1)
Node.js 教程

简单的说 Node.js 就是运行在服务端的 JavaScript。
Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台。
Node.js是一个事件驱动I/O服务端JavaScript环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
谁适合阅读本教程?
如果你是一个前端程序员,你不懂得像PHP、Python或Ruby等动态编程语言,然后你想创建自己的服务,那么Node.js是一个非常好的选择。
Node.js 是运行在服务端的 JavaScript,如果你熟悉Javascript,那么你将会很容易的学会Node.js。
当然,如果你是后端程序员,想部署一些高性能的服务,那么学习Node.js也是一个非常好的选择。
学习本教程前你需要了解
在继续本教程之前,你应该了解一些基本的计算机编程术语。如果你学习过Javascript,PHP,Java等编程语言,将有助于你更快的了解Node.js编程。
使用的版本
我们可以使用以下命令来查看当前的 Node 版本:
$ node -v
v4.4.3
注意:不同版本间可能是有差异的。
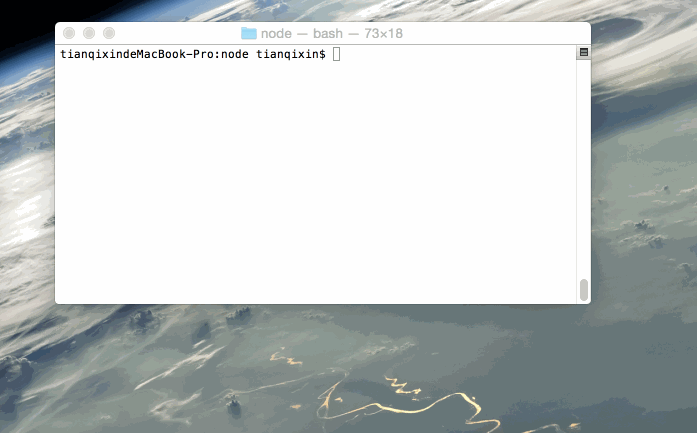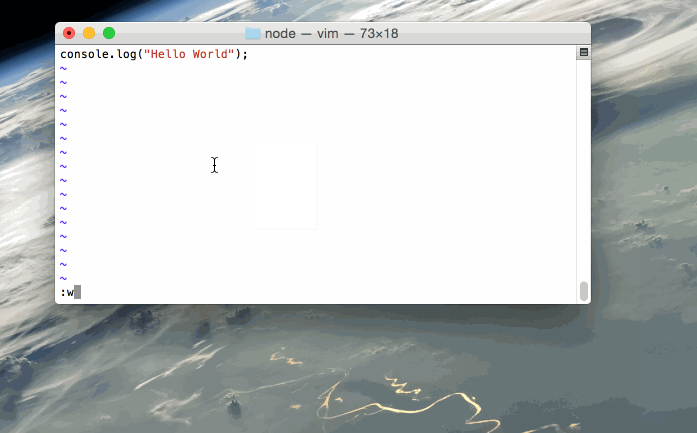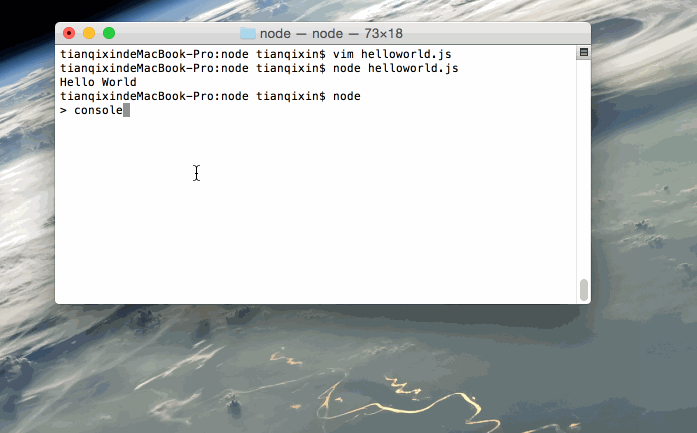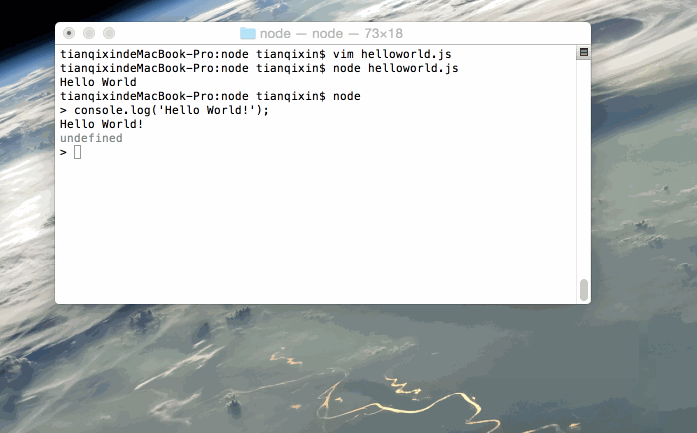
第一个Node.js程序:Hello World!
脚本模式
以下是我们的第一个Node.js程序:
实例
console.log("Hello World");
运行实例 »保存该文件,文件名为 helloworld.js, 并通过 node命令来执行:
node helloworld.js
程序执行后,正常的话,就会在终端输出 Hello World。
交互模式
打开终端,键入node进入命令交互模式,可以输入一条代码语句后立即执行并显示结果,例如:
$ node
> console.log('Hello World!');
Hello World!
