大家都用 Python 来做什么啊?修改
发现很多人都在学习 Python ,但是没有明确的说明可以做什么,主流的功能是什么?想知道目前利用 Python 开发的都在干什么?修改
默认排序按时间排序
63 个回答

首先上一首Python之禅:
Python是一个非常好用的程序语言,开发的速度非常快。我用Python已经一年多了,从Python2.7到现在的Python3.4,也写了好多的小程序,其中大部分都是爬虫程序,下面简单列举几个,可怜了我科的各种系统。
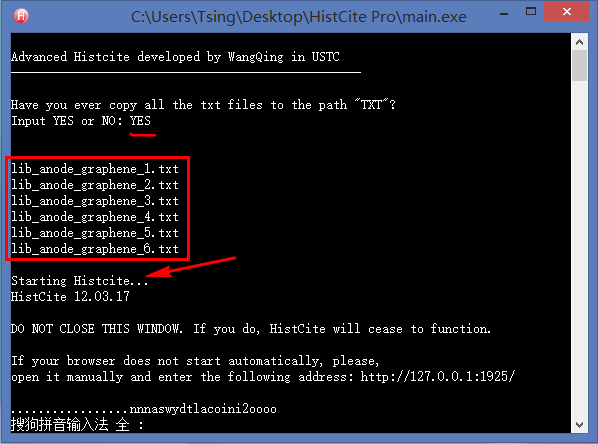
0. 制作引文分析利器HistCite的便捷使用版本
怎么又出现了一个序号为零的啊!没错,这个又是我后来加上的,嘻嘻~
对于整天和文献打交道的研究生来说,HistCite是一款不可多得的效率利器,它可以快速绘制出某个研究领域的发展脉络,快速锁定某个研究方向的重要文献和学术大牛,还可以找到某些具有开创性成果的无指定关键词的论文。但是原生的HistCite已经有4年没有更新了,现在使用会出现各种bug,于是我就用Python基于HistCite内核开发了一个方便使用的免安装版本。具体的使用方法和下载链接见我的第一篇知乎专栏文章:文献引文分析利器HistCite使用教程(附精简易用免安装Pro版本下载) - Tsing的文章 - 知乎专栏
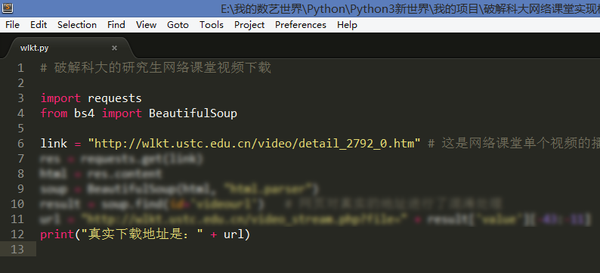
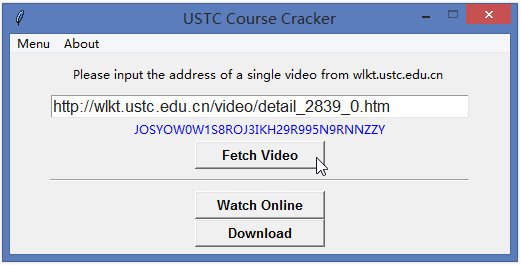
1. 破解观看中科大网络课堂
中国科学技术大学网络课堂(http://wlkt.ustc.edu.cn/)是一个非常好的平台,上面汇集了很多知名教授的授课视频,以及最新的讲座、报告、表演视频,内容还是相当丰富的。但是这些视频只面向校内IP开放。
所以想在校外看到这些视频必须破解视频地址,于是利用Python的requests库结合BeautifulSoup,用了不到10行代码就可以获取真实下载地址。
为了方便没有安装Python的电脑使用,简单写了一个GUI界面,给室友用,都说还是挺好的用的哈。
考虑到视频版权问题,代码和程序就不放出来了,请大家见谅。
2. 获取中科大研究生系统全部学生姓名、学号、选课信息
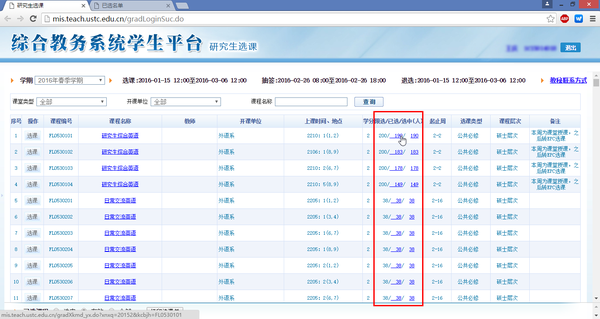
登录中国科学技术大学的研究生综合系统(中国科学技术大学研究生信息平台),可以看到每一门课选课的学生姓名和学号,当时就想能不能做一个这样的系统,来输入任何姓名(或者学号)就可以看到他所有的选课信息呢?这是选课首页:
点击每门课的已选人数链接,可以看到所有的选课学生姓名和学号:
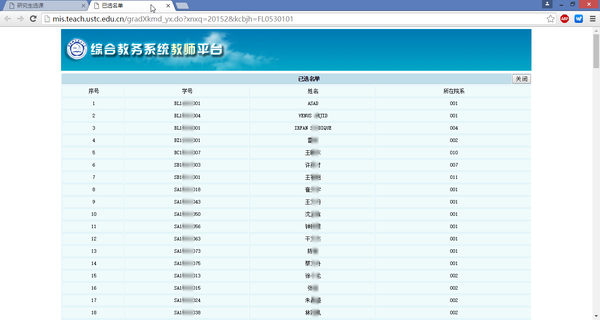
下面就利用requests的模拟登录功能,先获取全部课程的链接,并保存对于的课程信息,然后挨个获取了所有课程的选课信息。为了保护学生信息,对程序的关键部分进行了模糊处理,希望大家谅解。
这样就获取了一个巨大的json文件,里面全部是学生姓名学号选课信息:
有了这个json文件,我们可以写入数据库,也可以直接利用json文件来查询:
为了方便其他人使用,基于上面的数据我开发了一个线上版本:
输入姓名或者学号都可以直接查询别人的选课信息:
这个地址就不放出来了,如果您是科大的研究生,私信我,我把链接发给你。
3. 扫描中科大研究生系统上的弱密码用户
基于上面获得的选课学生学号,很容易利用Python依次模拟登录研究生,密码就用弱密码123456,然后可以获得身份证号码等重要信息。
这样就得到了使用123456作为密码的用户信息,所以在此提醒大家一定不要使用弱密码,希望下面的同学早日修改密码。
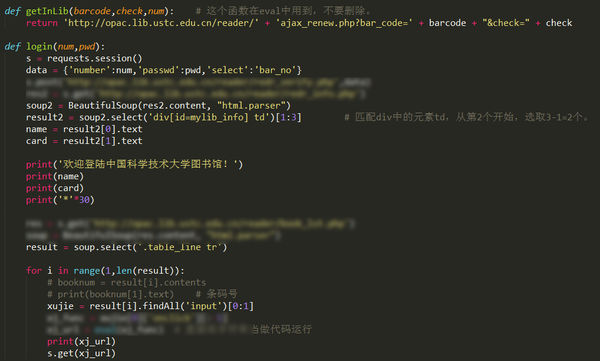
4. 模拟登录中科大图书馆并自动续借
最近,科大图书馆系统升级了,到处都加了验证码,所以下面这个方法直接使用肯定是不行了,不过曾经毕竟成功过哈。以前收到借阅图书到期通知短信,就会运行一下这个程序,自动续借了,然后就可以再看一个月了。
运行就是这样的,自动续借成功,看到的链接就是每本书的续借链接。
5. 网易云音乐批量下载
终于来一个正常一点的哈,那么我就直接放代码吧,可以下载网易云音乐各个榜单的全部歌曲,批量下载,速度挺快。请注意提前要创建一个名为 “网易云音乐” 的文件夹。
于是就可以愉快的听歌了。
6. 批量下载读者杂志某一期的全部文章
上次无意中发现读者杂志还有一个在线的版本,然后兴趣一来就用Python批量下载了上面的大量文章,保存为txt格式。
7. 获取城市PM2.5浓度和排名
最近环境问题很受关注,就用Python写了一个抓取PM2.5的程序玩玩,程序支持多线程,方便扩展。
8. 爬取易迅网商品价格信息
当时准备抓取淘宝价格的,发现有点难,后来就没有尝试,就把目标选在了易迅网。
9. 音悦台MV免积分下载
音悦台上有好多高质量的MV,想要下载却没有积分,于是就想到破解下载。当时受一个大神的代码的启发,就写出了下面的代码,虽然写的有点乱,但还是可以成功破解的哈。
10. 其他请参考:能利用爬虫技术做到哪些很酷很有趣很有用的事情? - Tsing 的回答
结语:Python是一个利器,而我用到的肯定也只是皮毛,写过的程序多多少少也有点相似,但是我对Python的爱却是越来越浓的。
补充:看到评论中有好多知友问哪里可以快速而全面地学习Python编程,我只给大家推荐一个博客,大家认真看就够了:Python教程 - 廖雪峰的官方网站
Python是一个非常好用的程序语言,开发的速度非常快。我用Python已经一年多了,从Python2.7到现在的Python3.4,也写了好多的小程序,其中大部分都是爬虫程序,下面简单列举几个,可怜了我科的各种系统。

