HTML也包含<head>...</head>和<body>...</body>(注意不要和HTTP的Header、Body搞混了),由于HTML是富文档模型,所以,还有一系列的Tag用来表示链接、图片、表格、表单等等。
CSS简介
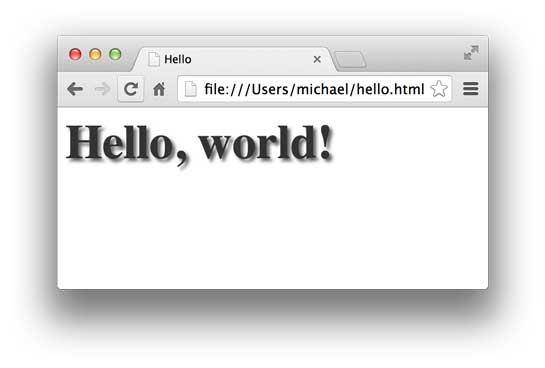
CSS是Cascading Style Sheets(层叠样式表)的简称,CSS用来控制HTML里的所有元素如何展现,比如,给标题元素<h1>加一个样式,变成48号字体,灰色,带阴影:
<html>
<head>
<title>Hello</title>
<style>
h1 {
color: #333333;
font-size: 48px;
text-shadow: 3px 3px 3px #666666;
}
</style>
</head>
<body>
<h1>Hello, world!</h1>
</body>
</html>
效果如下:
JavaScript简介
JavaScript虽然名称有个Java,但它和Java真的一点关系没有。JavaScript是为了让HTML具有交互性而作为脚本语言添加的,JavaScript既可以内嵌到HTML中,也可以从外部链接到HTML中。如果我们希望当用户点击标题时把标题变成红色,就必须通过JavaScript来实现:
<html>
<head>
<title>Hello</title>
<style>
h1 {
color: #333333;
font-size: 48px;
text-shadow: 3px 3px 3px #666666;
}
</style>
<script>
function change() {
document.getElementsByTagName('h1')[0].style.color = '#ff0000';
}
</script>
</head>
<body>
<h1 onclick="change()">Hello, world!</h1>
</body>
</html>
效果如下:
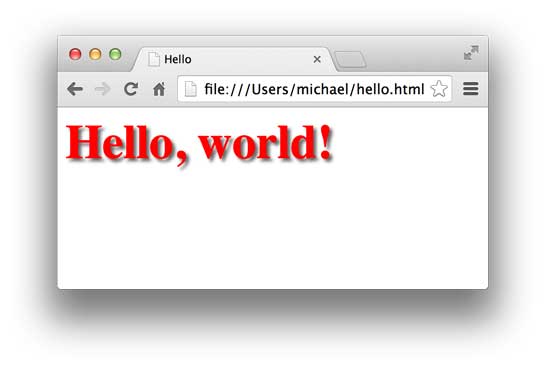
小结
如果要学习Web开发,首先要对HTML、CSS和JavaScript作一定的了解。HTML定义了页面的内容,CSS来控制页面元素的样式,而JavaScript负责页面的交互逻辑。
讲解HTML、CSS和JavaScript就可以写3本书,对于优秀的Web开发人员来说,精通HTML、CSS和JavaScript是必须的,这里推荐一个在线学习网站w3schools:
以及一个对应的中文版本:
当我们用Python或者其他语言开发Web应用时,我们就是要在服务器端动态创建出HTML,这样,浏览器就会向不同的用户显示出不同的Web页面。
WSGI接口
了解了HTTP协议和HTML文档,我们其实就明白了一个Web应用的本质就是:
浏览器发送一个HTTP请求;
服务器收到请求,生成一个HTML文档;
服务器把HTML文档作为HTTP响应的Body发送给浏览器;
浏览器收到HTTP响应,从HTTP Body取出HTML文档并显示。
所以,最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。Apache、Nginx、Lighttpd等这些常见的静态服务器就是干这件事情的。