Gif 实例演示
接下来我们通过 Gif 图为大家演示实例操作:
2)Node.js 安装配置
本章节我们将向大家介绍在window和Linux上安装Node.js的方法。
本安装教程以Node.js v4.4.3 LTS(长期支持版本)版本为例。
Node.js安装包及源码下载地址为:https://nodejs.org/en/download/。

你可以根据不同平台系统选择你需要的Node.js安装包。
Node.js 历史版本下载地址:https://nodejs.org/dist/
注意:Linux上安装Node.js需要安装Python 2.6 或 2.7 ,不建议安装Python 3.0以上版本。
Window 上安装Node.js
你可以采用以下两种方式来安装。
1、Windows 安装包(.msi)
32 位安装包下载地址 : https://nodejs.org/dist/v4.4.3/node-v4.4.3-x86.msi
64 位安装包下载地址 : https://nodejs.org/dist/v4.4.3/node-v4.4.3-x64.msi
本文实例以 v0.10.26 版本为例,其他版本类似, 安装步骤:
步骤 1 : 双击下载后的安装包 v0.10.26,如下所示:
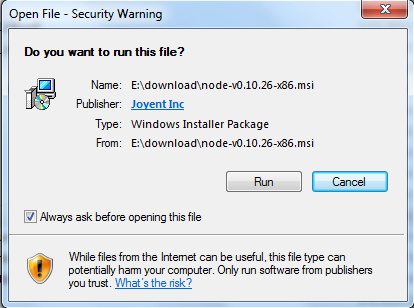
步骤 2 : 点击以上的Run(运行),将出现如下界面:
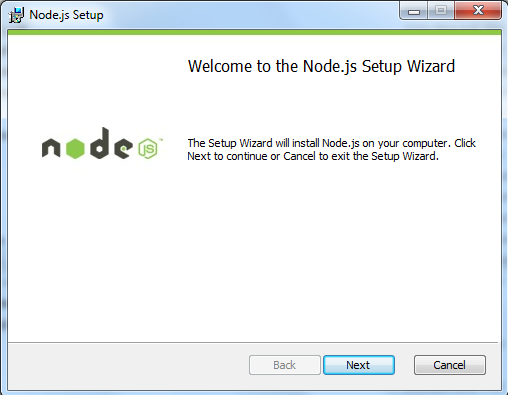
步骤 3 : 勾选接受协议选项,点击 next(下一步) 按钮 :
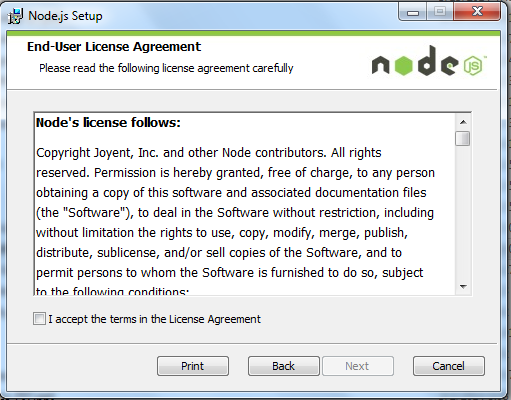
步骤 4 : Node.js默认安装目录为 "C:\Program Files\nodejs\" , 你可以修改目录,并点击 next(下一步):
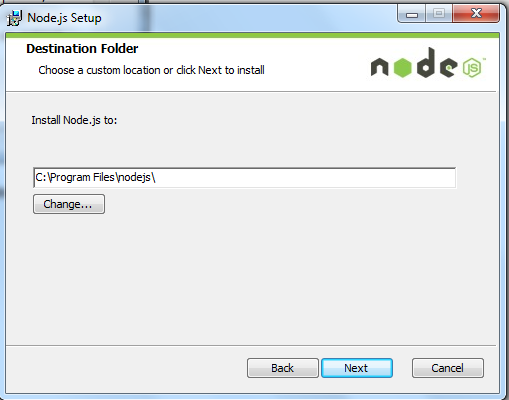
步骤 5 : 点击树形图标来选择你需要的安装模式 , 然后点击下一步 next(下一步)
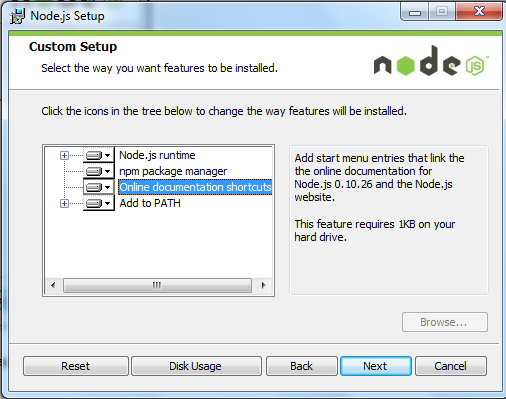
步骤 6 :点击 Install(安装) 开始安装Node.js。你也可以点击 Back(返回)来修改先前的配置。 然后并点击 next(下一步):
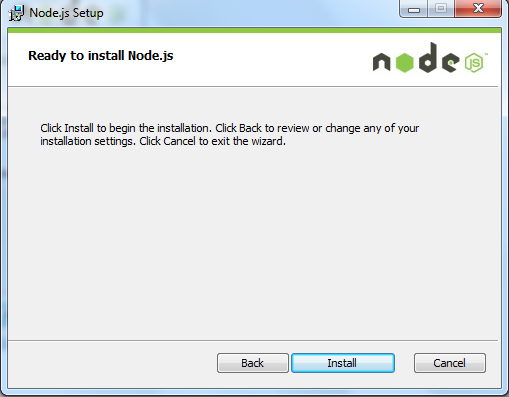
安装过程:
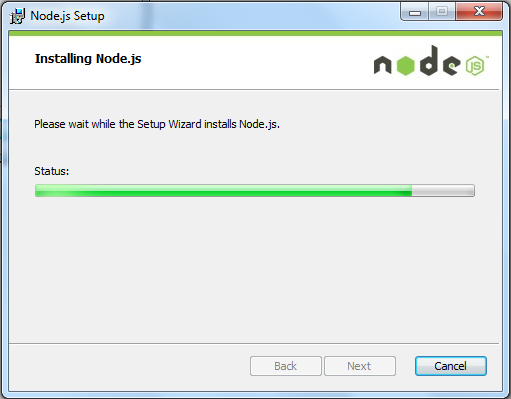
点击 Finish(完成)按钮退出安装向导。
检测PATH环境变量是否配置了Node.js,点击开始=》运行=》输入"cmd" => 输入命令"path",输出如下结果:
PATH=C:\oraclexe\app\oracle\product\10.2.0\server\bin;C:\Windows\system32;
C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;
c:\python32\python;C:\MinGW\bin;C:\Program Files\GTK2-Runtime\lib;
C:\Program Files\MySQL\MySQL Server 5.5\bin;C:\Program Files\nodejs\;
C:\Users\rg\AppData\Roaming\npm
我们可以看到环境变量中已经包含了C:\Program Files\nodejs\
检查Node.js版本
2、Windows 二进制文件 (.exe)安装
32 位安装包下载地址 : http://nodejs.org/dist/v0.10.26/node.exe
64 位安装包下载地址 : http://nodejs.org/dist/v0.10.26/x64/node.exe
安装步骤
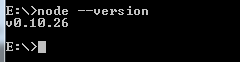
步骤 1 : 双击下载的安装包 Node.exe ,将出现如下界面 :
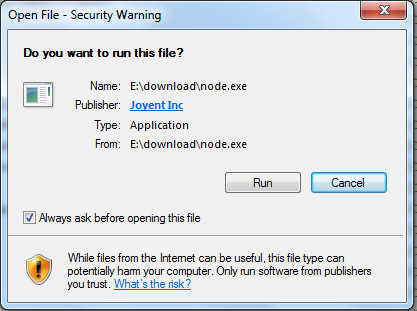
点击 Run(运行)按钮将出现命令行窗口:
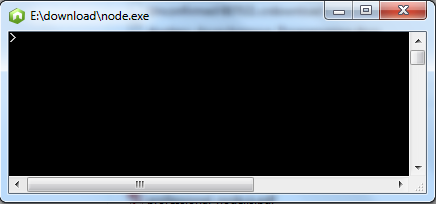
版本测试
进入 node.exe 所在的目录,如下所示:
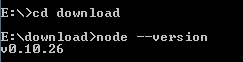
如果你获得以上输出结果,说明你已经成功安装了Node.js。
Ubuntu 上安装 Node.js
Node.js 源码安装
以下部分我们将介绍在Ubuntu Linux下安装 Node.js 。 其他的Linux系统,如Centos等类似如下安装步骤。
在 Github 上获取 Node.js 源码:
$ sudo git clone https://github.com/nodejs/node.git
Cloning into 'node'...