0. 制作引文分析利器HistCite的便捷使用版本
怎么又出现了一个序号为零的啊!没错,这个又是我后来加上的,嘻嘻~
对于整天和文献打交道的研究生来说,HistCite是一款不可多得的效率利器,它可以快速绘制出某个研究领域的发展脉络,快速锁定某个研究方向的重要文献和学术大牛,还可以找到某些具有开创性成果的无指定关键词的论文。但是原生的HistCite已经有4年没有更新了,现在使用会出现各种bug,于是我就用Python基于HistCite内核开发了一个方便使用的免安装版本。具体的使用方法和下载链接见我的第一篇知乎专栏文章:文献引文分析利器HistCite使用教程(附精简易用免安装Pro版本下载) - Tsing的文章 - 知乎专栏
1. 破解观看中科大网络课堂
中国科学技术大学网络课堂(http://wlkt.ustc.edu.cn/)是一个非常好的平台,上面汇集了很多知名教授的授课视频,以及最新的讲座、报告、表演视频,内容还是相当丰富的。但是这些视频只面向校内IP开放。
所以想在校外看到这些视频必须破解视频地址,于是利用Python的requests库结合BeautifulSoup,用了不到10行代码就可以获取真实下载地址。
 所以想在校外看到这些视频必须破解视频地址,于是利用Python的requests库结合BeautifulSoup,用了不到10行代码就可以获取真实下载地址。
所以想在校外看到这些视频必须破解视频地址,于是利用Python的requests库结合BeautifulSoup,用了不到10行代码就可以获取真实下载地址。为了方便没有安装Python的电脑使用,简单写了一个GUI界面,给室友用,都说还是挺好的用的哈。
 为了方便没有安装Python的电脑使用,简单写了一个GUI界面,给室友用,都说还是挺好的用的哈。
为了方便没有安装Python的电脑使用,简单写了一个GUI界面,给室友用,都说还是挺好的用的哈。考虑到视频版权问题,代码和程序就不放出来了,请大家见谅。
 考虑到视频版权问题,代码和程序就不放出来了,请大家见谅。
考虑到视频版权问题,代码和程序就不放出来了,请大家见谅。2. 获取中科大研究生系统全部学生姓名、学号、选课信息
登录中国科学技术大学的研究生综合系统(中国科学技术大学研究生信息平台),可以看到每一门课选课的学生姓名和学号,当时就想能不能做一个这样的系统,来输入任何姓名(或者学号)就可以看到他所有的选课信息呢?这是选课首页:
点击每门课的已选人数链接,可以看到所有的选课学生姓名和学号:
 点击每门课的已选人数链接,可以看到所有的选课学生姓名和学号:
点击每门课的已选人数链接,可以看到所有的选课学生姓名和学号:下面就利用requests的模拟登录功能,先获取全部课程的链接,并保存对于的课程信息,然后挨个获取了所有课程的选课信息。为了保护学生信息,对程序的关键部分进行了模糊处理,希望大家谅解。
 下面就利用requests的模拟登录功能,先获取全部课程的链接,并保存对于的课程信息,然后挨个获取了所有课程的选课信息。为了保护学生信息,对程序的关键部分进行了模糊处理,希望大家谅解。
下面就利用requests的模拟登录功能,先获取全部课程的链接,并保存对于的课程信息,然后挨个获取了所有课程的选课信息。为了保护学生信息,对程序的关键部分进行了模糊处理,希望大家谅解。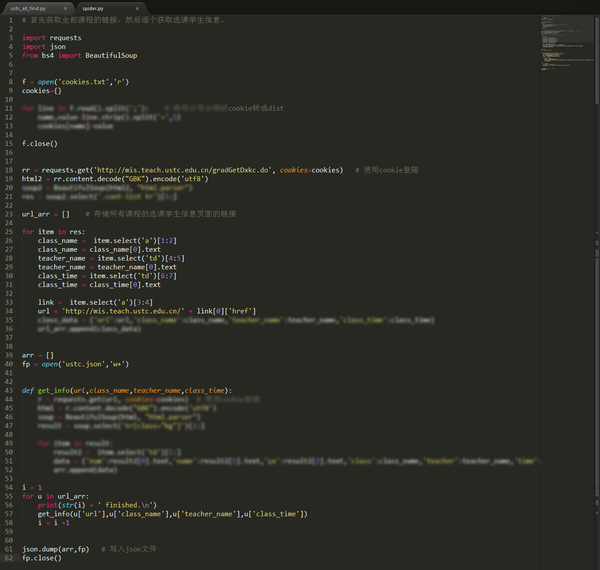
这样就获取了一个巨大的json文件,里面全部是学生姓名学号选课信息:
有了这个json文件,我们可以写入数据库,也可以直接利用json文件来查询:
 有了这个json文件,我们可以写入数据库,也可以直接利用json文件来查询:
有了这个json文件,我们可以写入数据库,也可以直接利用json文件来查询:为了方便其他人使用,基于上面的数据我开发了一个线上版本:
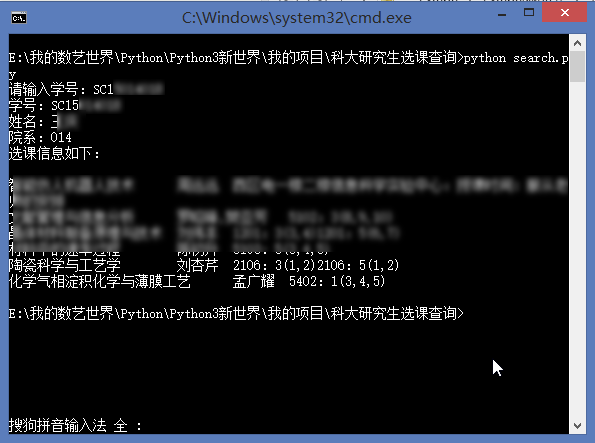 为了方便其他人使用,基于上面的数据我开发了一个线上版本:
为了方便其他人使用,基于上面的数据我开发了一个线上版本:输入姓名或者学号都可以直接查询别人的选课信息:
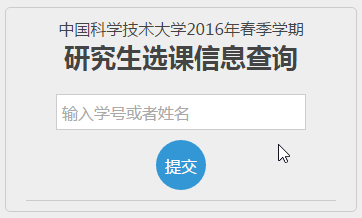 输入姓名或者学号都可以直接查询别人的选课信息:
输入姓名或者学号都可以直接查询别人的选课信息:
这个地址就不放出来了,如果您是科大的研究生,私信我,我把链接发给你。
3. 扫描中科大研究生系统上的弱密码用户
基于上面获得的选课学生学号,很容易利用Python依次模拟登录研究生,密码就用弱密码123456,然后可以获得身份证号码等重要信息。
这样就得到了使用123456作为密码的用户信息,所以在此提醒大家一定不要使用弱密码,希望下面的同学早日修改密码。
 这样就得到了使用123456作为密码的用户信息,所以在此提醒大家一定不要使用弱密码,希望下面的同学早日修改密码。
这样就得到了使用123456作为密码的用户信息,所以在此提醒大家一定不要使用弱密码,希望下面的同学早日修改密码。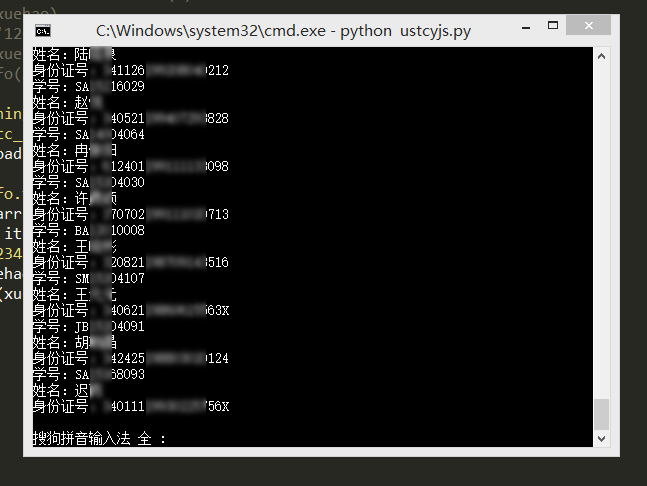
4. 模拟登录中科大图书馆并自动续借
最近,科大图书馆系统升级了,到处都加了验证码,所以下面这个方法直接使用肯定是不行了,不过曾经毕竟成功过哈。以前收到借阅图书到期通知短信,就会运行一下这个程序,自动续借了,然后就可以再看一个月了。
运行就是这样的,自动续借成功,看到的链接就是每本书的续借链接。
 运行就是这样的,自动续借成功,看到的链接就是每本书的续借链接。
运行就是这样的,自动续借成功,看到的链接就是每本书的续借链接。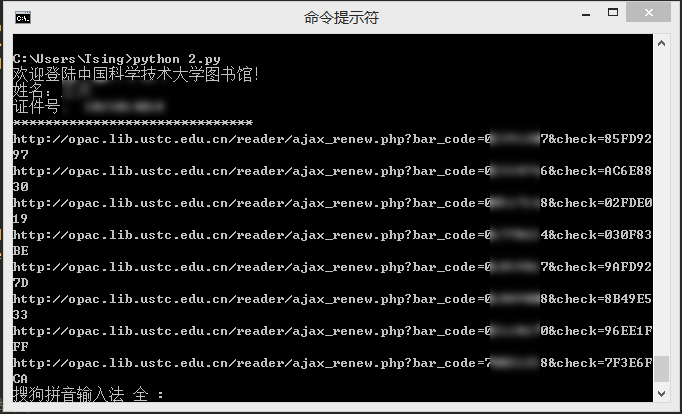
5. 网易云音乐批量下载
终于来一个正常一点的哈,那么我就直接放代码吧,可以下载网易云音乐各个榜单的全部歌曲,批量下载,速度挺快。请注意提前要创建一个名为 “网易云音乐” 的文件夹。
# 网易云音乐批量下载
# By Tsing
# Python3.4.4
import requests
import urllib
# 榜单歌曲批量下载
# r = requests.get('http://music.163.com/api/playlist/detail?id=2884035') # 网易原创歌曲榜
# r = requests.get('http://music.163.com/api/playlist/detail?id=19723756') # 云音乐飙升榜
# r = requests.get('http://music.163.com/api/playlist/detail?id=3778678') # 云音乐热歌榜
r = requests.get('http://music.163.com/api/playlist/detail?id=3779629') # 云音乐新歌榜
# 歌单歌曲批量下载
# r = requests.get('http://music.163.com/api/playlist/detail?id=123415635') # 云音乐歌单——【华语】中国风的韵律,中国人的印记
# r = requests.get('http://music.163.com/api/playlist/detail?id=122732380') # 云音乐歌单——那不是爱,只是寂寞说的谎
arr = r.json()['result']['tracks'] # 共有100首歌
for i in range(10): # 输入要下载音乐的数量,1到100。
name = str(i+1) + ' ' + arr[i]['name'] + '.mp3'
link = arr[i]['mp3Url']
urllib.request.urlretrieve(link, '网易云音乐\\' + name) # 提前要创建文件夹
print(name + ' 下载完成')
上面这些都是在Python3的环境下完成的,在此之前,用Python2还写了一些程序,下面也放几个吧。初期代码可能显得有些幼稚,请大神见谅。
6. 批量下载读者杂志某一期的全部文章
上次无意中发现读者杂志还有一个在线的版本,然后兴趣一来就用Python批量下载了上面的大量文章,保存为txt格式。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 保存读者杂志某一期的全部文章为TXT
# By Tsing
# Python 2.7.9
import urllib2
import os
from bs4 import BeautifulSoup
def urlBS(url):
response = urllib2.urlopen(url)
html = response.read()
soup = BeautifulSoup(html)
return soup
def main(url):
soup = urlBS(url)
link = soup.select('.booklist a')
path = os.getcwd()+u'/读者文章保存/'
if not os.path.isdir(path):