如果要动态生成HTML,就需要把上述步骤自己来实现。不过,接受HTTP请求、解析HTTP请求、发送HTTP响应都是苦力活,如果我们自己来写这些底层代码,还没开始写动态HTML呢,就得花个把月去读HTTP规范。
正确的做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。
这个接口就是WSGI:Web Server Gateway Interface。
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello, web!”:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return '<h1>Hello, web!</h1>'
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
environ:一个包含所有HTTP请求信息的
dict对象;start_response:一个发送HTTP响应的函数。
在application()函数中,调用:
start_response('200 OK', [('Content-Type', 'text/html')])
就发送了HTTP响应的Header,注意Header只能发送一次,也就是只能调用一次start_response()函数。start_response()函数接收两个参数,一个是HTTP响应码,一个是一组list表示的HTTP Header,每个Header用一个包含两个str的tuple表示。
通常情况下,都应该把Content-Type头发送给浏览器。其他很多常用的HTTP Header也应该发送。
然后,函数的返回值'<h1>Hello, web!</h1>'将作为HTTP响应的Body发送给浏览器。
有了WSGI,我们关心的就是如何从environ这个dict对象拿到HTTP请求信息,然后构造HTML,通过start_response()发送Header,最后返回Body。
整个application()函数本身没有涉及到任何解析HTTP的部分,也就是说,底层代码不需要我们自己编写,我们只负责在更高层次上考虑如何响应请求就可以了。
不过,等等,这个application()函数怎么调用?如果我们自己调用,两个参数environ和start_response我们没法提供,返回的str也没法发给浏览器。
所以application()函数必须由WSGI服务器来调用。有很多符合WSGI规范的服务器,我们可以挑选一个来用。但是现在,我们只想尽快测试一下我们编写的application()函数真的可以把HTML输出到浏览器,所以,要赶紧找一个最简单的WSGI服务器,把我们的Web应用程序跑起来。
好消息是Python内置了一个WSGI服务器,这个模块叫wsgiref,它是用纯Python编写的WSGI服务器的参考实现。所谓“参考实现”是指该实现完全符合WSGI标准,但是不考虑任何运行效率,仅供开发和测试使用。
运行WSGI服务
我们先编写hello.py,实现Web应用程序的WSGI处理函数:
# hello.py
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return '<h1>Hello, web!</h1>'
然后,再编写一个server.py,负责启动WSGI服务器,加载application()函数:
# server.py
# 从wsgiref模块导入:
from wsgiref.simple_server import make_server
# 导入我们自己编写的application函数:
from hello import application
# 创建一个服务器,IP地址为空,端口是8000,处理函数是application:
httpd = make_server('', 8000, application)
print "Serving HTTP on port 8000..."
# 开始监听HTTP请求:
httpd.serve_forever()
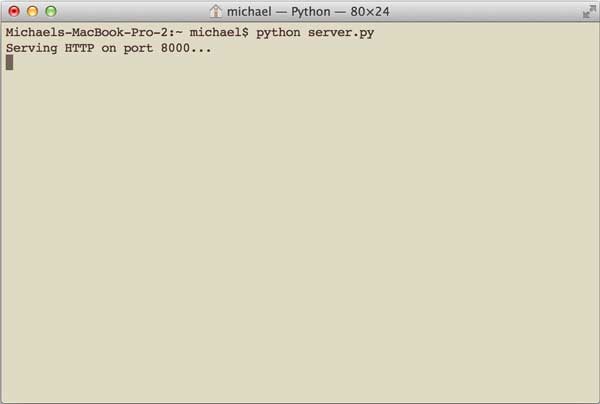
确保以上两个文件在同一个目录下,然后在命令行输入python server.py来启动WSGI服务器:
注意:如果8000端口已被其他程序占用,启动将失败,请修改成其他端口。
启动成功后,打开浏览器,输入http://localhost:8000/,就可以看到结果了:
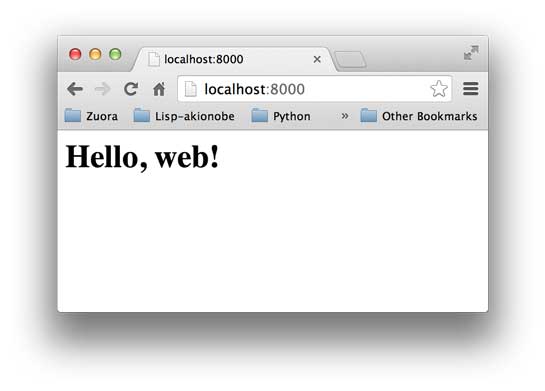
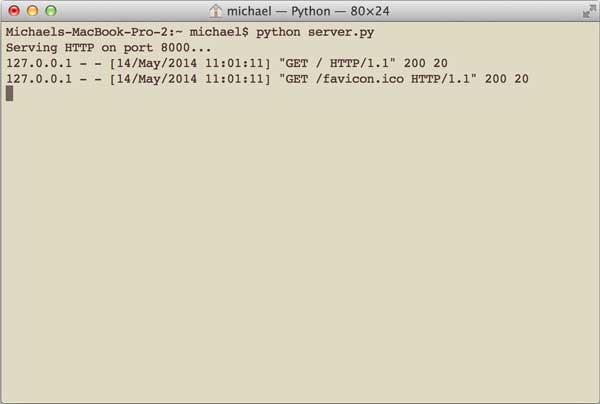
在命令行可以看到wsgiref打印的log信息:
按Ctrl+C终止服务器。
如果你觉得这个Web应用太简单了,可以稍微改造一下,从environ里读取PATH_INFO,这样可以显示更加动态的内容:
# hello.py
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return '<h1>Hello, %s!</h1>' % (environ['PATH_INFO'][1:] or 'web')
你可以在地址栏输入用户名作为URL的一部分,将返回Hello, xxx!:
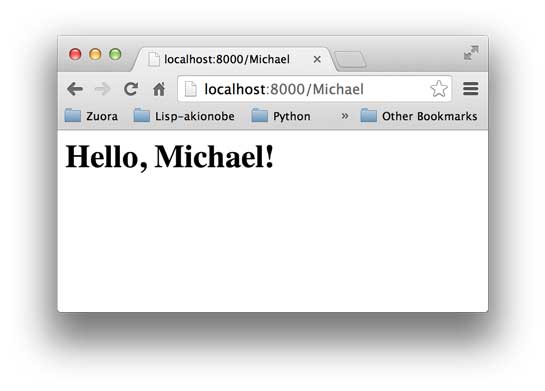
是不是有点Web App的感觉了?
小结
无论多么复杂的Web应用程序,入口都是一个WSGI处理函数。HTTP请求的所有输入信息都可以通过environ获得,HTTP响应的输出都可以通过start_response()加上函数返回值作为Body。
复杂的Web应用程序,光靠一个WSGI函数来处理还是太底层了,我们需要在WSGI之上再抽象出Web框架,进一步简化Web开发。
使用Web框架
了解了WSGI框架,我们发现:其实一个Web App,就是写一个WSGI的处理函数,针对每个HTTP请求进行响应。
但是如何处理HTTP请求不是问题,问题是如何处理100个不同的URL。
每一个URL可以对应GET和POST请求,当然还有PUT、DELETE等请求,但是我们通常只考虑最常见的GET和POST请求。
一个最简单的想法是从environ变量里取出HTTP请求的信息,然后逐个判断:
def application(environ, start_response):
method = environ['REQUEST_METHOD']
path = environ['PATH_INFO']
if method=='GET' and path=='/':
return handle_home(environ, start_response)
if method=='POST' and path='/signin':
return handle_signin(environ, start_response)
...
