You are here
从零开始:写一个简单的Python框架
你为什么想搭建一个Web框架?我想有下面几个原因:
有一个新奇的想法,将会取代其他框架。
获得一些疯狂的街头信誉。
你的问题比较独特,现有的框架不适合。
你想成为一位更好的Web开发者,你对Web框架是如何运行的感到好奇。
我将集中精力在最后一点上。这篇文章旨在描述我从写一个小型的服务框架中学到了什么,我将解释框架的设计,以及如何一步一步,一个函数一个函数的实现这个框架的。关于此项目完整的代码可以点击此链接。
我希望我的行为可以鼓励大家去尝试因为真的非常有趣,我们可以从中学到很多关于web应用程序是如何工作的知识,而且比我想象的要容易的多。
范围
框架的功能有:请求-响应周期、身份验证、数据库访问、模板的生成等。Web开发者使用框架,因为大多数Web应用程序共享大量的相同功能,并且没必要为每个项目都重新实现这些功能。
像Rails或Django这些较大的框架做了高层次的抽象并且功能完备。这些框架经历了很长时间来完成所有这些特性,因此,我们重点完成一个微型框架。开始写代码前,我先列一下这个微型框架的功能及一些限制。
功能:
可以处理GET和POST的HTTP请求。从该WIKI中你可以了解获得关于HTTP简介。
异步的(我喜欢Python3 asyncio这个模块)。
包含简单的路由逻辑,以及参数捕获。
像其他酷的微框架一样,提供简单的用户级API。
可以处理身份验证,因为学会会非常的酷(在第2部分介绍)。
限制:
仅完成HTTP/1.1协议的一小部分:不实现transfer-encoding, http-auth, content-encoding (gzip), persistant connections(持久连接)这些功能。
响应信息中无MIME-guessing,用户将不得不手动设置。
无WSGI-只是简单的TCP连接处理。
不支持数据库。
我决定用一个小的用例来使上面的需求更具体,同样可以演示这个框架的API:

用户应该能够定义几个异步函数返回字符串或响应对象,然后用表示路由的字符串与这些函数配对,最后通过一个函数调用(start_server)开始处理请求。
有了这些设计后,我需要编码来实现这些抽象:
一个可以接受TCP连接和进度的异步函数。
将原始文本解析成某种抽象的容器。
某种机制,可以确定每个请求,哪个函数应该被调用。
将上面所有的集合在一起并提供一个简单的接口给开发者。
我针对每个功能点开始写一些必要的抽象描述。在几次重构后,页面布局被分成几个部分。每部分是相对独立的,这种情况下特别好,因为每一部分都可以自行研究学习。这些是我上面列出的抽象的具体体现:
一个HTTPServer对象,需要一个Router对象和一个http_parser模块,并使用他们来初始化。
HTTPConnection对象,每个表示一个单独的客户端HTTP连接并且处理请求-响应周期:使用http_parser模块解析进来的字节流到一个Request对象;使用一个Router实例找到正确的函数调用产生一个响应;最后将这个响应发送回客户端。
一对Request和Response对象提供给用户一种友好的方式来处理本质上是字节流的字符串形式。用户不必了解正确的信息格式或分隔符。
一个Router对象,包含路由功能:函数对。它提供一种增加这些函数对的方法,并且提供了一种给定URL路径,找到对应函数的方法。
最后,一个包含配置文件的App对象,并使用它来实例化一个HTTPServer实例。
让我们仔细分析每一部分,从HTTPConnection开始。
模拟异步连接