os.mkdir(path)
for item in link:
newurl = baseurl + item['href']
result = urlBS(newurl)
title = result.find("h1").string
writer = result.find(id="pub_date").string.strip()
filename = path + title + '.txt'
print filename.encode("gbk")
new=open(filename,"w")
new.write("<<" + title.encode("gbk") + ">>\n\n")
new.write(writer.encode("gbk")+"\n\n")
text = result.select('.blkContainerSblkCon p')
for p in text:
context = p.text
new.write(context.encode("gbk"))
new.close()
if __name__ == '__main__':
time = '2015_03'
baseurl = 'http://www.52duzhe.com/' + time +'/'
firsturl = baseurl + 'index.html'
main(firsturl)
7. 获取城市PM2.5浓度和排名
最近环境问题很受关注,就用Python写了一个抓取PM2.5的程序玩玩,程序支持多线程,方便扩展。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 获取城市PM2.5浓度和排名
# By Tsing
# Python 2.7.9
import urllib2
import threading
from time import ctime
from bs4 import BeautifulSoup
def getPM25(cityname):
site = 'http://www.pm25.com/' + cityname + '.html'
html = urllib2.urlopen(site)
soup = BeautifulSoup(html)
city = soup.find(class_ = 'bi_loaction_city') # 城市名称
aqi = soup.find("a",{"class","bi_aqiarea_num"}) # AQI指数
quality = soup.select(".bi_aqiarea_right span") # 空气质量等级
result = soup.find("div",class_ ='bi_aqiarea_bottom') # 空气质量描述
print city.text + u'AQI指数:' + aqi.text + u'\n空气质量:' + quality[0].text + result.text
print '*'*20 + ctime() + '*'*20
def one_thread(): # 单线程
print 'One_thread Start: ' + ctime() + '\n'
getPM25('hefei')
getPM25('shanghai')
def two_thread(): # 多线程
print 'Two_thread Start: ' + ctime() + '\n'
threads = []
t1 = threading.Thread(target=getPM25,args=('hefei',))
threads.append(t1)
t2 = threading.Thread(target=getPM25,args=('shanghai',))
threads.append(t2)
for t in threads:
# t.setDaemon(True)
t.start()
if __name__ == '__main__':
one_thread()
print '\n' * 2
two_thread()
8. 爬取易迅网商品价格信息
当时准备抓取淘宝价格的,发现有点难,后来就没有尝试,就把目标选在了易迅网。
#!/usr/bin/env python
#coding:utf-8
# 根据易迅网的商品ID,爬取商品价格信息。
# By Tsing
# Python 2.7.9
import urllib2
from bs4 import BeautifulSoup
def get_yixun(id):
price_origin,price_sale = '0','0'
url = 'http://item.yixun.com/item-' + id + '.html'
html = urllib2.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(html)
title = unicode(soup.title.text.strip().strip(u'【价格_报价_图片_行情】-易迅网').replace(u'】','')).encode('utf-8').decode('utf-8')
print title
try:
soup_origin = soup.find("dl", { "class" : "xbase_item xprice xprice_origin" })
price_origin = soup_origin.find("span", { "class" : "mod_price xprice_val" }).contents[1].text
print u'原价:' + price_origin
except:
pass
try:
soup_sale= soup.find('dl',{'class':'xbase_item xprice'})
price_sale = soup_sale.find("span", { "class" : "mod_price xprice_val" }).contents[1]
print u'现价:'+ price_sale
except:
pass
print url
return None
if __name__ == '__main__':
get_yixun('2189654')
9. 音悦台MV免积分下载
音悦台上有好多高质量的MV,想要下载却没有积分,于是就想到破解下载。当时受一个大神的代码的启发,就写出了下面的代码,虽然写的有点乱,但还是可以成功破解的哈。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 音悦台MV免积分下载
# By Tsing
# Python 2.7.9
import urllib2
import urllib
import re
mv_id = '2278607' # 这里输入mv的id,即http://v.yinyuetai.com/video/2275893最后的数字
url = "http://www.yinyuetai.com/insite/get-video-info?flex=true&videoId=" + mv_id
timeout = 30
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
req = urllib2.Request(url, None, headers)
res = urllib2.urlopen(req,None, timeout)
html = res.read()
reg = r"http://\w*?\.yinyuetai\.com/uploads/videos/common/.*?(?=&br)"
pattern=re.compile(reg)
findList = re.findall(pattern,html) # 找到mv所有版本的下载链接
if len(findList) >= 3:
mvurl = findList[2] # 含有流畅、高清、超清三个版本时下载超清
else:
mvurl = findList[0] # 版本少时下载流畅视频
local = 'MV.flv'
try:
print 'downloading...please wait...'
urllib.urlretrieve(mvurl,local)
print "[:)] Great! The mv has been downloaded.\n"
except:
print "[:(] Sorry! The action is failed.\n"
10. 其他请参考:能利用爬虫技术做到哪些很酷很有趣很有用的事情? - Tsing 的回答
结语:Python是一个利器,而我用到的肯定也只是皮毛,写过的程序多多少少也有点相似,但是我对Python的爱却是越来越浓的。
补充:看到评论中有好多知友问哪里可以快速而全面地学习Python编程,我只给大家推荐一个博客,大家认真看就够了:Python教程 - 廖雪峰的官方网站