只是这么写下去代码是肯定没法维护了。
代码这么写没法维护的原因是因为WSGI提供的接口虽然比HTTP接口高级了不少,但和Web App的处理逻辑比,还是比较低级,我们需要在WSGI接口之上能进一步抽象,让我们专注于用一个函数处理一个URL,至于URL到函数的映射,就交给Web框架来做。
由于用Python开发一个Web框架十分容易,所以Python有上百个开源的Web框架。这里我们先不讨论各种Web框架的优缺点,直接选择一个比较流行的Web框架——Flask来使用。
用Flask编写Web App比WSGI接口简单(这不是废话么,要是比WSGI还复杂,用框架干嘛?),我们先用easy_install或者pip安装Flask:
$ easy_install flask
然后写一个app.py,处理3个URL,分别是:
GET /:首页,返回Home;GET /signin:登录页,显示登录表单;POST /signin:处理登录表单,显示登录结果。
注意噢,同一个URL/signin分别有GET和POST两种请求,映射到两个处理函数中。
Flask通过Python的装饰器在内部自动地把URL和函数给关联起来,所以,我们写出来的代码就像这样:
from flask import Flask
from flask import request
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def home():
return '<h1>Home</h1>'
@app.route('/signin', methods=['GET'])
def signin_form():
return '''<form action="/signin" method="post">
<p><input name="username"></p>
<p><input name="password" type="password"></p>
<p><button type="submit">Sign In</button></p>
</form>'''
@app.route('/signin', methods=['POST'])
def signin():
# 需要从request对象读取表单内容:
if request.form['username']=='admin' and request.form['password']=='password':
return '<h3>Hello, admin!</h3>'
return '<h3>Bad username or password.</h3>'
if __name__ == '__main__':
app.run()
运行python app.py,Flask自带的Server在端口5000上监听:
$ python app.py
* Running on http://127.0.0.1:5000/
打开浏览器,输入首页地址http://localhost:5000/:
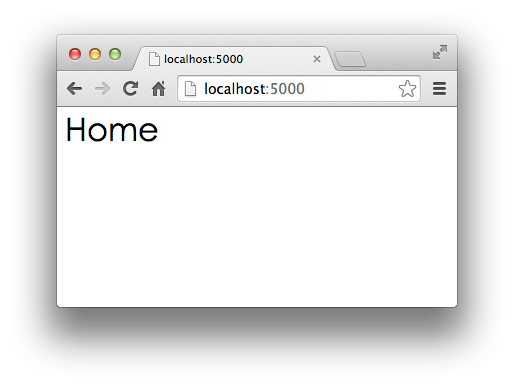
首页显示正确!
再在浏览器地址栏输入http://localhost:5000/signin,会显示登录表单:
输入预设的用户名admin和口令password,登录成功:
输入其他错误的用户名和口令,登录失败:
实际的Web App应该拿到用户名和口令后,去数据库查询再比对,来判断用户是否能登录成功。
除了Flask,常见的Python Web框架还有:
当然了,因为开发Python的Web框架也不是什么难事,我们后面也会自己开发一个Web框架。
小结
有了Web框架,我们在编写Web应用时,注意力就从WSGI处理函数转移到URL+对应的处理函数,这样,编写Web App就更加简单了。
在编写URL处理函数时,除了配置URL外,从HTTP请求拿到用户数据也是非常重要的。Web框架都提供了自己的API来实现这些功能。Flask通过request.form['name']来获取表单的内容。
使用模板
Web框架把我们从WSGI中拯救出来了。现在,我们只需要不断地编写函数,带上URL,就可以继续Web App的开发了。
但是,Web App不仅仅是处理逻辑,展示给用户的页面也非常重要。在函数中返回一个包含HTML的字符串,简单的页面还可以,但是,想想新浪首页的6000多行的HTML,你确信能在Python的字符串中正确地写出来么?反正我是做不到。
俗话说得好,不懂前端的Python工程师不是好的产品经理。有Web开发经验的同学都明白,Web App最复杂的部分就在HTML页面。HTML不仅要正确,还要通过CSS美化,再加上复杂的JavaScript脚本来实现各种交互和动画效果。总之,生成HTML页面的难度很大。
由于在Python代码里拼字符串是不现实的,所以,模板技术出现了。
使用模板,我们需要预先准备一个HTML文档,这个HTML文档不是普通的HTML,而是嵌入了一些变量和指令,然后,根据我们传入的数据,替换后,得到最终的HTML,发送给用户:

这就是传说中的MVC:Model-View-Controller,中文名“模型-视图-控制器”。
Python处理URL的函数就是C:Controller,Controller负责业务逻辑,比如检查用户名是否存在,取出用户信息等等;
包含变量{{ name }}的模板就是V:View,View负责显示逻辑,通过简单地替换一些变量,View最终输出的就是用户看到的HTML。
MVC中的Model在哪?Model是用来传给View的,这样View在替换变量的时候,就可以从Model中取出相应的数据。
上面的例子中,Model就是一个dict:
{ 'name': 'Michael' }
只是因为Python支持关键字参数,很多Web框架允许传入关键字参数,然后,在框架内部组装出一个dict作为Model。
现在,我们把上次直接输出字符串作为HTML的例子用高端大气上档次的MVC模式改写一下:
from flask import Flask, request, render_template
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def home():
return render_template('home.html')
@app.route('/signin', methods=['GET'])