修改目录权限:
$ sudo chmod -R 755 node
使用 ./configure 创建编译文件,并按照:
$ cd node
$ sudo ./configure
$ sudo make
$ sudo make install
查看 node 版本:
$ node --version
v0.10.25
Ubuntu apt-get命令安装
命令格式如下:
sudo apt-get install nodejs
sudo apt-get install npm
CentOS 下安装 Node.js
我采用的二进制安装,不需要编译源代码 v10.24.1
https://nodejs.org/download/release/v10.24.1/
https://nodejs.org/download/release/v10.24.1/node-v10.24.1-linux-x64.tar.gz
遇到问题 见 /node-admin/20723
1、下载源码,你需要在https://nodejs.org/en/download/下载最新的Nodejs版本,本文以v0.10.24为例:
cd /usr/local/src/
wget http://nodejs.org/dist/v0.10.24/node-v0.10.24.tar.gz
2、解压源码
tar zxvf node-v0.10.24.tar.gz
3、 编译安装
cd node-v0.10.24
./configure --prefix=/usr/local/node/0.10.24
make
make install
4、 配置NODE_HOME,进入profile编辑环境变量
vim /etc/profile
设置nodejs环境变量,在 export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL 一行的上面添加如下内容:
#set for nodejs
export NODE_HOME=/usr/local/node/0.10.24
export PATH=$NODE_HOME/bin:$PATH
:wq保存并退出,编译/etc/profile 使配置生效
source /etc/profile
验证是否安装配置成功
node -v
输出 v0.10.24 表示配置成功
npm模块安装路径
/usr/local/node/0.10.24/lib/node_modules/
注:Nodejs 官网提供了编译好的Linux二进制包,你也可以下载下来直接应用。
3)
Node.js 创建第一个应用
如果我们使用PHP来编写后端的代码时,需要Apache 或者 Nginx 的HTTP 服务器,并配上 mod_php5 模块和php-cgi。
从这个角度看,整个"接收 HTTP 请求并提供 Web 页面"的需求根本不需 要 PHP 来处理。
不过对 Node.js 来说,概念完全不一样了。使用 Node.js 时,我们不仅仅 在实现一个应用,同时还实现了整个 HTTP 服务器。事实上,我们的 Web 应用以及对应的 Web 服务器基本上是一样的。
在我们创建 Node.js 第一个 "Hello, World!" 应用前,让我们先了解下 Node.js 应用是由哪几部分组成的:
引入 required 模块:我们可以使用 require 指令来载入 Node.js 模块。
创建服务器:服务器可以监听客户端的请求,类似于 Apache 、Nginx 等 HTTP 服务器。
接收请求与响应请求 服务器很容易创建,客户端可以使用浏览器或终端发送 HTTP 请求,服务器接收请求后返回响应数据。
创建 Node.js 应用
步骤一、引入 required 模块
我们使用 require 指令来载入 http 模块,并将实例化的 HTTP 赋值给变量 http,实例如下:
var http = require("http");
步骤二、创建服务器
接下来我们使用 http.createServer() 方法创建服务器,并使用 listen 方法绑定 8888 端口。 函数通过 request, response 参数来接收和响应数据。
实例如下,在你项目的根目录下创建一个叫 server.js 的文件,并写入以下代码:
var http = require('http');
http.createServer(function (request, response) {
// 发送 HTTP 头部
// HTTP 状态值: 200 : OK
// 内容类型: text/plain
response.writeHead(200, {'Content-Type': 'text/plain'});
// 发送响应数据 "Hello World"
response.end('Hello World\n');
}).listen(8888);
// 终端打印如下信息
console.log('Server running at http://127.0.0.1:8888/');
以上代码我们完成了一个可以工作的 HTTP 服务器。
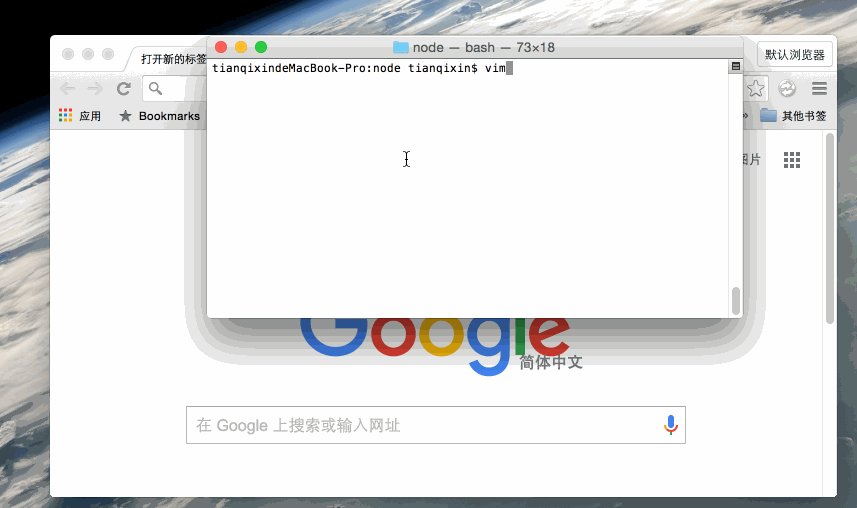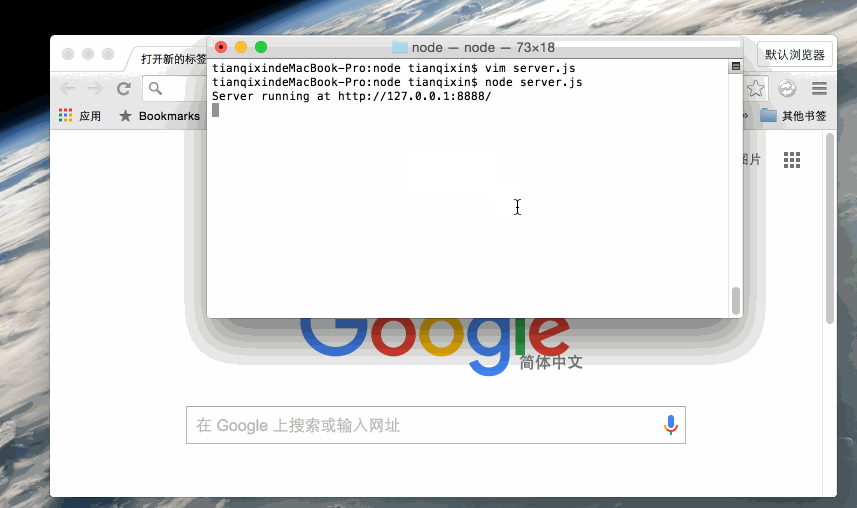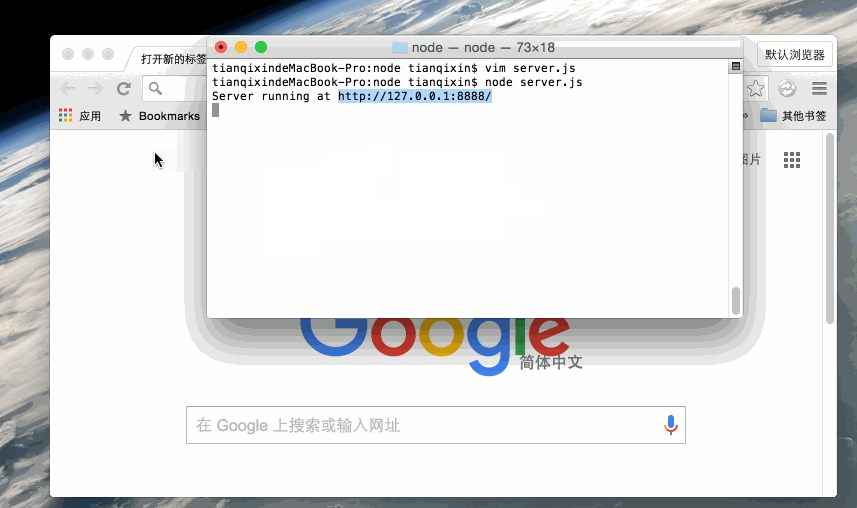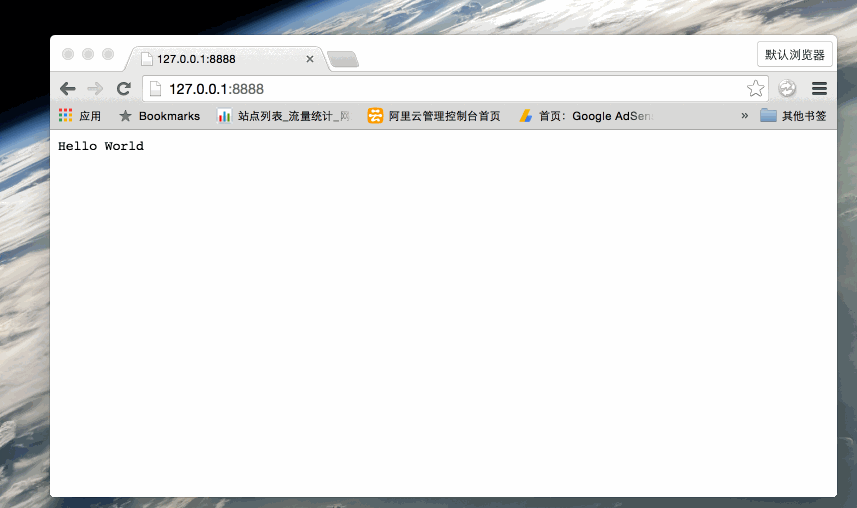
使用 node 命令执行以上的代码:
node server.js
Server running at http://127.0.0.1:8888/

接下来,打开浏览器访问 http://127.0.0.1:8888/,你会看到一个写着 "Hello World"的网页。
分析Node.js 的 HTTP 服务器:
Gif 实例演示
接下来我们通过 Gif 图为大家演示实例操作:
4)
NPM 使用介绍
NPM是随同NodeJS一起安装的包管理工具,能解决NodeJS代码部署上的很多问题,常见的使用场景有以下几种:
允许用户从NPM服务器下载别人编写的第三方包到本地使用。
允许用户从NPM服务器下载并安装别人编写的命令行程序到本地使用。
允许用户将自己编写的包或命令行程序上传到NPM服务器供别人使用。
由于新版的nodejs已经集成了npm,所以之前npm也一并安装好了。同样可以通过输入 "npm -v" 来测试是否成功安装。命令如下,出现版本提示表示安装成功:
$ npm -v
2.3.0
如果你安装的是旧版本的 npm,可以很容易得通过 npm 命令来升级,命令如下:
$ sudo npm install npm -g
/usr/local/bin/npm -> /usr/local/lib/node_modules/npm/bin/npm-cli.js
npm@2.14.2 /usr/local/lib/node_modules/npm
如果是 Window 系统使用以下命令即可:
npm install npm -g
使用淘宝镜像的命令:
cnpm install npm -g
