
方法/步骤
语法:
group by 字段 having 条件判断;
group by的用法我已经在上一篇经验中介绍了
还是已员工绩效表为例
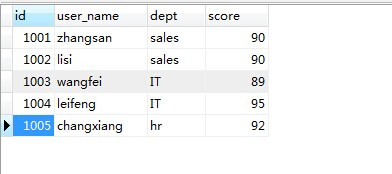
我们如果就是查询每个部门成绩大于89的员工数,可以这样写:
SELECT dept,COUNT(user_name) FROM ec_uses WHERE score>89 GROUP BY dept;
对这个查询的过程进行分析,其实是:先查出绩效成绩大于89的员工记录,然后再用count聚合函数统计部门的人数,也就是说where是在聚合之前筛选记录的,那么如果我们要在聚合之后筛选记录该如何处理呢?
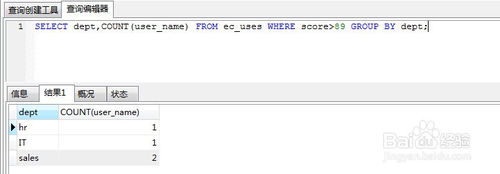
例如,在上面的基础上再加一个条件,查询部门人数大于1的部门
那么我们是先要统计出每个部门的人数,也就是要用count聚合函数,然后再看哪些部门的人数是多于1人的
也就是筛选条件是在聚合之后的,这时where已不能满足使用,我们就需要用到having了
sql:
SELECT dept,COUNT(user_name) count_tmp FROM ec_uses GROUP BY dept HAVING count_tmp>1;
看执行结果
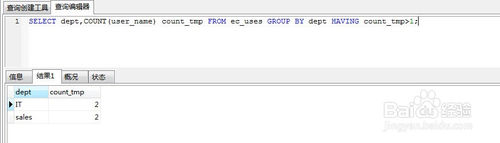
- 所以having子句对我们筛选分组后的数据非常方便
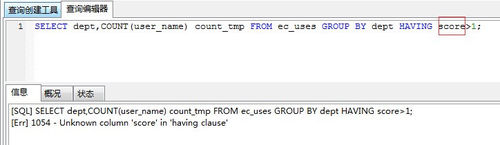
值得注意的是having后面跟的条件判断的字段必须是聚合函数返回的结果,否则sql会报错,例如:
SELECT dept,COUNT(user_name) count_tmp FROM ec_uses GROUP BY dept HAVING score>1;
END