You are here
python 读写文件 编码

下面的东西对理解编码有大用
在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下:
1. UNICODE (UTF8-16),C854;
2. UTF-8,E59388;
3. GBK,B9FE。
一、python中的str和unicode
一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?
在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为
u'\u54c8\u54c8'
而str,是一个字节数组,这个字节数组表示的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。这里它仅仅是一个字节流,没有其它的含义,如果你想使这个字节流显示的内容有意义,就必须用正确的编码格式,解码显示。
例如:
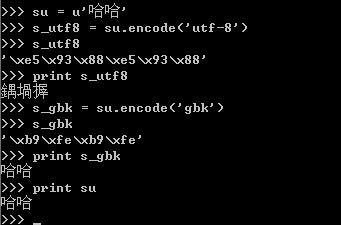
对于unicode对象哈哈进行编码,编码成一个utf-8编码的str-s_utf8,s_utf8就是是一个字节数组,存放的就是'\xe5\x93\x88\xe5\x93\x88',但是这仅仅是一个字节数组,如果你想将它通过print语句输出成哈哈,那你就失望了,为什么呢?
因为print语句它的实现是将要输出的内容传送了操作系统,操作系统会根据系统的编码对输入的字节流进行编码,这就解释了为什么utf-8格式的字符串“哈哈”,输出的是“鍝堝搱”,因为 '\xe5\x93\x88\xe5\x93\x88'用GB2312去解释,其显示的出来就是“鍝堝搱”。这里再强调一下,str记录的是字节数组,只是某种编码的存储格式,至于输出到文件或是打印出来是什么格式,完全取决于其解码的编码将它解码成什么样子。
这里再对print进行一点补充说明:当将一个unicode对象传给print时,在内部会将该unicode对象进行一次转换,转换成本地的默认编码(这仅是个人猜测)
二、str和unicode对象的转换
str和unicode对象的转换,通过encode和decode实现,具体使用如下:
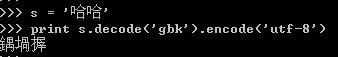
将GBK'哈哈'转换成unicode,然后再转换成UTF8
三、Setdefaultencoding

如上图的演示代码所示:
当把s(gbk字符串)直接编码成utf-8的时候,将抛出异常,但是通过调用如下代码:
import sys
reload(sys)
sys.setdefaultencoding('gbk')
后就可以转换成功,为什么呢?在python中str和unicode在编码和解码过程中,如果将一个str直接编码成另一种编码,会先把str解码成unicode,采用的编码为默认编码,一般默认编码是anscii,所以在上面示例代码中第一次转换的时候会出错,当设定当前默认编码为'gbk'后,就不会出错了。
至于reload(sys)是因为Python2.5 初始化后会删除 sys.setdefaultencoding 这个方法,我们需要重新载入。
四、操作不同文件的编码格式的文件
建立一个文件test.txt,文件格式用ANSI,内容为:
abc中文
用python来读取
# coding=gbk
print open("Test.txt").read()
结果:abc中文
把文件格式改成UTF-8:
结果:abc涓枃
显然,这里需要解码:
# coding=gbk
import codecs
print open("Test.txt").read().decode("utf-8")
结果:abc中文
上面的test.txt我是用Editplus来编辑的,但当我用Windows自带的记事本编辑并存成UTF-8格式时,
运行时报错:
Traceback (most recent call last):
File "ChineseTest.py", line 3, in
print open("Test.txt").read().decode("utf-8")
UnicodeEncodeError: 'gbk' codec can't encode character u'\ufeff' in position 0: illegal multibyte sequence
原来,某些软件,如notepad,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)。
因此我们在读取时需要自己去掉这些字符,python中的codecs module定义了这个常量:
# coding=gbk
import codecs
data = open("Test.txt").read()
if data[:3] == codecs.BOM_UTF8:
data = data[3:]
print data.decode("utf-8")
结果:abc中文
五、文件的编码格式和编码声明的作用
源文件的编码格式对字符串的声明有什么作用呢?这个问题困扰一直困扰了我好久,现在终于有点眉目了,文件的编码格式决定了在该源文件中声明的字符串的编码格式,例如:
str = '哈哈'
print repr(str)
a.如果文件格式为utf-8,则str的值为:'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码)
b.如果文件格式为gbk,则str的值为:'\xb9\xfe\xb9\xfe'(哈哈的gbk编码)
在第一节已经说过,python中的字符串,只是一个字节数组,所以当把a情况的str输出到gbk编码的控制台时,就将显示为乱码:鍝堝搱;而当把b情况下的str输出utf-8编码的控制台时,也将显示乱码的问题,是什么也没有,也许'\xb9\xfe\xb9\xfe'用utf-8解码显示,就是空白吧。>_<
说完文件格式,现在来谈谈编码声明的作用吧,每个文件在最上面的地方,都会用# coding=gbk 类似的语句声明一下编码,但是这个声明到底有什么用呢?到止前为止,我觉得它的作用也就是三个:
- 声明源文件中将出现非ascii编码,通常也就是中文;
- 在高级的IDE中,IDE会将你的文件格式保存成你指定编码格式。
- 决定源码中类似于u'哈'这类声明的将‘哈'解码成unicode所用的编码格式,也是一个比较容易让人迷惑的地方,看示例:
#coding:gbk
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个些代码保存成一个utf-8文本,运行,你认为会输出什么呢?大家第一感觉肯定输出的肯定是:
u'\u54c8\u54c8'
ss:哈哈
但是实际上输出是:
u'\u935d\u581d\u6431'
ss:鍝堝搱
为什么会这样,这时候,就是编码声明在作怪了,在运行ss = u'哈哈'的时候,整个过程可以分为以下几步:
1) 获取'哈哈'的编码:由文件编码格式确定,为'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码形式)
2) 转成 unicode编码的时候,在这个转换的过程中,对于'\xe5\x93\x88\xe5\x93\x88'的解码,不是用utf-8解码,而是用声明编码处指定的编码GBK,将'\xe5\x93\x88\xe5\x93\x88'按GBK解码,得到就是''鍝堝搱'',这三个字的unicode编码就是u'\u935d\u581d\u6431',至止可以解释为什么print repr(ss)输出的是u'\u935d\u581d\u6431' 了。
好了,这里有点绕,我们来分析下一个示例:
#-*- coding:utf-8 -*-
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个示例这次保存成GBK编码形式,运行结果,竟然是:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xb9 in position 0: unexpected code byte
这里为什么会有utf8解码错误呢?想想上个示例也明白了,转换第一步,因为文件编码是GBK,得到的是'哈哈'编码是GBK的编码'\xb9\xfe\xb9\xfe',当进行第二步,转换成 unicode的时候,会用UTF8对'\xb9\xfe\xb9\xfe'进行解码,而大家查utf-8的编码表会发现,utf8编码表(关于UTF- 8解释可参见字符编码笔记:ASCII、UTF-8、UNICODE)中根本不存在,所以会报上述错误。
来自 http://www.jb51.net/article/26543.htm
python读写文件,和设置文件的字符编码比如utf-8
一. python打开文件代码如下:
f = open("d:\test.txt", "w")
说明:
第一个参数是文件名称,包括路径;
第二个参数是打开的模式mode
'r':只读(缺省。如果文件不存在,则抛出错误)
'w':只写(如果文件不存在,则自动创建文件)
'a':附加到文件末尾
'r+':读写
如果需要以二进制方式打开文件,需要在mode后面加上字符"b",比如"rb""wb"等
二、python读取文件内容f.read(size)
参数size表示读取的数量,可以省略。如果省略size参数,则表示读取文件所有内容。
f.readline()读取文件一行的内容 f.readlines()读取所有的行到数组里面[line1,line2,...lineN]。
在避免将所有文件内容加载到内存中,这种方法常常使用,便于提高效率。
三、python写入文件f.write(string)