# 负能量预警,这是一个悲伤的故事。
用Python 可以撩妹。
前段时间撩一个妹子,吃饭期间聊起来,妹子正在找暑假的实习,问我有没有公司推荐。我说,『你想去什么样的公司呀?』,妹子说,『听说最近搞投资的机构好多待遇又好,你知不知道呀?』。开玩笑,我好歹也算VC圈里打过滚的人,当场拍着胸脯向妹子保证,『交给我吧!回头发你一份投资机构的名单!』
然而回去之后一合计,手机里的联系人统共加起来没几个,这要怎么向妹子交代?幸好我已经不是曾经那个花了5个小时手动下载几百张PPT 素材图片的『分析师』了,什么Requests, BeautifulSoup, lxml, NumPy, Pandas, 哪个我没有见过?说干就干,我找了一个收录了比较齐全的投资机构的网站,哼哧哼哧码起代码来。
一眨眼好几个小时过去了,在被Unicode 编码折磨了一百零一遍之后,我总算捯饬出了一份投资机构名单。
这是一份非常非常简陋的名单,因为我懒得再往里面添东西,毕竟妹子的原话是『在杭州有哪些投资机构啊?』,喏,都在这儿了。
怀着喜悦的心情,我把这份名单发给了妹子。
反应不错嘛!这几个小时没白花!
# 曾经
# 我是一个
# 懵懂的
# 热血青年
# 直到
# 有一天
# 我收到了
# 一张
# 小小的
# 卡片
## 以上是我创作的俳句
过了一段时间,妹子主动来找我了。哼哼,人生苦短,我用Python。你看,这不,轻轻松松撩妹成功。
。
。。
。。。
。。。。
。。。
。。
。
后来我和妹子成为了好朋友,每周都会联系个一次两次,聊上个一句两句。
# 正文已经结束,请观众有序离场。前方高能预警,请系好安全带,文明驾驶。
大概这才是Python 的正确用法吧。(远目
用Python 可以撩妹。
前段时间撩一个妹子,吃饭期间聊起来,妹子正在找暑假的实习,问我有没有公司推荐。我说,『你想去什么样的公司呀?』,妹子说,『听说最近搞投资的机构好多待遇又好,你知不知道呀?』。开玩笑,我好歹也算VC圈里打过滚的人,当场拍着胸脯向妹子保证,『交给我吧!回头发你一份投资机构的名单!』
然而回去之后一合计,手机里的联系人统共加起来没几个,这要怎么向妹子交代?幸好我已经不是曾经那个花了5个小时手动下载几百张PPT 素材图片的『分析师』了,什么Requests, BeautifulSoup, lxml, NumPy, Pandas, 哪个我没有见过?说干就干,我找了一个收录了比较齐全的投资机构的网站,哼哧哼哧码起代码来。
一眨眼好几个小时过去了,在被Unicode 编码折磨了一百零一遍之后,我总算捯饬出了一份投资机构名单。
这是一份非常非常简陋的名单,因为我懒得再往里面添东西,毕竟妹子的原话是『在杭州有哪些投资机构啊?』,喏,都在这儿了。
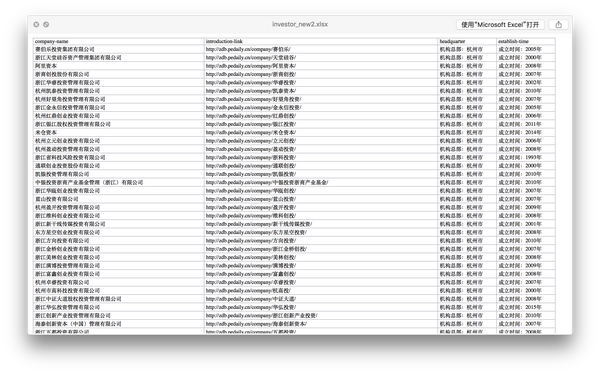 这是一份非常非常简陋的名单,因为我懒得再往里面添东西,毕竟妹子的原话是『在杭州有哪些投资机构啊?』,喏,都在这儿了。
这是一份非常非常简陋的名单,因为我懒得再往里面添东西,毕竟妹子的原话是『在杭州有哪些投资机构啊?』,喏,都在这儿了。怀着喜悦的心情,我把这份名单发给了妹子。
反应不错嘛!这几个小时没白花!
# 曾经
# 我是一个
# 懵懂的
# 热血青年
# 直到
# 有一天
# 我收到了
# 一张
# 小小的
# 卡片
## 以上是我创作的俳句
过了一段时间,妹子主动来找我了。哼哼,人生苦短,我用Python。你看,这不,轻轻松松撩妹成功。