为了满足限制(约束),每个HTTP请求是一个单独的 TCP 连接。这会导致请求处理变慢,因为建立多个TCP连接(DNS查询消耗,TCP三次握手消耗,慢启动等)会有相对高的消耗,但是这样更容易模拟。对于这个任务,我选择了asyncio传输协议之上的高级的asyncio-stream模块。我推荐从标准库(stdlib)中签出这段代码,因为阅读这段代码会有乐趣。
HTTPConnection的实例处理多个任务。它使用asyncio.StreamReader对象以增量方式从TCP连接中读取数据并将其存储在缓存中。每次读操作后,它试图解析数据(无论是否在缓存中)并生成一个请求(Request)对象。一旦它接收整个请求,它生成一个回复并通过asyncio.StreamWriter对象发送回客户端。它还处理两个更多的任务︰超时连接和错误处理。
你可以在这里查看这个类的完整代码。我将分开介绍代码的每个部分,为了简洁起见,我删除了描述部分:
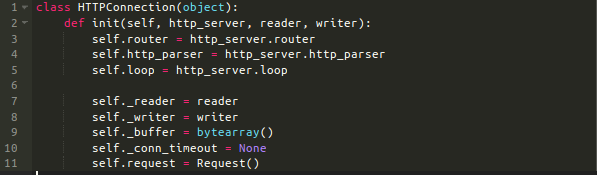
这个init方法比较简单,它仅收集了些对象,后面会用到。存储了router,http_parser和loop对象,分别用作生成响应,解析请求和在事件循环中安排进度。
下一步,存储了reader-writer,一起代表一个TCP连接;一个空的bytearray,充当原始字节的缓冲区。_conn_timeout存储了asyncio.Handle的实例,用来管理超时逻辑。最后,它还存储了一个单独的请求(Request)实例。
下面的代码处理接收和发送数据的核心功能:
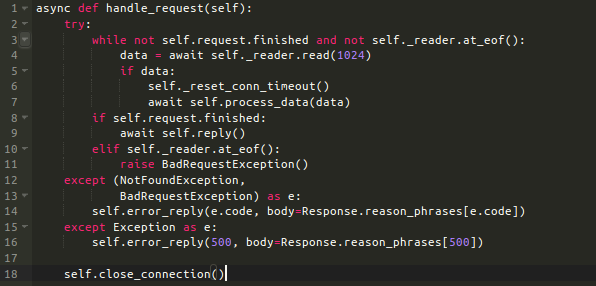
所有代码都是包在一个try-expect代码块中,在解析请求或响应期间抛出的任何异常都会被捕获到,并且一个错误响应会发送回客户端。
请求在一个while循环中会一直被读取,当遇到以下情况会停止:当解析器设置self.request.finished = True时,或客户端关闭了连接(self._reader.at_eof()方法返回True时)。代码尝试在每次循环迭代中从StreamReader中读取数据,并通过调用self.process_data(data)逐步扩展self.request。每次循环读取任何数据的时候,连接超时计时器会被重置。
代码中有一个错误,你能找到吗?我稍后会提到。我同样注意到这个循环有可能消耗掉所有CPU资源,因为没有东西可以读的话,self._reader.read()返回b''对象,意味着会不断的循环,却什么也不做。一个可能的解决方案是以非阻塞方式等待一点时间:await asyncio.sleep(0.1)。我会在的确有必要的时候对其进行优化。
还记得我在上一段的开始提到的错误吗?self._reset_conn_timeout()方法仅在数据从StreamReader读取时被调用。这种设置方式意味直接第一个字节到来时超时才会开始。如果一个客户端同服务器建立了连接但并不发送任何数据,那么就决不会超时。这可能会耗尽系统资源并引起服务的拒绝访问。解决方法是只需在 init方法中调用self._reset_conn_timeout()。
在收到请求时或当连接断开时,代码流就会走到if-else代码块中。这部分代码块会判断是否已经收到的所有数据并完成解析请求,如果是?那么好,产生响应,并将其发送回客户端。如果否?请求有错误发生,抛出异常。最后,调用self.close_connection做一些清理工作。
然析请求的代码是在self.process_data方法中。这段代码非常短且简单,易于测试。