将一个字符串写入文件,如果写入结束,必须在字符串后面加上"\n",然后f.close()关闭文件
四、文件中的内容定位
f.read()读取之后,文件指针到达文件的末尾,如果再来一次f.read()将会发现读取的是空内容,如果想再次读取全部内容,必须将定位指针移动到文件开始:
f.seek(0)
这个函数的格式如下(单位是bytes):f.seek(offset, from_what) from_what表示开始读取的位置,offset表示从from_what再移动一定量的距离,比如f.seek(10, 3)表示定位到第三个字符并再后移10个字符。
from_what值为0时表示文件的开始,它也可以省略,缺省是0即文件开头。下面给出一个完整的例子:
f = open('/tmp/workfile', 'r+') f.write('0123456789abcdef') f.seek(5) # Go to the 6th byte in the file f.read(1) f.seek (-3, 2) # Go to the 3rd byte before the end f.read(1)
五、关闭文件释放资源文件操作完毕,一定要记得关闭文件f.close(),可以释放资源供其他程序使
只是ASCII或者gbk编码格式的的文件读写,比较简单,读写如下:
# coding=gbk f = open('c:/intimate.txt','r') # r 指示文件打开模式,即只读 s1 = f.read() s2 = f.readline() s3 = f.readlines() #读出所有内容 f.close() f = open('c:/intimate.txt','w') # w 写文件 11 f.write(s1) 12 f.writelines(s2) # 没有writeline 13 f.close()
六. f.writelines不会输出换行符。
python unicode文件读写:
# coding=gbk import codecs f = codecs.open('c:/intimate.txt','a','utf-8') f.write(u'中文') s = '中文' f.write(s.decode('gbk')) f.close() f = codecs.open('c:/intimate.txt','r','utf-8') s = f.readlines() f.close() for line in s: print line.encode('gbk')
python代码文件的编码
py文件默认是ASCII编码,中文在显示时会做一个ASCII到系统默认编码的转换,这时就会出错:SyntaxError: Non-ASCII character。需要在代码文件的第一行或第二行添加编码指示:
# coding=utf-8 ##以utf-8编码储存中文字符- print '中文'像上面那样直接输入的字符串是按照代码文件的编码来处理的,如果用unicode编码,有以下2种方式:
- s1 = u'中文' #u表示用unicode编码方式储存信息
- s2 = unicode('中文','gbk')
unicode是一个内置函数,第二个参数指示源字符串的编码格式。
decode是任何字符串具有的方法,将字符串转换成unicode格式,参数指示源字符串的编码格式。
encode也是任何字符串具有的方法,将字符串转换成参数指定的格式。
python字符串的编码
用 u'汉字' 构造出来的是unicode类型,不用的话构造出来是str类型
str的编码是与系统环境相关的,一般就是sys.getfilesystemencoding()得到的值
所以从unicode转str,要用encode方法
从str转unicode,所以要用decode
例如:
# coding=utf-8 #默认编码格式为utf-8 s = u'中文' #unicode编码的文字 print s.encode('utf-8') #转换成utf-8格式输出 print s #效果与上面相同,似乎默认直接转换为指定编码
我的总结:
u=u'unicode编码文字' g=u.encode('gbk') #转换为gbk格式 print g #此时为乱码,因为当前环境为utf-8,gbk编码文字为乱码 str=g.decode('gbk').encode('utf-8') #以gbk编码格式读取g(因为他就是gbk编码的)并转换为utf-8格式输出 print str #正常显示中文
安全的方法:
s.decode('gbk','ignore').encode('utf-8′) #以gbk编码读取(当然是读取gbk编码格式的文字了)并忽略错误的编码,转换成utf-8编码输出
因为decode的函数原型是decode([encoding], [errors='strict']),可以用第二个参数控制错误处理的策略,默认的参数就是strict,代表遇到非法字符时抛出异常;