。
。。
。。。
。。。。
。。。
。。
。









后来我和妹子成为了好朋友,每周都会联系个一次两次,聊上个一句两句。
# 正文已经结束,请观众有序离场。前方高能预警,请系好安全带,文明驾驶。


大概这才是Python 的正确用法吧。(远目









作为一个初学者,什么才能让你对学习产生浓厚的兴趣并且有成就感呢?那就学爬虫吧!
我是在暑假才开始接触python,到现在认认真真的学了不到一个月的样子。今天终于参照曾经一次在知乎上看到过的想法写了一个程序给女朋友作为礼物。这也是我第一次送女朋友礼物,感觉还是挺有成就感的
我做的东西很简单,附上成品图
用正则爬武汉的天气网,然后把温度和生活指数爬下来,再爬了520张我爱你的电影截图,一天附上一张,这样就可以作为一个邮件发送了~
最后写了一个crontab的脚本,每天定时运行这个python,反正我mac也不关机~
但是这段感情关机了
我是在暑假才开始接触python,到现在认认真真的学了不到一个月的样子。今天终于参照曾经一次在知乎上看到过的想法写了一个程序给女朋友作为礼物。这也是我第一次送女朋友礼物,感觉还是挺有成就感的
我做的东西很简单,附上成品图
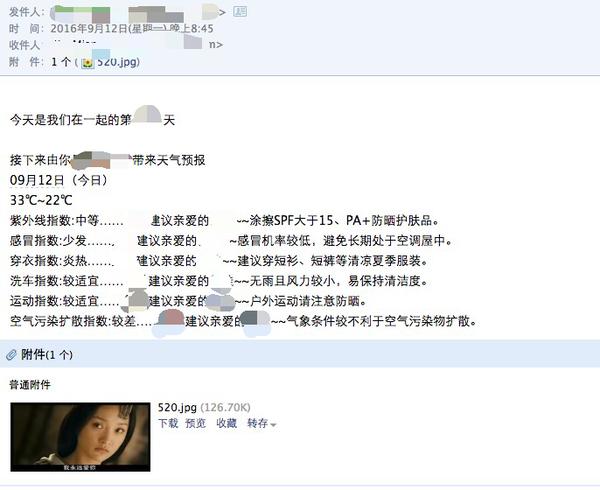
用正则爬武汉的天气网,然后把温度和生活指数爬下来,再爬了520张我爱你的电影截图,一天附上一张,这样就可以作为一个邮件发送了~

最后写了一个crontab的脚本,每天定时运行这个python,反正我mac也不关机~
但是这段感情关机了


1、用Python开发了一个保存instagram图片的 微信公众号。
通过发送链接、就可以获取 instagram图片或视频了。
当然发送@ID也是可以的。
后来顺带增加了保存Facebook和推特视频的功能。
2、配合lego ev3和小米手环,做了个微信跑步神器。日行8万步!
3、写小脚本,在朋友圈发非微信拍摄的小视频。
通过发送链接、就可以获取 instagram图片或视频了。
当然发送@ID也是可以的。
后来顺带增加了保存Facebook和推特视频的功能。
2、配合lego ev3和小米手环,做了个微信跑步神器。日行8万步!
3、写小脚本,在朋友圈发非微信拍摄的小视频。