使用 npm 命令安装模块
npm 安装 Node.js 模块语法格式如下:
$ npm install <Module Name>
以下实例,我们使用 npm 命令安装常用的 Node.js web框架模块 express:
$ npm install express
安装好之后,express 包就放在了工程目录下的 node_modules 目录中,因此在代码中只需要通过 require('express') 的方式就好,无需指定第三方包路径。
var express = require('express');
全局安装与本地安装
npm 的包安装分为本地安装(local)、全局安装(global)两种,从敲的命令行来看,差别只是有没有-g而已,比如
npm install express # 本地安装
npm install express -g # 全局安装
如果出现以下错误:
npm err! Error: connect ECONNREFUSED 127.0.0.1:8087
解决办法为:
$ npm config set proxy null
本地安装
全局安装
如果你希望具备两者功能,则需要在两个地方安装它或使用 npm link。
接下来我们使用全局方式安装 express
$ npm install express -g
安装过程输出如下内容,第一行输出了模块的版本号及安装位置。
express@4.13.3 node_modules/express
├── escape-html@1.0.2
├── range-parser@1.0.2
├── merge-descriptors@1.0.0
├── array-flatten@1.1.1
├── cookie@0.1.3
├── utils-merge@1.0.0
├── parseurl@1.3.0
├── cookie-signature@1.0.6
├── methods@1.1.1
├── fresh@0.3.0
├── vary@1.0.1
├── path-to-regexp@0.1.7
├── content-type@1.0.1
├── etag@1.7.0
├── serve-static@1.10.0
├── content-disposition@0.5.0
├── depd@1.0.1
├── qs@4.0.0
├── finalhandler@0.4.0 (unpipe@1.0.0)
├── on-finished@2.3.0 (ee-first@1.1.1)
├── proxy-addr@1.0.8 (forwarded@0.1.0, ipaddr.js@1.0.1)
├── debug@2.2.0 (ms@0.7.1)
├── type-is@1.6.8 (media-typer@0.3.0, mime-types@2.1.6)
├── accepts@1.2.12 (negotiator@0.5.3, mime-types@2.1.6)
└── send@0.13.0 (destroy@1.0.3, statuses@1.2.1, ms@0.7.1, mime@1.3.4, http-errors@1.3.1)
查看安装信息
你可以使用以下命令来查看所有全局安装的模块:
$ npm list -g
├─┬ cnpm@4.3.2
│ ├── auto-correct@1.0.0
│ ├── bagpipe@0.3.5
│ ├── colors@1.1.2
│ ├─┬ commander@2.9.0
│ │ └── graceful-readlink@1.0.1
│ ├─┬ cross-spawn@0.2.9
│ │ └── lru-cache@2.7.3
……
如果要查看某个模块的版本号,可以使用命令如下:
$ npm list grunt
projectName@projectVersion /path/to/project/folder
└── grunt@0.4.1
使用 package.json
package.json 位于模块的目录下,用于定义包的属性。接下来让我们来看下 express 包的 package.json 文件,位于 node_modules/express/package.json 内容:
{
"name": "express",
"description": "Fast, unopinionated, minimalist web framework",
"version": "4.13.3",
"author": {
"name": "TJ Holowaychuk",
"email": "tj@vision-media.ca"
},
"contributors": [
{
"name": "Aaron Heckmann",
"email": "aaron.heckmann+github@gmail.com"
},
{
"name": "Ciaran Jessup",
"email": "ciaranj@gmail.com"
},
{
"name": "Douglas Christopher Wilson",
"email": "doug@somethingdoug.com"
},
{
"name": "Guillermo Rauch",
"email": "rauchg@gmail.com"
},
{
"name": "Jonathan Ong",
"email": "me@jongleberry.com"
},
{
"name": "Roman Shtylman",
"email": "shtylman+expressjs@gmail.com"
},
{
"name": "Young Jae Sim",
"email": "hanul@hanul.me"
}
],
"license": "MIT",
"repository": {
"type": "git",
"url": "git+https://github.com/strongloop/express.git"
},
"homepage": "http://expressjs.com/",
"keywords": [
"express",
"framework",
"sinatra",
"web",
"rest",
"restful",
"router",
"app",
"api"
],
"dependencies": {
"accepts": "~1.2.12",
"array-flatten": "1.1.1",
"content-disposition": "0.5.0",
"content-type": "~1.0.1",
"cookie": "0.1.3",
"cookie-signature": "1.0.6",
"debug": "~2.2.0",
"depd": "~1.0.1",
"escape-html": "1.0.2",
"etag": "~1.7.0",
"finalhandler": "0.4.0",
"fresh": "0.3.0",
"merge-descriptors": "1.0.0",
"methods": "~1.1.1",