每次调用将数据积累到self._buffer中并且使用self.http_parser尝试解析任何已存放在缓冲区中的数据。值得在这里指出这段代码展示了一种“依赖注入”的模式。如果你记得init这个初始化函数,你应该知道我传进来一个http_server对象。在这种情况下,http_parser对象是diy_framework包中的一个模块,它有一个parse_into函数,这个函数接受一个Request对象和一个bytearray作为参数。这很有用,原因有两个。首先,这段代码很容易扩展。比如某人想通过一个不同的解析器来使用HTTPConnection,没问题,只要将这个解析器作为参数传递就可以了。其次,它使测试更加容易,因为http_parser不是硬编码的,因此我们可以用假数据来代替会变得非常容易。
下一个有趣部分是响应方法:

在这里,HTTPConnection实例使用一个来自HTTPServer的路由(router)对象来获取一个生成响应的对象。一个路由可以是任何一个具有get_handler方法的对象,这个方法接受一个字符串参数,并且返回一个可调用的对象或抛出NotFoundException异常。可调用对象是用来处理请求和生成响应。处理程序由使用这个框架的用户来写,就像上面用例中概括的那样,应返回字符串或响应对象。响应对象提供给我们一个友好的接口,因此简单的if代码块确保,无论处理程序返回什么,这段代码最终返回一个统一的响应对象。
接下来,赋值给self._writer的StreamWriter实例被调用,将字节流字符串发送回客户端。在函数返回前,它等待await self._writer.drain(),这就保证了所有数据已被发送到客户端。这将确保当仍有未发送的数据在缓冲区中时,对self._writer.close的调用不会发生。
HTTPConnection类有两个有趣的地方:一个关闭连接的方法和一组处理超时机制的方法。首先,关闭一个连接是通过下面这个小函数来完成的:

任何时候一个连接将被关闭时,代码首先要做的就是取消超时,将它从事件循环中清除掉。
超时机制是一套三个相关的函数︰一个函数,发送错误信息给客户端并且关闭连接的超时器;一个函数,取消当前的超时器;一个函数,调度超时功能。前两个是简单的,出于完整性考虑我添加了它们,我将着重解释下第三个:_reset_conn_timeout。
每次_reset_conn_timeout被调用,它首先取消任何以前赋值给self._conn_timeout设置的asyncio.Handle对象。然后,使用BaseEventLoop.call_later函数,计划在超时数秒后运行_conn_timeout_close函数。如果你记得handle_request函数的内容,你就会知道每次接收任何数据时,就会调用此函数。在将来,这将取消任何现有的超时并且重新设置_conn_timeout_close函数的超时秒数。只要有数据到来,这个循环就不断重置超时回调。如果在超时秒数内没接收到任何数据,_conn_timeout_close最终将被调用。
创建连接
有些事情不得不创建HTTPConnection对象并且要处理好这个对象。这项任务委托给HTTPServer类,该类是一个非常简单的容器,可以帮助存储一些配置(解析器、路由器和事件循环实例),然后使用该配置来创建HTTPConnection的实例:
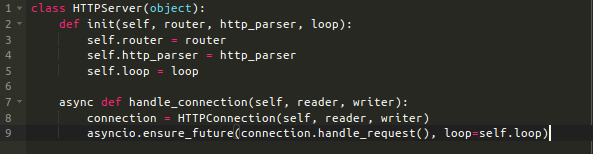
HTTPServer 的每个实例监听在一个端口上。它有一个异步的handle_connection方法,这个方法用来创建HTTPConnection实例并且在事件循环中调试执行它们。这个方法传递给asyncio.start_server作为一个回调函数:每次TCP连接开始的时候被调用(StreamReader和StreamWriter作为参数)。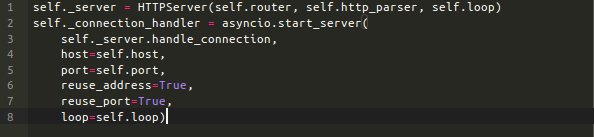