非常感谢第9条关于提取音悦台MV的想法,@Tsing
作为一名音悦台不尴不尬的使用者,看到这一个想法简直是久旱逢雨,洞房花烛,。。。
于是我就打算整(neng)理(luan)一下代码,使成为一个方便的小工具长期使用。
结果不小心代码越写越多,最后到了450+行(尴尬),但好歹也稍微完善了一下
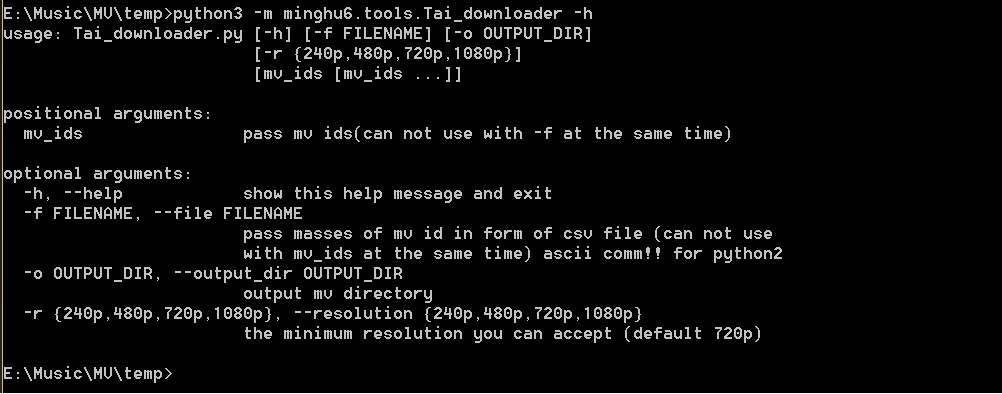
帮助:
使用例图:
使用例图:
结果:
关于修改说明:
作为一名音悦台不尴不尬的使用者,看到这一个想法简直是久旱逢雨,洞房花烛,。。。
于是我就打算整(neng)理(luan)一下代码,使成为一个方便的小工具长期使用。
结果不小心代码越写越多,最后到了450+行(尴尬),但好歹也稍微完善了一下
帮助:
使用例图:
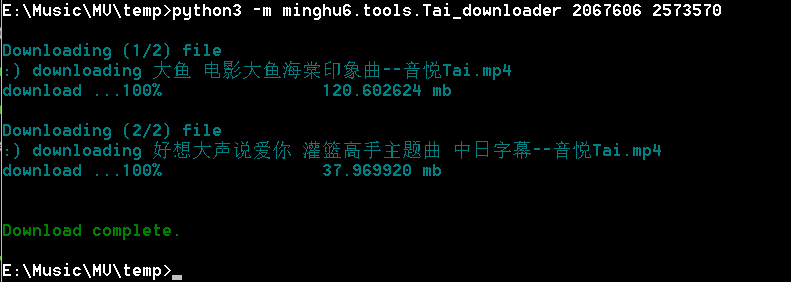
使用例图:
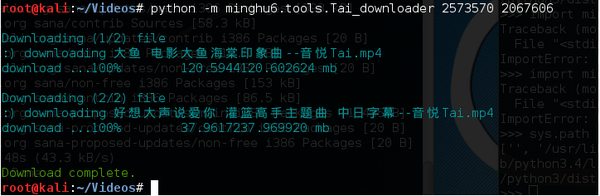
结果:
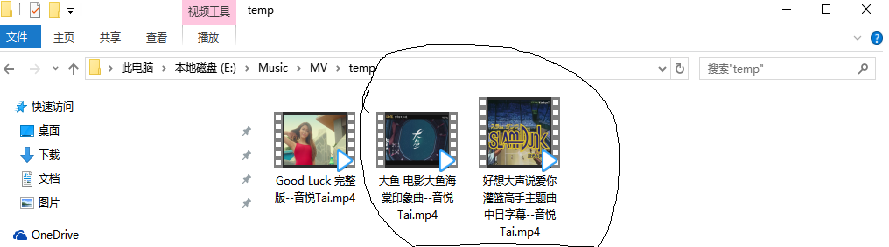
关于修改说明:
<fix>由于下载的MV视频格式是MPEG-4,所以MV文件拓展名由.flv改为.mp4</fix>
<fix>依据实际情况重调了清晰度的选择逻辑,作为一名音悦台的重度使用者,总是选择满足条件的最清晰视频</fix>
<new>
迁移到python3
后来闲的蛋疼
在python2 文本/二进制傻傻分不清的<str>类型,
以及不支持日韩文等字符的Windows 中文默认编码gbk(big5)的
令人痛苦的骚扰下,
修改代码使对python2的兼容(也因此使得代码变得啰嗦而又难看起来)。
但还是推荐使用python3,python2对于文件名在非UTF-8终端显示上可能有一点问题,
但不影响文件本身的名字,所以我也懒得管它(我真是受够python2了)
</new>
<new>增加了批量处理支持(但经过综合考虑,不支持并发)
<description>假定文件名Tai_downloader.py 将其加入到了python的搜索路径</description>
<usage>直接输入MV id: python -m Tai_downloader 2067606 2573570 2565963</usage>
<usage>指定包含MV id 的csv文件 python -m Tai_downloader </usage>
<new>
<new>获取MV 正版名称(同样有赖于对title的正则匹配)</new>
<new>用标准库argparse包装成面向shell的工具</new>
<new>增加了对下载进程以及下载结果的显示</new>
<new>增加了一些错误信息提示等有的没的</new>
<new>
添加了Windows下cmd的颜色字体
添加了Linux 下bash的颜色字体
</new>
测试:
python 2.7.10
python 3.4
on Windows 10
on Kali
测试的还是少,按照辩证唯物主义的观点,bug一定有,只不过是多少与严重程度的问题
# -*- coding: utf-8 -*-
#! /usr/bin/env python
from __future__ import print_function #both for py2 and py3,must at top of file
"""
################################################################################
YinYueTai MV download Tool
First Author: Tsing in zhihu https://www.zhihu.com/people/wq123
Modified by minghu6
################################################################################
"""
import sys
import os
import re
def python_version():return sys.version_info.major
if python_version()==3:
from urllib.request import Request #python3
from urllib.request import urlopen #python3
from urllib.request import urlretrieve #python3
from html.parser import HTMLParser
elif python_version()==2:
from urllib2 import Request
from urllib2 import urlopen
from urllib import urlretrieve
from HTMLParser import HTMLParser
def report(count, block_size, total_size):
download_size=count*block_size
percent = int(download_size*100/total_size)
pts=('\rdownload ...{0:d}%'
'\t\t{1:f} mb').format(percent,download_size/10e5)
if iswin():
with printDarkSkyBlue():
sys.stdout.write(pts)
else:
sys.stdout.write(UseStyle(pts,'cyan'))
sys.stdout.flush()
MV_NOT_EXIST='mv_not_exist'
def get_mv_name(mv_id):
#get html according to mv_id
url='http://v.yinyuetai.com/video/'+str(mv_id)
i=urlopen(url)
html=i.read()
if python_version()==3:
codec = i.info().get_param('charset', 'utf8')
html = html.decode(codec,errors='ignore')
i.close()
#parse html and get title
class Hpr(HTMLParser):
def handle_starttag(self,tag,attr):
if tag=='title':
self.handle_data=self.get_data
self.data=list()
def handle_endtag(self,tag):
if tag=='title':
self.handle_data=self.do_nothing
def do_nothing(self,data):
pass
def get_data(self,data):
self.data.append(data)
if python_version()==3:
hpr=Hpr(convert_charrefs=False)
hpr.feed(html)
elif python_version()==2:
hpr=Hpr()
hpr.feed(unicode(html,'utf-8'))
mv_name=''.join(hpr.data)
hpr.close()
def format_mv_name(mv_name):
#because of MPEG-4 belongs to MP4
if python_version()==2:
"bytes"
mv_name=mv_name.encode('utf-8')
#mv_name_formatted=mv_name.split('\n\t')[-1].split('-')[1]+'--音悦Tai'+'.mp4'
pat=r'(?<=-).*(?=-高清MV)'
m=re.search(pat,mv_name)
mv_name_formatted=m.group(0)+'--音悦Tai'+'.mp4'
#mv_name_formatted=mv_name.split('\n\t-')[1].split('高清MV')[0]+'-音悦Tai'+'.mp4'
return mv_name_formatted
return format_mv_name(mv_name)
RESOLUTION_TOO_LOW='resolution_too_low'
error_dict=dict()
def main(mv_id,output_dir='',resolution='720p'):
resolution_map={'240p':0,'480p':1,'720p':2,'1080p':3}
minumum=resolution_map[resolution]
mv_id=str(mv_id)
url='http://www.yinyuetai.com/insite/get-video-info?flex=true&videoId='+mv_id
timeout=30
headers={'User-Agent':('Mozilla/5.0(Windows NT 6.3)'
'AppleWebKit/537.36 (KHTML,like Gecko)'
'Chrome/39.0.2171.95'
'Safari/537.36'),
'Accept':('text/html,application/xhtml+xml,'
'application/xml;'
'q=0.9,image/webp,*/*;q=0.8')}
req=Request(url,None,headers)
if python_version()==3:
with urlopen(req,None,timeout) as res:
html=res.read()
codec = res.info().get_param('charset', 'utf8')
html = html.decode(codec,errors='ignore')
elif python_version()==2:
res=urlopen(req,None,timeout)
html=res.read()
reg=r'http://\w*?\.yinyuetai\.com/uploads/videos/common.*?(?=&br)'
pattern=re.compile(reg)
findList=re.findall(pattern,html) #find all version of MV
if len(findList)==0:
error_dict[mv_id]=MV_NOT_EXIST
if iswin():
with printDarkRed():
print(MV_NOT_EXIST)
elif islinux():
print(UseStyle(MV_NOT_EXIST,'red'))
else:
print(MV_NOT_EXIST)
return
if len(findList)>=minumum+1:
#print(findList)
mvurl=findList[-1] # :240p 0 :480p 1 :720p 2 :1080p 3
else:
if iswin():
with printDarkRed():
print(RESOLUTION_TOO_LOW)
elif islinux():
print(UseStyle(RESOLUTION_TOO_LOW,'red'))
else:
print(RESOLUTION_TOO_LOW)
return
filename=get_mv_name(mv_id)
if filename==MV_NOT_EXIST:
error_dict[mv_id]=MV_NOT_EXIST
if iswin():
with printDarkRed():
print(MV_NOT_EXIST)
elif islinux():
print(UseStyle(MV_NOT_EXIST,'red'))
else:
print(MV_NOT_EXIST)
return
import traceback
try:
#some shell codec like Cinese Simplied Windows's gbk
# can not decode some unicode character
ps=':) downloading %s \t'
try:
fn_prtable=filename
if iswin():
with printDarkSkyBlue():
print (ps%fn_prtable)
elif islinux():
print(UseStyle(ps%fn_prtable,'cyan'))
else:
print (ps%fn_prtable)
except UnicodeEncodeError:
fn_prtable=filename.encode('utf-8')
if iswin():
with printDarkSkyBlue():
print (ps%fn_prtable)
elif islinux():
print(UseStyle(ps%fn_prtable,'cyan'))
else:
print (ps%fn_prtable)
try:
if python_version()==2:
filename=unicode(filename,'utf-8')
urlretrieve(url=mvurl,
filename=os.path.join(output_dir,filename),
reporthook=report)
except Exception as ex:
error_dict[mv_id]=MV_NOT_EXIST
#print(MV_NOT_EXIST)
if iswin():
with printDarkRed():
traceback.print_exc()
else:
traceback.print_exc()
except Exception as ex:
pts='\n:( Sorry! The action is failed.\n'
if iswin():
with printDarkRed():
traceback.print_exc()
print (pts)
elif islinux():
traceback.print_exc()
print(UseStyle(pts,'red'))
else:
traceback.print_exc()
print (pts)
error_dict[mv_id]=fn_prtable
def mains(mv_ids=set(),filename=None,output_dir='',resolution='720p'):
#print('hi',filename)
mv_ids=set(mv_ids)
if filename!=None:
import os
try:
def format_csv(csv_reader):
iset=set()
[[iset.add(item.strip()) for item in items if item.strip()!=''] \
for items in csv_reader]
return iset
import csv
with open(filename) as f:
r=csv.reader(f)
mv_ids=format_csv(r)
except Exception as ex:
if iswin():
with printDarkRed():
print(ex)
elif islinux():
print(UseStyle(ex.__doc__,'red'))
else:
print(ex)
for (i,mv_id) in enumerate(mv_ids):
pts='\nDownloading ({0:d}/{1:d}) file'.format(i+1,len(mv_ids))
if iswin():
with printDarkSkyBlue():
print(pts)
elif islinux():
print(UseStyle(pts,'cyan'))
else:
print(pts)
main(mv_id,output_dir,resolution)
print()
if len(error_dict)==0:
pts='\n\nDownload complete.'
if iswin():
with printDarkGreen():
print(pts)
elif islinux():
print(UseStyle(pts,'green'))
else:
print(pts)
else:
total_num=len(mv_ids)
failed_num=len(error_dict)
print('\n\n')
pts1='total: \t\t%d'%total_num
pts2='download:\t%d'%total_num-failed_num
pts3='failed:\t\t%d'%failed_num
if iswin():
with printDarkSkyBlue():
print(pts1)
with prinDarkGreen():
print(pts2)
with printDarkRed():
print(pts3)
elif islinux():
print(UseStyle(pts1,'cyan'))
print(UseStyle(pts2,'green'))
print(UseStyle(pts3,'red'))
else:
print(pts1)
print(pts2)
print(pts3)
print()
for key in error_dict:
pts='{0} : {1} failed\t'.format(key,error_dict[key])
if iswin():
with printDarkRed():
print(pts)
elif islinux():
print(UseStyle(pts,'red'))
else:
print(pts)
def interactive():
from argparse import ArgumentParser
parser=ArgumentParser()
parser.add_argument('-f','--file',dest='filename',
help=('pass masses of mv id in form of csv file\n'
'(can not use with mv_ids at the same time)\n'
'ascii comm!! for python2'))
parser.add_argument('mv_ids',nargs='*',
help='pass mv ids(can not use with -f at the same time)')
parser.add_argument('-o','--output_dir',
help='output mv directory')
parser.add_argument('-r','--resolution',default='720p',choices=['240p','480p','720p','1080p'],
help='the minimum resolution you can accept (default 720p)')
args=parser.parse_args().__dict__
#print(args)
if args['output_dir']!=None:
args['output_dir']=os.path.abspath(args['output_dir'])
if not os.path.isdir(os.path.abspath(args['output_dir'])):
raise Exception('arg: -o/--output_dir is not a valid directory')
else:
args['output_dir']=''
if args['filename']==None and args['mv_ids'].__len__()==0:
raise Exception('too few args need -f or mv_ids')
return args
################################################################################
# CMD Color Mode
################################################################################
import platform
import ctypes
import sys
def iswin():
return platform.platform().upper().startswith('WIN')
def islinux():
return platform.platform().upper().startswith('LINUX')
if iswin():
STD_OUTPUT_HANDLE = -11
std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE)
def set_cmd_text_color(color, handle=std_out_handle):
Bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color)
return Bool
FOREGROUND_RED = 0x0c # red.
FOREGROUND_GREEN = 0x0a # green.
FOREGROUND_BLUE = 0x09 # blue.
#reset white
def resetColor():
set_cmd_text_color(FOREGROUND_RED | FOREGROUND_GREEN | FOREGROUND_BLUE)
FOREGROUND_DARKRED = 0x04 # dark red.
FOREGROUND_DARKGREEN = 0x02 # dark green.
FOREGROUND_DARKSKYBLUE = 0x03 # dark skyblue.
class printColor:
def __exit__(self,*args,**kwargs):
resetColor()
class printDarkRed(printColor):
def __enter__(self):
set_cmd_text_color(FOREGROUND_DARKRED)
#暗绿色
#dark green
class printDarkGreen(printColor):
def __enter__(self):
set_cmd_text_color(FOREGROUND_DARKGREEN)
#暗天蓝色
#dark sky blue
class printDarkSkyBlue(printColor):
def __enter__(self):
set_cmd_text_color(FOREGROUND_DARKSKYBLUE)
elif islinux():
STYLE = {
'fore':
{
'red' : 31, # 红色
'green' : 32, # 绿色
'cyan' : 36, # 青蓝色
},
}
def UseStyle(string, fore=''):
fore = '%s' % STYLE['fore'][fore] if fore in STYLE['fore'] else ''
style = ';'.join([s for s in [fore] if s])
style = '\033[%sm' % style if style else ''
return '%s%s' % (style, string)
################################################################################
if __name__=='__main__':
args=interactive()
mains(**args)