如果设置为ignore,则会忽略非法字符;
如果设置为replace,则会用?取代非法字符;
如果设置为xmlcharrefreplace,则使用XML的字符引用。
字符串编码
python中默认编码是ASCII,可以通过以下方式设置和获取:
print sys.getdefaultencoding()
sys.setdefaultencoding('gbk')
使用print来输出时,python将内容传递给系统处理,windows会按照系统默认编码来输出。如果包含了中文,就要注意几点。
1 python代码文件的编码
py文件默认是ASCII编码,中文在显示时会做一个ASCII到系统默认编码的转换,这时就会出错:SyntaxError: Non-ASCII character。需要在代码文件的第一行或第二行添加编码指示:
2 print '中文'
2 字符串的编码
像上面那样直接输入的字符串是按照代码文件的编码来处理的,如果是unicode编码,有以下三种方式:
2 s2 = unicode('中文','gbk')
3 s3 = s1.decode('gbk')
unicode是一个内置函数,第二个参数指示源字符串的编码格式。
decode是任何字符串具有的方法,将字符串转换成unicode格式,参数指示源字符串的编码格式。
encode也是任何字符串具有的方法,将字符串转换成参数指定的格式。
3 系统的默认编码
对 于中文系统来说,默认的是gbk,gb2312也可以,因为它是gbk的字集。使用print输出时,字符串会被转换成此格式,隐式转换时,是从代码文件 编码格式转换成gbk,默认是ASCII->GBK。考虑上面第二点,如果字符串编码不是ASCII,则隐式转换会出错,需要显式转换,使用 encode方法。如果指定了代码文件格式为gbk,则隐式转换不存在问题。
2
3 s = u'中文'
4 print s.encode('gbk')
文件读写
只是ASCII或者gbk编码格式的的文件读写,比较简单,读写如下:
2
3 f = open('c:/intimate.txt','r') # r 指示文件打开模式,即只读
4 s1 = f.read()
5 s2 = f.readline()
6 s3 = f.readlines() #读出所有内容
7
8 f.close()
9
10 f = open('c:/intimate.txt','w') # w 写文件
11 f.write(s1)
12 f.writelines(s2) # 没有writeline
13 f.close()
f.writelines不会输出换行符。
unicode文件读写:
2 import codecs
3
4 f = codecs.open('c:/intimate.txt','a','utf-8')
5 f.write(u'中文')
6 s = '中文'
7 f.write(s.decode('gbk'))
8 f.close()
9
10 f = codecs.open('c:/intimate.txt','r','utf-8')
11 s = f.readlines()
12 f.close()
13 for line in s:
14 print line.encode('gbk')
以上为转发的内容,下面为我做的一些补充。
reload(sys)
print sys.getdefaultencoding()
sys.setdefaultencoding('utf-8')
 >>> s = "/x84/xe5/xb0/x8f/xe6/x98/x8e">>> s.decode('utf-8')
>>> s = "/x84/xe5/xb0/x8f/xe6/x98/x8e">>> s.decode('utf-8')File "<interactive input>", line 1, in ?
File "E:/Program Files/Python24/lib/encodings/utf_8.py", line 16, in decode
UnicodeDecodeError: 'utf8' codec can't decode byte 0x84 in position 0: unexpected code byte
>>>
>>> print s.decode('utf-8')
小明
>>>
问题是如果我们不知道字符里的不合法字节的位置时该怎么进行解码并的出正常编码的那些字符的结果呢,我们可以使用如下两种方法:
>>> s = '/x84/xe5/xb0/x8f/xe6/x98/x8e/x84'>>> s.decode('utf-8')Traceback (most recent call last):
File "<interactive input>", line 1, in ?