这构成了应用程序工作原理的核心:asyncio.start_server接受TCP连接,并在预配置的 HTTPServer 对象上调用一个方法。此方法处理单个连接的所有逻辑:获取请求、解析、生成响应并发送回客户端,最后关闭连接。它侧重于IO逻辑、解析和产生响应。
非核心IO东西我们先不管。
解析请求
这个微型框架的用户被宠坏了,他们不想使用字节流。他们想要一个更高层次的抽象——一种处理请求(requests)更方便的方式。这个微型框架包含了一个简单的HTTP解析器将字节流转换为请求对象。
这些请求对象是看起来像这样的容器: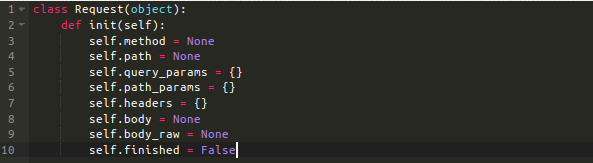
它拥有开发者需要的所有,接收来自客户端很容易理解的包中的数据。那么,除了cookies外,身份验证是至关重要的,我将这部分留在第2部分。
每个HTTP请求包含某些所需的部分——比如请求的路径或请求的方法。它还包含某些可选的部分,比如body体,header头部,或URL参数。此外,由于REST的流行,URL,省略URL参数,还可能包含部分信息。比如,'/users/1/edit'包含了用户的id。
每个请求的各个部分必须被识别,解析并被赋值给一个请求(Request)对象的各个属性。HTTP/1.1是文本协议,简化了过程(HTTP/2是二进制协议-相当有趣)。
http_parser模块中是一组函数,因为解析器不需要跟踪状态。相反,调用代码需要管理一个请求(Request)对象并将其和bytearray(包含请求的原始字节)一起传递到parse_into函数中。为此,解析器修改请求对象以及bytearray缓冲区内容。请求对象获取越来越多数据,而ytearray缓冲区逐渐变空。
Http_parser模块的核心功能是在parse_into函数中: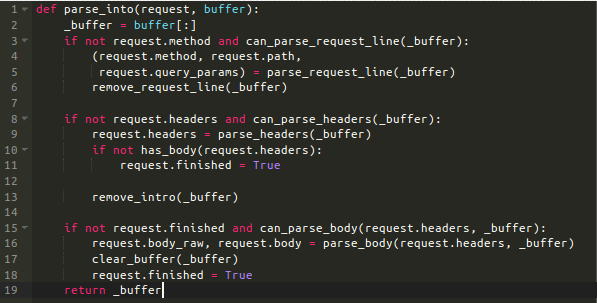
正如你在上面代码中看到的那样,我将解析过程划分为三个部分:解析请求行(请求行有这样的格式:GET /resource HTTP/1.1),解析头部和解析请求body体。
请求行包含的 HTTP 方法和 URL。URL按序还包含更多的信息:路径、url参数和开发人员自定义的url参数。解析出方法和URL很容易——重要的是适当地分割字符串。urlparse.parse函数用于解析URL参数。开发人员定义的url参数使用正则表达式提取。
接下来是HTTP头部。这些都是键/值对形式的简单文本。问题在于,有可能多个头部有相同名称但值不同。一个需要注意的header头部是Content-Length,它指定了body体的长度(不是整个请求,仅仅是body体),对于决定是否解析body体来说是重要的。
最后,解析器根据HTTP方法和头部来决定是否解析请求的body体。
路由
在某种意义上,路由是框架和用户间连接的桥,用户用合适的方法创建一个路由(Router)对象,这个对象由路径/函数对组成,然后将路由对象赋值给App对象。这个App对象按顺序调用get_handler函数生成一个响应。总之,路由负责两件事情——存储路径/函数对和返回所要求的一对。
在路由(Router)类中有两个方法允许最终开发人员增加路由:add_routes和add_route。由于add_routes是在add_route上的一层封装,我将略过它,将注意力集中在 add_route上。
使用Router.build_route_regexp类方法首先将一个路由(一个字符串,类似'/cars/{id}')编译成一个已编译的正则表达式对象。这些已编译正则表达式对象匹配请求路径和提取指定路由的开发人员定义的URL参数。下一步如果有相同的路由存在,则会抛出异常,最终,路由/处理函数对被加入到一个简单的字典中——self.routes。
这里展示了Router如何编译路由(routes)的: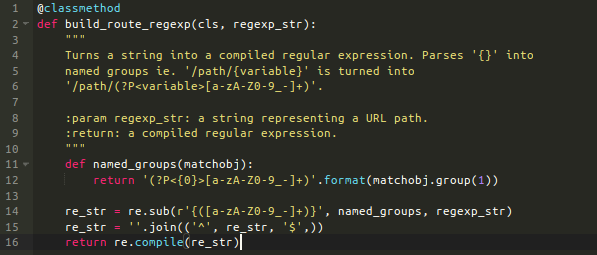