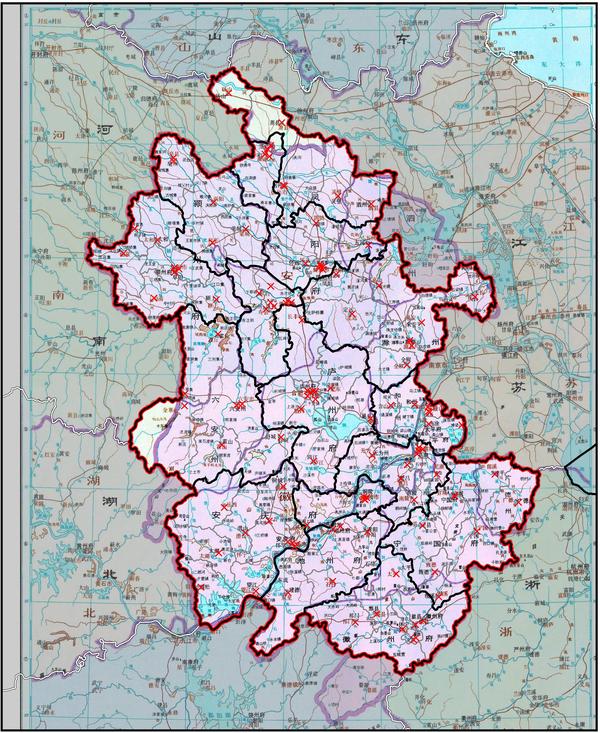
可以用来画地图,如下图清代安徽省与今安徽省对比图:
底图:谭图第八册清代安徽省地图
边界信息由python 读取shapefile得到。
红色边界:今安徽省界
黑色边界:今地市界(三分巢湖,寿县枞阳县已更新)
灰色边界:今区县界
亮部:清代不归安徽省,今划归
暗部:清代划归安徽省,今划出
由于没有乡镇级行政区的shapefile,对更小的行政区划变化还不能精确掌握(如六安市新成立的叶集区,原叶集镇)。
红叉代表今安徽省所有县级以上行政区经纬度位置,通过python爬虫得到。
底图:谭图第八册清代安徽省地图
边界信息由python 读取shapefile得到。
红色边界:今安徽省界
黑色边界:今地市界(三分巢湖,寿县枞阳县已更新)
灰色边界:今区县界
亮部:清代不归安徽省,今划归
暗部:清代划归安徽省,今划出
由于没有乡镇级行政区的shapefile,对更小的行政区划变化还不能精确掌握(如六安市新成立的叶集区,原叶集镇)。
红叉代表今安徽省所有县级以上行政区经纬度位置,通过python爬虫得到。