File "E:/Program Files/Python24/lib/encodings/utf_8.py", line 16, in decode
UnicodeDecodeError: 'utf8' codec can't decode byte 0x84 in position 0: unexpected code byte
>>> print s.decode('utf-8', 'ignore')小明>>> print s.decode('utf-8', 'replace')?小明?>>> 来自 http://blog.csdn.net/lf8289/article/details/2465196
【教程】用Python的codecs处理各种字符编码的字符串和文件
之前就遇到很多次,对于将,不仅仅是普通的ASCII的字符串,读取或写入文件
之前也就知道用codecs。
后来见到不止一人:
python怎么读取文件名中包含特殊字符的文件 比如xiân.txt
遇到类似问题,但是不会处理,所以,此处,专门去写个教程,简要解释一下codecs如何使用。
【Python中用codecs处理各种字符编码的文件】
完整示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | #!/usr/bin/python# -*- coding: utf-8 -*-"""Function:【教程】用Python的codecs处理各种字符编码的字符串和文件Author: Crifan LiVersion: 2013-10-20Contact: http://www.crifan.com/about/me"""import codecs;def python_codecs_demo(): """demo how to use codecs to handle file with specific encoding""" testStrUnicode = u"中文测试Unicode字符串"; print "testStrUnicode=",testStrUnicode testStrUtf8 = testStrUnicode.encode("UTF-8"); testStrGbk = testStrUnicode.encode("GBK"); outputFilename = "outputFile.txt" print "------------ 1.UTF-8 write and read ------------" print "--- (1) write UTF-8 string into file ---" # 'a+': read,write,append # 'w' : clear before, then write outputFp = codecs.open(outputFilename, 'w'); outputFp.write(testStrUtf8); outputFp.flush(); outputFp.close(); print "--- (2) read out previously written UTF-8 content ---" readoutFp = codecs.open(outputFilename, 'r', 'UTF-8'); #here already is unicode, for we have pass "UTF-8" to codecs.open readOutStrUnicodeFromUtf8 = readoutFp.read() readoutFp.close(); print "readOutStrUnicodeFromUtf8=",readOutStrUnicodeFromUtf8 print "------------ 2.GBK write and read ------------" print "--- (1) write GBK string into file ---" # 'a+': read,write,append # 'w' : clear before, then write outputFp = codecs.open(outputFilename, 'w'); outputFp.write(testStrGbk); outputFp.flush(); outputFp.close(); print "--- (2) read out previously written GBK content ---" readoutFp = codecs.open(outputFilename, 'r', 'GBK'); #here already is unicode, for we have pass "GBK" to codecs.open readOutStrUnicodeFromGbk = readoutFp.read() readoutFp.close(); print "readOutStrUnicodeFromGbk=",readOutStrUnicodeFromGbk print "Note: " print "1. more about encoding, please refer:" print u"【详解】python中的文件操作模式"if __name__ == "__main__": python_codecs_demo() |
输出为:
E:\dev_root\python\tutorial_summary\python_codecs_demo>python_codecs_demo.py ———— 1.UTF-8 write and read ———— — (1) write UTF-8 string into file — — ()2) read out previously written UTF-8 content — readOutStrUnicodeFromUtf8= 中文测试Unicode字符串 ———— 2.GBK write and read ———— — (1) write GBK string into file — — (2) read out previously written GBK content — readOutStrUnicodeFromGbk= 中文测试Unicode字符串 Note: 1. more about encoding, please refer: 【详解】python中的文件操作模式 |
如图:

注:
1.关于字符编码,不熟悉的可参考:
2.关于文件操作模式,不熟悉的可参考:
3.关于Python中的字符串编码,不熟悉的可参考:
【总结】
还是要多参考官网的api的解释,多练习,才会慢慢的真正理解编码的事情。
来自 http://www.crifan.com/tutorial_python_codecs_process_file_char_encoding/