def signin_form():
return render_template('form.html')
@app.route('/signin', methods=['POST'])
def signin():
username = request.form['username']
password = request.form['password']
if username=='admin' and password=='password':
return render_template('signin-ok.html', username=username)
return render_template('form.html', message='Bad username or password', username=username)
if __name__ == '__main__':
app.run()
Flask通过render_template()函数来实现模板的渲染。和Web框架类似,Python的模板也有很多种。Flask默认支持的模板是jinja2,所以我们先直接安装jinja2:
$ easy_install jinja2
然后,开始编写jinja2模板:
home.html
用来显示首页的模板:
<html>
<head>
<title>Home</title>
</head>
<body>
<h1 style="font-style:italic">Home</h1>
</body>
</html>
form.html
用来显示登录表单的模板:
<html>
<head>
<title>Please Sign In</title>
</head>
<body>
{% if message %}
<p style="color:red">{{ message }}</p>
{% endif %}
<form action="/signin" method="post">
<legend>Please sign in:</legend>
<p><input name="username" placeholder="Username" value="{{ username }}"></p>
<p><input name="password" placeholder="Password" type="password"></p>
<p><button type="submit">Sign In</button></p>
</form>
</body>
</html>
signin-ok.html
登录成功的模板:
<html>
<head>
<title>Welcome, {{ username }}</title>
</head>
<body>
<p>Welcome, {{ username }}!</p>
</body>
</html>
登录失败的模板呢?我们在form.html中加了一点条件判断,把form.html重用为登录失败的模板。
最后,一定要把模板放到正确的templates目录下,templates和app.py在同级目录下:

启动python app.py,看看使用模板的页面效果:
通过MVC,我们在Python代码中处理M:Model和C:Controller,而V:View是通过模板处理的,这样,我们就成功地把Python代码和HTML代码最大限度地分离了。
使用模板的另一大好处是,模板改起来很方便,而且,改完保存后,刷新浏览器就能看到最新的效果,这对于调试HTML、CSS和JavaScript的前端工程师来说实在是太重要了。
在Jinja2模板中,我们用{{ name }}表示一个需要替换的变量。很多时候,还需要循环、条件判断等指令语句,在Jinja2中,用{% ... %}表示指令。
比如循环输出页码:
{% for i in page_list %}
<a href="/page/{{ i }}">{{ i }}</a>
{% endfor %}
如果page_list是一个list:[1, 2, 3, 4, 5],上面的模板将输出5个超链接。
除了Jinja2,常见的模板还有:
Mako:用
<% ... %>和${xxx}的一个模板;Cheetah:也是用
<% ... %>和${xxx}的一个模板;Django:Django是一站式框架,内置一个用
{% ... %}和{{ xxx }}的模板。
小结
有了MVC,我们就分离了Python代码和HTML代码。HTML代码全部放到模板里,写起来更有效率。
协程
协程,又称微线程,纤程。英文名Coroutine。
协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。比如子程序A、B:
def A():
print '1'
print '2'
print '3'
def B():
print 'x'
print 'y'
print 'z'
假设由协程执行,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:
1
2
x
y
3
z
但是在A中是没有调用B的,所以协程的调用比函数调用理解起来要难一些。
看起来A、B的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持还非常有限,用在generator中的yield可以一定程度上实现协程。虽然支持不完全,但已经可以发挥相当大的威力了。
来看例子:
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
import time
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
time.sleep(1)
r = '200 OK'
def produce(c):
c.next()
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
if __name__=='__main__':
c = consumer()
produce(c)
执行结果:
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator(生成器),把一个consumer传入produce后:
首先调用c.next()启动生成器;