对我来说学习Python完全是一种偶然,就职在杭州,因为工作的缘故,经常会关注浙江省内的高速公路路况信息。
当然,现在这种路况事件信息可以很轻松的随时查询到,渠道也挺多,电话、网站、APP、微信等等。
但我的需求比较特别。
首先,目前已有的查询渠道都是定向查询,需要用户先指定要查询的路名,然后它会把这条高速的路况信息一条一条的列出来。但我希望是页面一打开,就告诉我全部的路况事件信息。
然后,不要无关紧要的信息。比如今天几点到几点,K多少加多少有施工。这种信息其实很无聊。开车上高速前,你会因为这么个施工信息而考虑改变今天的行程么?当然,如果因为这个施工而造成了这个路段的拥堵,那是必须要提醒的。
找来找去,没找到符合我需求的,所以想着就只有自己动手了。目标是一个简单的网页,专门用来实现以上两个需求。
交待一下背景,交通工程专业,2000年毕业,大学里学过C和Foxpro,这是仅有的一点编程实践。
欲善其事,先利其器,本来应该交待一下选Python的前因后果,可是写不出来,因为根本就没有原因,也许只是因为看着眼熟吧。过程其实相当折腾,毕竟有毛20年没写过程序,一切几乎都是从零开始,虽然全程碰到的问题用搜索引擎都解决了,但反反复复在所难免,记忆最深刻的是编码问题,一度想放弃算了,搁置了将近三个星期,还是不甘心,又硬着头皮到处寻找问题原因,总算解决了。可是总结下来,Python确实让我非常惊喜。
步骤大致如下:
一、先写个爬虫,每5分钟去指定网站把高速公路路况事件信息抓下来。
二、把满足前提条件的事件信息保存下来。
三、展示出来。
程序部署在新浪的SAE,没有开数据库,用Memcached保存事件信息,反正每5分钟更新,也没作长期保存的打算。
网址:http://www.62gaosu.com/,为什么要在高速前面加62这个数字呢?因为在杭州话里, 62这个数字有着相当的含义,表示的是呆子、傻的意思,所以就是想表达不用动脑筋,打开就能用的意思。在手机上打开的效果是这样的:
贴上原代码,因为没有系统性的学习过,纯粹为了解决自己的特定需求而现查现改现写,莫名其妙之处,请一笑了之。为减少不必要的麻烦,将爬虫目标网址用星号代替了去。
当然,现在这种路况事件信息可以很轻松的随时查询到,渠道也挺多,电话、网站、APP、微信等等。
但我的需求比较特别。
首先,目前已有的查询渠道都是定向查询,需要用户先指定要查询的路名,然后它会把这条高速的路况信息一条一条的列出来。但我希望是页面一打开,就告诉我全部的路况事件信息。
然后,不要无关紧要的信息。比如今天几点到几点,K多少加多少有施工。这种信息其实很无聊。开车上高速前,你会因为这么个施工信息而考虑改变今天的行程么?当然,如果因为这个施工而造成了这个路段的拥堵,那是必须要提醒的。
找来找去,没找到符合我需求的,所以想着就只有自己动手了。目标是一个简单的网页,专门用来实现以上两个需求。
交待一下背景,交通工程专业,2000年毕业,大学里学过C和Foxpro,这是仅有的一点编程实践。
欲善其事,先利其器,本来应该交待一下选Python的前因后果,可是写不出来,因为根本就没有原因,也许只是因为看着眼熟吧。过程其实相当折腾,毕竟有毛20年没写过程序,一切几乎都是从零开始,虽然全程碰到的问题用搜索引擎都解决了,但反反复复在所难免,记忆最深刻的是编码问题,一度想放弃算了,搁置了将近三个星期,还是不甘心,又硬着头皮到处寻找问题原因,总算解决了。可是总结下来,Python确实让我非常惊喜。
步骤大致如下:
一、先写个爬虫,每5分钟去指定网站把高速公路路况事件信息抓下来。
二、把满足前提条件的事件信息保存下来。
三、展示出来。
程序部署在新浪的SAE,没有开数据库,用Memcached保存事件信息,反正每5分钟更新,也没作长期保存的打算。
网址:http://www.62gaosu.com/,为什么要在高速前面加62这个数字呢?因为在杭州话里, 62这个数字有着相当的含义,表示的是呆子、傻的意思,所以就是想表达不用动脑筋,打开就能用的意思。在手机上打开的效果是这样的:

贴上原代码,因为没有系统性的学习过,纯粹为了解决自己的特定需求而现查现改现写,莫名其妙之处,请一笑了之。为减少不必要的麻烦,将爬虫目标网址用星号代替了去。
import sae, urllib, urllib2, json, pylibmc
from werkzeug.wrappers import Request
def gsspider():
url = 'http://******'
#事件列表
causename = [u'缓行', u'缓慢', u'分流', u'排队', u'管制', u'大流量']
#定义一个空的路况事件列表
LqTxtList = []
for roadid in range(1, 51):
values = {"roadlineid" : str(roadid)}
request = urllib2.Request(url, urllib.urlencode(values))
html = urllib2.urlopen(request, timeout = 1).read()
html = json.loads(html)
data = html['data']
for i in range(len(data)):
reportout = data[i]['reportout']
for cause in range(len(causename)):
#路况事件信息内只有含有事件列表内的一个元素
#就将该条信息写入路况事件列表内
if causename[cause] in reportout:
LqTxtList.append(reportout)
break
#按时间倒序,然后输出成路况事件信息字符串
LqInfoList = sorted(LqTxtList, reverse=True)
LqInfoTxt = ''
for i in range(len(LqInfoList)):
LqInfoTxt = LqInfoTxt + LqInfoList[i] + '<br><br>'
#如果文本长度小于5,认为目前无异常路况
if len(LqInfoTxt) < 5:
LqInfoTxt = u'目前浙江省内高速公路通行正常。'
#初始化memcache
mc = pylibmc.Client()
#将符合条件的路况事件信息字符串存入memcache
mc.set('info', LqInfoTxt)
def app(environ, start_response):
#定义输出样式
htmlstyle = '''
<html>
<head>
<title>六耳高速网 | 浙江高速路况</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>%s<br></body>
<footer>浙ICP备16003482号</footer>
</html>'''
#如果访问的地址中含有spider,则判断是cron计划任务,执行gsspider
if "spider" in Request(environ).url:
gsspider()
#否则认为是用户在浏览器端发起的访问,输出结果
else:
mc = pylibmc.Client()
value = mc.get('info')
output = htmlstyle % value.encode('utf-8')
status = "200 OK"
response_headers = [
("Content-type", "text/html; charset = utf-8"),
("Content-Length", str(len(output)))
]
start_response(status, response_headers)
return [output]
application = sae.create_wsgi_app(app)








在爬虫上用的比较多,偶尔还有些小工具
1、某次看到知乎上有人应excel画画,然后自己写了个照片转为excel的小东西,每个单元格当作一个像素点,然而并没有什么卵用。
2、接入机器人,终端聊天。
并没有什么卵用
3、爬取想要的东西,工作要求的,还有自己想要的,比如网上大量的图片,然后几行代码用flask加个瀑布流随机展示二十张,手机连上wifi就可以看到没有广告的高质量的你懂的图片。
4、大部分重复劳动,比如每天十点一分(上班时间)把该查询的该统计的做完给我发一封上一天的统计综述,感觉自己有一班小弟给自己汇报工作 (手动微笑
5、随手终端里面ipython处理一些简单的小任务,比如文本文件格式化,查查重,当计算器什么的。
1、某次看到知乎上有人应excel画画,然后自己写了个照片转为excel的小东西,每个单元格当作一个像素点,然而并没有什么卵用。
2、接入机器人,终端聊天。

并没有什么卵用
3、爬取想要的东西,工作要求的,还有自己想要的,比如网上大量的图片,然后几行代码用flask加个瀑布流随机展示二十张,手机连上wifi就可以看到没有广告的高质量的你懂的图片。
4、大部分重复劳动,比如每天十点一分(上班时间)把该查询的该统计的做完给我发一封上一天的统计综述,感觉自己有一班小弟给自己汇报工作 (手动微笑
5、随手终端里面ipython处理一些简单的小任务,比如文本文件格式化,查查重,当计算器什么的。
