"on-finished": "~2.3.0",
"parseurl": "~1.3.0",
"path-to-regexp": "0.1.7",
"proxy-addr": "~1.0.8",
"qs": "4.0.0",
"range-parser": "~1.0.2",
"send": "0.13.0",
"serve-static": "~1.10.0",
"type-is": "~1.6.6",
"utils-merge": "1.0.0",
"vary": "~1.0.1"
},
"devDependencies": {
"after": "0.8.1",
"ejs": "2.3.3",
"istanbul": "0.3.17",
"marked": "0.3.5",
"mocha": "2.2.5",
"should": "7.0.2",
"supertest": "1.0.1",
"body-parser": "~1.13.3",
"connect-redis": "~2.4.1",
"cookie-parser": "~1.3.5",
"cookie-session": "~1.2.0",
"express-session": "~1.11.3",
"jade": "~1.11.0",
"method-override": "~2.3.5",
"morgan": "~1.6.1",
"multiparty": "~4.1.2",
"vhost": "~3.0.1"
},
"engines": {
"node": ">= 0.10.0"
},
"files": [
"LICENSE",
"History.md",
"Readme.md",
"index.js",
"lib/"
],
"scripts": {
"test": "mocha --require test/support/env --reporter spec --bail --check-leaks test/ test/acceptance/",
"test-ci": "istanbul cover node_modules/mocha/bin/_mocha --report lcovonly -- --require test/support/env --reporter spec --check-leaks test/ test/acceptance/",
"test-cov": "istanbul cover node_modules/mocha/bin/_mocha -- --require test/support/env --reporter dot --check-leaks test/ test/acceptance/",
"test-tap": "mocha --require test/support/env --reporter tap --check-leaks test/ test/acceptance/"
},
"gitHead": "ef7ad681b245fba023843ce94f6bcb8e275bbb8e",
"bugs": {
"url": "https://github.com/strongloop/express/issues"
},
"_id": "express@4.13.3",
"_shasum": "ddb2f1fb4502bf33598d2b032b037960ca6c80a3",
"_from": "express@*",
"_npmVersion": "1.4.28",
"_npmUser": {
"name": "dougwilson",
"email": "doug@somethingdoug.com"
},
"maintainers": [
{
"name": "tjholowaychuk",
"email": "tj@vision-media.ca"
},
{
"name": "jongleberry",
"email": "jonathanrichardong@gmail.com"
},
{
"name": "dougwilson",
"email": "doug@somethingdoug.com"
},
{
"name": "rfeng",
"email": "enjoyjava@gmail.com"
},
{
"name": "aredridel",
"email": "aredridel@dinhe.net"
},
{
"name": "strongloop",
"email": "callback@strongloop.com"
},
{
"name": "defunctzombie",
"email": "shtylman@gmail.com"
}
],
"dist": {
"shasum": "ddb2f1fb4502bf33598d2b032b037960ca6c80a3",
"tarball": "http://registry.npmjs.org/express/-/express-4.13.3.tgz"
},
"directories": {},
"_resolved": "https://registry.npmjs.org/express/-/express-4.13.3.tgz",
"readme": "ERROR: No README data found!"
}
Package.json 属性说明
name - 包名。
version - 包的版本号。
description - 包的描述。
homepage - 包的官网 url 。
author - 包的作者姓名。
contributors - 包的其他贡献者姓名。
dependencies - 依赖包列表。如果依赖包没有安装,npm 会自动将依赖包安装在 node_module 目录下。
repository - 包代码存放的地方的类型,可以是 git 或 svn,git 可在 Github 上。
main - main 字段是一个模块ID,它是一个指向你程序的主要项目。就是说,如果你包的名字叫 express,然后用户安装它,然后require("express")。
keywords - 关键字
卸载模块
我们可以使用以下命令来卸载 Node.js 模块。
$ npm uninstall express
卸载后,你可以到 /node_modules/ 目录下查看包是否还存在,或者使用以下命令查看:
$ npm ls
更新模块
我们可以使用以下命令更新模块:
$ npm update express
搜索模块
使用以下来搜索模块:
$ npm search express
创建模块
创建模块,package.json 文件是必不可少的。我们可以使用 NPM 生成 package.json 文件,生成的文件包含了基本的结果。
$ npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help json` for definitive documentation on these fields
and exactly what they do.