然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
consumer通过yield拿到消息,处理,又通过yield把结果传回;
produce拿到consumer处理的结果,继续生产下一条消息;
produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用Donald Knuth的一句话总结协程的特点:
“子程序就是协程的一种特例。”
gevent
Python通过yield提供了对协程的基本支持,但是不完全。而第三方的gevent为Python提供了比较完善的协程支持。
gevent是第三方库,通过greenlet实现协程,其基本思想是:
当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
由于切换是在IO操作时自动完成,所以gevent需要修改Python自带的一些标准库,这一过程在启动时通过monkey patch完成:
from gevent import monkey; monkey.patch_socket()
import gevent
def f(n):
for i in range(n):
print gevent.getcurrent(), i
g1 = gevent.spawn(f, 5)
g2 = gevent.spawn(f, 5)
g3 = gevent.spawn(f, 5)
g1.join()
g2.join()
g3.join()
运行结果:
<Greenlet at 0x10e49f550: f(5)> 0
<Greenlet at 0x10e49f550: f(5)> 1
<Greenlet at 0x10e49f550: f(5)> 2
<Greenlet at 0x10e49f550: f(5)> 3
<Greenlet at 0x10e49f550: f(5)> 4
<Greenlet at 0x10e49f910: f(5)> 0
<Greenlet at 0x10e49f910: f(5)> 1
<Greenlet at 0x10e49f910: f(5)> 2
<Greenlet at 0x10e49f910: f(5)> 3
<Greenlet at 0x10e49f910: f(5)> 4
<Greenlet at 0x10e49f4b0: f(5)> 0
<Greenlet at 0x10e49f4b0: f(5)> 1
<Greenlet at 0x10e49f4b0: f(5)> 2
<Greenlet at 0x10e49f4b0: f(5)> 3
<Greenlet at 0x10e49f4b0: f(5)> 4
可以看到,3个greenlet是依次运行而不是交替运行。
要让greenlet交替运行,可以通过gevent.sleep()交出控制权:
def f(n):
for i in range(n):
print gevent.getcurrent(), i
gevent.sleep(0)
执行结果:
<Greenlet at 0x10cd58550: f(5)> 0
<Greenlet at 0x10cd58910: f(5)> 0
<Greenlet at 0x10cd584b0: f(5)> 0
<Greenlet at 0x10cd58550: f(5)> 1
<Greenlet at 0x10cd584b0: f(5)> 1
<Greenlet at 0x10cd58910: f(5)> 1
<Greenlet at 0x10cd58550: f(5)> 2
<Greenlet at 0x10cd58910: f(5)> 2
<Greenlet at 0x10cd584b0: f(5)> 2
<Greenlet at 0x10cd58550: f(5)> 3
<Greenlet at 0x10cd584b0: f(5)> 3
<Greenlet at 0x10cd58910: f(5)> 3
<Greenlet at 0x10cd58550: f(5)> 4
<Greenlet at 0x10cd58910: f(5)> 4
<Greenlet at 0x10cd584b0: f(5)> 4
3个greenlet交替运行,
把循环次数改为500000,让它们的运行时间长一点,然后在操作系统的进程管理器中看,线程数只有1个。
当然,实际代码里,我们不会用gevent.sleep()去切换协程,而是在执行到IO操作时,gevent自动切换,代码如下:
from gevent import monkey; monkey.patch_all()
import gevent
import urllib2
def f(url):
print('GET: %s' % url)
resp = urllib2.urlopen(url)
data = resp.read()
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(f, 'https://www.python.org/'),
gevent.spawn(f, 'https://www.yahoo.com/'),
gevent.spawn(f, 'https://github.com/'),
])
运行结果:
GET: https://www.python.org/
GET: https://www.yahoo.com/
GET: https://github.com/
45661 bytes received from https://www.python.org/.
14823 bytes received from https://github.com/.
304034 bytes received from https://www.yahoo.com/.
从结果看,3个网络操作是并发执行的,而且结束顺序不同,但只有一个线程。
小结
使用gevent,可以获得极高的并发性能,但gevent只能在Unix/Linux下运行,在Windows下不保证正常安装和运行。
由于gevent是基于IO切换的协程,所以最神奇的是,我们编写的Web App代码,不需要引入gevent的包,也不需要改任何代码,仅仅在部署的时候,用一个支持gevent的WSGI服务器,立刻就获得了数倍的性能提升。具体部署方式可以参考后续“实战”-“部署Web App”一节。