该方法使用正则表达式来替换命名的正则表达式组'(?P
存储一条路由仅仅成功了一半,这里是如何获得一条路由: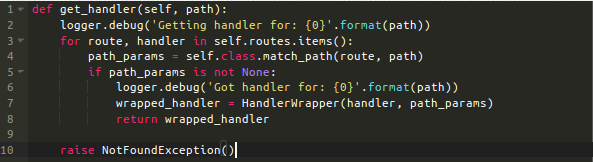
一旦App对象获得一个请求对象,就会获知URL的路径部分(比如,/users/15/edit)。然后需要一个匹配函数生成响应或404错误。get_handler将路径作为参数,循环遍历路由,在每个路由上调用Router.match_path类方法来检测是否有已编译的正则对象匹配请求的路径。如果存在,则调用HandleWrapper来包装这个路由函数。path_params字典包含了路径变量(比如,/users/15/edit中的'15')或如果路由不指定任何变量的话则为空。最后返回包装过的路由函数给App对象。
如果代码迭代遍历整个路由,没有找到匹配路径的,函数抛出NotFoundException异常。
这个Route.match类方法简单:
使用正则对象的匹配方法检测路由与路径是否匹配。如果不匹配则返回None。
最后,我们使用HandleWrapper类。它唯一的工作就是包装一个异步函数,存储path_params字典,通过handle方法对外提供一个统一的接口。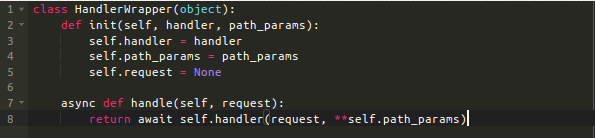
整合所有
框架的最后部分是将所有部分集合在一起——App类。
App类旨在收集所有的配置详细信息。App对象使用它的单个方法start_server,使用一些配置数据创建HTTPServer实例,然后将其传递给函数asyncio.start_server,这里查看更多信息。每一个进来的TCP连接,asyncio.start_server函数调用HTTPServer对象的handle_connection方法。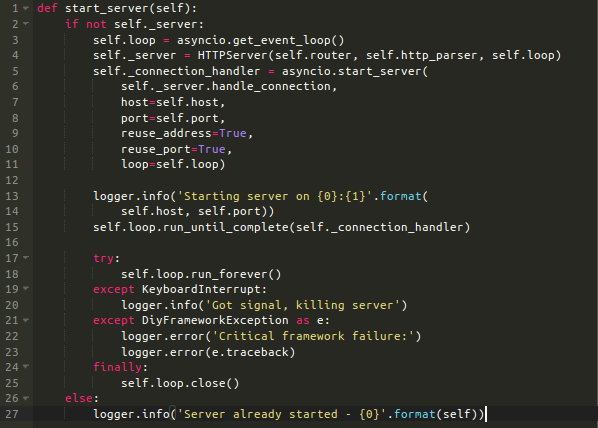
吸取的经验教训
如果你看了整个源码,你会注意到如果不算上测试代码的话,整个框架大致320行代码(算上测试代码,大约540行代码)。确实令我感到惊讶,如此少的代码满足如此多的功能。当然,这个框架还没提供一些有用的功能比如模板,身份验证或数据库访问,不过,这些工作会非常有趣:)。这同样给了我一些想法关于其他框架,比如Django或Tornado是如何工作在一个一般水平的并且我能够快速调试它们。
这也是我以TDD方式(测试驱动开发(Test-Driven Development))做的第一个项目,过程是愉快和高效的。编写测试首先迫使我思考设计和架构而不仅仅是将能工作的代码粘合起来。不要误会我的意思,有很多情况,后者的方法是首选的,但是,如果你对不可维护的代码很重视,你和其他人在未来的数周或数月可以很好的工作,那么TDD确实是你需要的。
我研究一些东西像清晰架构和依赖注入,很明显,路由(Router)类是一个更高级别的接近“核心”的抽象(实体?),然而,像http_parser或App是处在边缘上的,它们要么处理极小的字符串,要么是字节流,要么是中级IO。然而,TDD迫使我去单独思考每个小部分,这让我问自己这样的问题:是否这些方法调用的组合是可理解的?是否类名准确的反映了我正在解决的问题?是否容易区分我代码中不同级别的抽象?
来吧,写一个小的框架,充满乐趣 !
这项工作是基于知识共享署名4.0国际许可证。
英文原文:http://mattscodecave.com/posts/simple-python-framework-from-scratch.html
译者:leisants
来自 http://www.360doc.com/content/16/0617/09/34369088_568454670.shtml