Use `npm install <pkg> --save` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
name: (node_modules) runoob # 模块名
version: (1.0.0)
description: Node.js 测试模块(www.runoob.com) # 描述
entry point: (index.js)
test command: make test
git repository: https://github.com/runoob/runoob.git # Github 地址
keywords:
author:
license: (ISC)
About to write to ……/node_modules/package.json: # 生成地址
{
"name": "runoob",
"version": "1.0.0",
"description": "Node.js 测试模块(www.runoob.com)",
……
}
Is this ok? (yes) yes
以上的信息,你需要根据你自己的情况输入。在最后输入 "yes" 后会生成 package.json 文件。
接下来我们可以使用以下命令在 npm 资源库中注册用户(使用邮箱注册):
$ npm adduser
Username: mcmohd
Password:
Email: (this IS public) mcmohd@gmail.com
接下来我们就用以下命令来发布模块:
$ npm publish
如果你以上的步骤都操作正确,你就可以跟其他模块一样使用 npm 来安装。
版本号
使用NPM下载和发布代码时都会接触到版本号。NPM使用语义版本号来管理代码,这里简单介绍一下。
语义版本号分为X.Y.Z三位,分别代表主版本号、次版本号和补丁版本号。当代码变更时,版本号按以下原则更新。
如果只是修复bug,需要更新Z位。
如果是新增了功能,但是向下兼容,需要更新Y位。
如果有大变动,向下不兼容,需要更新X位。
版本号有了这个保证后,在申明第三方包依赖时,除了可依赖于一个固定版本号外,还可依赖于某个范围的版本号。例如"argv": "0.0.x"表示依赖于0.0.x系列的最新版argv。
NPM支持的所有版本号范围指定方式可以查看官方文档。
NPM 常用命令
除了本章介绍的部分外,NPM还提供了很多功能,package.json里也有很多其它有用的字段。
除了可以在npmjs.org/doc/查看官方文档外,这里再介绍一些NPM常用命令。
NPM提供了很多命令,例如install和publish,使用npm help可查看所有命令。
NPM提供了很多命令,例如install和publish,使用npm help可查看所有命令。
使用npm help <command>可查看某条命令的详细帮助,例如npm help install。
在package.json所在目录下使用npm install . -g可先在本地安装当前命令行程序,可用于发布前的本地测试。
使用npm update <package>可以把当前目录下node_modules子目录里边的对应模块更新至最新版本。
使用npm update <package> -g可以把全局安装的对应命令行程序更新至最新版。
使用npm cache clear可以清空NPM本地缓存,用于对付使用相同版本号发布新版本代码的人。
使用npm unpublish <package>@<version>可以撤销发布自己发布过的某个版本代码。
使用淘宝 NPM 镜像
大家都知道国内直接使用 npm 的官方镜像是非常慢的,这里推荐使用淘宝 NPM 镜像。
淘宝 NPM 镜像是一个完整 npmjs.org 镜像,你可以用此代替官方版本(只读),同步频率目前为 10分钟 一次以保证尽量与官方服务同步。
你可以使用淘宝定制的 cnpm (gzip 压缩支持) 命令行工具代替默认的 npm:
$ npm install -g cnpm --registry=https://registry.npm.taobao.org
这样就可以使用 cnpm 命令来安装模块了:
$ cnpm install [name]
更多信息可以查阅:http://npm.taobao.org/。
5)
Node.js REPL(交互式解释器)
Node.js REPL(Read Eval Print Loop:交互式解释器) 表示一个电脑的环境,类似 Window 系统的终端或 Unix/Linux shell,我们可以在终端中输入命令,并接收系统的响应。
Node 自带了交互式解释器,可以执行以下任务:
Node 的交互式解释器可以很好的调试 Javascript 代码。
开始学习 REPL
我们可以输入以下命令来启动 Node 的终端:
$ node
>
这时我们就可以在 > 后输入简单的表达式,并按下回车键来计算结果。
简单的表达式运算
接下来让我们在 Node.js REPL 的命令行窗口中执行简单的数学运算:
$ node
> 1 +4
5
> 5 / 2
2.5
> 3 * 6
18
> 4 - 1
3
> 1 + ( 2 * 3 ) - 4
3
>
使用变量
你可以将数据存储在变量中,并在你需要的时候使用它。
变量声明需要使用 var 关键字,如果没有使用 var 关键字变量会直接打印出来。
使用 var 关键字的变量可以使用 console.log() 来输出变量。
$ node
> x = 10
10
> var y = 10
undefined
> x + y
20
> console.log("Hello World")
Hello World
undefined
> console.log("www.runoob.com")
www.runoob.com
undefined
多行表达式
Node REPL 支持输入多行表达式,这就有点类似 JavaScript。接下来让我们来执行一个 do-while 循环:
$ node
> var x = 0
undefined
> do {
... x++;
... console.log("x: " + x);
... } while ( x < 5 );
x: 1
x: 2
x: 3
x: 4
x: 5
undefined
>
... 三个点的符号是系统自动生成的,你回车换行后即可。Node 会自动检测是否为连续的表达式。
下划线(_)变量
你可以使用下划线(_)获取表达式的运算结果:
$ node
> var x = 10
undefined
> var y = 20
undefined
> x + y
30
> var sum = _
undefined
> console.log(sum)
30
undefined
>
REPL 命令
ctrl + c - 退出当前终端。
ctrl + c 按下两次 - 退出 Node REPL。
ctrl + d - 退出 Node REPL.
向上/向下 键 - 查看输入的历史命令
tab 键 - 列出当前命令
.help - 列出使用命令
.break - 退出多行表达式
.clear - 退出多行表达式
.save filename - 保存当前的 Node REPL 会话到指定文件
.load filename - 载入当前 Node REPL 会话的文件内容。
停止 REPL
前面我们已经提到按下两次 ctrl + c 键就能退出 REPL:
$ node
>
(^C again to quit)
>
Gif 实例演示
接下来我们通过 Gif 图为大家演示实例操作:
6)
Node.js 回调函数
Node.js 异步编程的直接体现就是回调。
异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。
回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。
例如,我们可以一边读取文件,一边执行其他命令,在文件读取完成后,我们将文件内容作为回调函数的参数返回。这样在执行代码时就没有阻塞或等待文件 I/O 操作。这就大大提高了 Node.js 的性能,可以处理大量的并发请求。
阻塞代码实例
创建一个文件 input.txt ,内容如下:
菜鸟教程官网地址:www.runoob.com
创建 main.js 文件, 代码如下:
var fs = require("fs");
var data = fs.readFileSync('input.txt');
console.log(data.toString());
console.log("程序执行结束!");
以上代码执行结果如下:
$ node main.js
菜鸟教程官网地址:www.runoob.com
程序执行结束!
非阻塞代码实例
创建一个文件 input.txt ,内容如下:
菜鸟教程官网地址:www.runoob.com
创建 main.js 文件, 代码如下:
var fs = require("fs");
fs.readFile('input.txt', function (err, data) {
if (err) return console.error(err);
console.log(data.toString());
});
console.log("程序执行结束!");
以上代码执行结果如下:
$ node main.js
程序执行结束!
菜鸟教程官网地址:www.runoob.com
以上两个实例我们了解了阻塞与非阻塞调用的不同。第一个实例在文件读取完后才执行完程序。 第二个实例我们不需要等待文件读取完,这样就可以在读取文件时同时执行接下来的代码,大大提高了程序的性能。
因此,阻塞是按顺序执行的,而非阻塞是不需要按顺序的,所以如果需要处理回调函数的参数,我们就需要写在回调函数内。
7)
Node.js 事件循环
Node.js 是单进程单线程应用程序,但是通过事件和回调支持并发,所以性能非常高。
Node.js 的每一个 API 都是异步的,并作为一个独立线程运行,使用异步函数调用,并处理并发。
Node.js 基本上所有的事件机制都是用设计模式中观察者模式实现。
Node.js 单线程类似进入一个while(true)的事件循环,直到没有事件观察者退出,每个异步事件都生成一个事件观察者,如果有事件发生就调用该回调函数.
事件驱动程序
Node.js 使用事件驱动模型,当web server接收到请求,就把它关闭然后进行处理,然后去服务下一个web请求。
当这个请求完成,它被放回处理队列,当到达队列开头,这个结果被返回给用户。
这个模型非常高效可扩展性非常强,因为webserver一直接受请求而不等待任何读写操作。(这也被称之为非阻塞式IO或者事件驱动IO)
在事件驱动模型中,会生成一个主循环来监听事件,当检测到事件时触发回调函数。
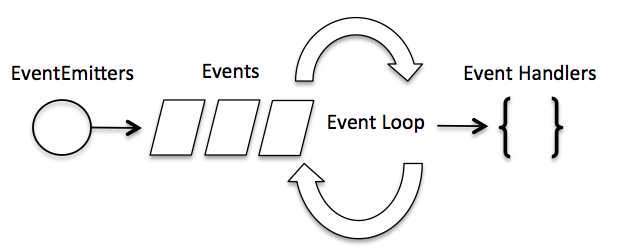
整个事件驱动的流程就是这么实现的,非常简洁。有点类似于观察者模式,事件相当于一个主题(Subject),而所有注册到这个事件上的处理函数相当于观察者(Observer)。
Node.js 有多个内置的事件,我们可以通过引入 events 模块,并通过实例化 EventEmitter 类来绑定和监听事件,如下实例:
// 引入 events 模块
var events = require('events');
// 创建 eventEmitter 对象
var eventEmitter = new events.EventEmitter();
以下程序绑定事件处理程序:
// 绑定事件及事件的处理程序
eventEmitter.on('eventName', eventHandler);
我们可以通过程序触发事件:
// 触发事件
eventEmitter.emit('eventName');
实例
创建 main.js 文件,代码如下所示:
// 引入 events 模块
var events = require('events');
// 创建 eventEmitter 对象
var eventEmitter = new events.EventEmitter();
// 创建事件处理程序
var connectHandler = function connected() {
console.log('连接成功。');
// 触发 data_received 事件
eventEmitter.emit('data_received');
}
// 绑定 connection 事件处理程序
eventEmitter.on('connection', connectHandler);
// 使用匿名函数绑定 data_received 事件
eventEmitter.on('data_received', function(){
console.log('数据接收成功。');
});
// 触发 connection 事件
eventEmitter.emit('connection');
console.log("程序执行完毕。");
接下来让我们执行以上代码:
$ node main.js
连接成功。
数据接收成功。
程序执行完毕。
Node 应用程序是如何工作的?
在 Node 应用程序中,执行异步操作的函数将回调函数作为最后一个参数, 回调函数接收错误对象作为第一个参数。
接下来让我们来重新看下前面的实例,创建一个 input.txt ,文件内容如下:
菜鸟教程官网地址:www.runoob.com
创建 main.js 文件,代码如下:
var fs = require("fs");
fs.readFile('input.txt', function (err, data) {
if (err){
console.log(err.stack);
return;
}
console.log(data.toString());
});
console.log("程序执行完毕");
以上程序中 fs.readFile() 是异步函数用于读取文件。 如果在读取文件过程中发生错误,错误 err 对象就会输出错误信息。
如果没发生错误,readFile 跳过 err 对象的输出,文件内容就通过回调函数输出。
执行以上代码,执行结果如下:
程序执行完毕
菜鸟教程官网地址:www.runoob.com
接下来我们删除 input.txt 文件,执行结果如下所示:
程序执行完毕
Error: ENOENT, open 'input.txt'
因为文件 input.txt 不存在,所以输出了错误信息。
8)
Node.js EventEmitter
Node.js 所有的异步 I/O 操作在完成时都会发送一个事件到事件队列。
Node.js里面的许多对象都会分发事件:一个net.Server对象会在每次有新连接时分发一个事件, 一个fs.readStream对象会在文件被打开的时候发出一个事件。 所有这些产生事件的对象都是 events.EventEmitter 的实例。
EventEmitter 类
events 模块只提供了一个对象: events.EventEmitter。EventEmitter 的核心就是事件触发与事件监听器功能的封装。
你可以通过require("events");来访问该模块。
// 引入 events 模块
var events = require('events');
// 创建 eventEmitter 对象
var eventEmitter = new events.EventEmitter();
EventEmitter 对象如果在实例化时发生错误,会触发 error 事件。当添加新的监听器时,newListener 事件会触发,当监听器被移除时,removeListener 事件被触发。
下面我们用一个简单的例子说明 EventEmitter 的用法:
//event.js 文件
var EventEmitter = require('events').EventEmitter;
var event = new EventEmitter();
event.on('some_event', function() {
console.log('some_event 事件触发');
});
setTimeout(function() {
event.emit('some_event');
}, 1000);
执行结果如下:
运行这段代码,1 秒后控制台输出了 'some_event 事件触发'。其原理是 event 对象注册了事件 some_event 的一个监听器,然后我们通过 setTimeout 在 1000 毫秒以后向 event 对象发送事件 some_event,此时会调用some_event 的监听器。
$ node event.js
some_event 事件触发
EventEmitter 的每个事件由一个事件名和若干个参数组成,事件名是一个字符串,通常表达一定的语义。对于每个事件,EventEmitter 支持 若干个事件监听器。
当事件触发时,注册到这个事件的事件监听器被依次调用,事件参数作为回调函数参数传递。
让我们以下面的例子解释这个过程:
//event.js 文件
var events = require('events');
var emitter = new events.EventEmitter();
emitter.on('someEvent', function(arg1, arg2) {
console.log('listener1', arg1, arg2);
});
emitter.on('someEvent', function(arg1, arg2) {
console.log('listener2', arg1, arg2);
});
emitter.emit('someEvent', 'arg1 参数', 'arg2 参数');
执行以上代码,运行的结果如下:
$ node event.js
listener1 arg1 参数 arg2 参数
listener2 arg1 参数 arg2 参数
以上例子中,emitter 为事件 someEvent 注册了两个事件监听器,然后触发了 someEvent 事件。
运行结果中可以看到两个事件监听器回调函数被先后调用。 这就是EventEmitter最简单的用法。
EventEmitter 提供了多个属性,如 on 和 emit。on 函数用于绑定事件函数,emit 属性用于触发一个事件。接下来我们来具体看下 EventEmitter 的属性介绍。
方法
| 序号 | 方法 & 描述 |
|---|
| 1 | addListener(event, listener)
为指定事件添加一个监听器到监听器数组的尾部。 |
| 2 | on(event, listener)
为指定事件注册一个监听器,接受一个字符串 event 和一个回调函数。
server.on('connection', function (stream) {
console.log('someone connected!');
});
|
| 3 | once(event, listener)
为指定事件注册一个单次监听器,即 监听器最多只会触发一次,触发后立刻解除该监听器。
server.once('connection', function (stream) {
console.log('Ah, we have our first user!');
});
|
| 4 | removeListener(event, listener)
移除指定事件的某个监听器,监听器必须是该事件已经注册过的监听器。 它接受两个参数,第一个是事件名称,第二个是回调函数名称。 var callback = function(stream) {
console.log('someone connected!');
};
server.on('connection', callback);
// ...
server.removeListener('connection', callback);
|
| 5 | removeAllListeners([event])
移除所有事件的所有监听器, 如果指定事件,则移除指定事件的所有监听器。 |
| 6 | setMaxListeners(n)
默认情况下, EventEmitters 如果你添加的监听器超过 10 个就会输出警告信息。 setMaxListeners 函数用于提高监听器的默认限制的数量。 |
| 7 | listeners(event)
返回指定事件的监听器数组。 |
| 8 | emit(event, [arg1], [arg2], [...])
按参数的顺序执行每个监听器,如果事件有注册监听返回 true,否则返回 false。 |
类方法
| 序号 | 方法 & 描述 |
|---|
| 1 | listenerCount(emitter, event)
返回指定事件的监听器数量。 |
事件
| 序号 | 事件 & 描述 |
|---|
| 1 | newListener
event - 字符串,事件名称 listener - 处理事件函数
该事件在添加新监听器时被触发。 |
| 2 | removeListener
event - 字符串,事件名称 listener - 处理事件函数
从指定监听器数组中删除一个监听器。需要注意的是,此操作将会改变处于被删监听器之后的那些监听器的索引。 |
实例
以下实例通过 connection(连接)事件演示了 EventEmitter 类的应用。
创建 main.js 文件,代码如下:
var events = require('events');
var eventEmitter = new events.EventEmitter();
// 监听器 #1
var listener1 = function listener1() {
console.log('监听器 listener1 执行。');
}
// 监听器 #2
var listener2 = function listener2() {
console.log('监听器 listener2 执行。');
}
// 绑定 connection 事件,处理函数为 listener1
eventEmitter.addListener('connection', listener1);
// 绑定 connection 事件,处理函数为 listener2
eventEmitter.on('connection', listener2);
var eventListeners = require('events').EventEmitter.listenerCount(eventEmitter,'connection');
console.log(eventListeners + " 个监听器监听连接事件。");
// 处理 connection 事件
eventEmitter.emit('connection');
// 移除监绑定的 listener1 函数
eventEmitter.removeListener('connection', listener1);
console.log("listener1 不再受监听。");
// 触发连接事件
eventEmitter.emit('connection');
eventListeners = require('events').EventEmitter.listenerCount(eventEmitter,'connection');
console.log(eventListeners + " 个监听器监听连接事件。");
console.log("程序执行完毕。");
以上代码,执行结果如下所示:
$ node main.js
2 个监听器监听连接事件。
监听器 listener1 执行。
监听器 listener2 执行。
listener1 不再受监听。
监听器 listener2 执行。
1 个监听器监听连接事件。
程序执行完毕。
error 事件
EventEmitter 定义了一个特殊的事件 error,它包含了错误的语义,我们在遇到 异常的时候通常会触发 error 事件。
当 error 被触发时,EventEmitter 规定如果没有响 应的监听器,Node.js 会把它当作异常,退出程序并输出错误信息。
我们一般要为会触发 error 事件的对象设置监听器,避免遇到错误后整个程序崩溃。例如:
var events = require('events');
var emitter = new events.EventEmitter();
emitter.emit('error');
运行时会显示以下错误:
node.js:201
throw e; // process.nextTick error, or 'error' event on first tick
^
Error: Uncaught, unspecified 'error' event.
at EventEmitter.emit (events.js:50:15)
at Object.<anonymous> (/home/byvoid/error.js:5:9)
at Module._compile (module.js:441:26)
at Object..js (module.js:459:10)
at Module.load (module.js:348:31)
at Function._load (module.js:308:12)
at Array.0 (module.js:479:10)
at EventEmitter._tickCallback (node.js:192:40)
继承 EventEmitter
大多数时候我们不会直接使用 EventEmitter,而是在对象中继承它。包括 fs、net、 http 在内的,只要是支持事件响应的核心模块都是 EventEmitter 的子类。
为什么要这样做呢?原因有两点:
首先,具有某个实体功能的对象实现事件符合语义, 事件的监听和发射应该是一个对象的方法。
其次 JavaScript 的对象机制是基于原型的,支持 部分多重继承,继承 EventEmitter 不会打乱对象原有的继承关系。
9)
Node.js Buffer(缓冲区)
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。
但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
创建 Buffer 类
Node Buffer 类可以通过多种方式来创建。
方法 1
创建长度为 10 字节的 Buffer 实例:
var buf = new Buffer(10);
方法 2
通过给定的数组创建 Buffer 实例:
var buf = new Buffer([10, 20, 30, 40, 50]);
方法 3
通过一个字符串来创建 Buffer 实例:
var buf = new Buffer("www.runoob.com", "utf-8");
utf-8 是默认的编码方式,此外它同样支持以下编码:"ascii", "utf8", "utf16le", "ucs2", "base64" 和 "hex"。
写入缓冲区
语法
写入 Node 缓冲区的语法如下所示:
buf.write(string[, offset[, length]][, encoding])
参数
参数描述如下:
string - 写入缓冲区的字符串。
offset - 缓冲区开始写入的索引值,默认为 0 。
length - 写入的字节数,默认为 buffer.length
encoding - 使用的编码。默认为 'utf8' 。
返回值
返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
实例
buf = new Buffer(256);
len = buf.write("www.runoob.com");
console.log("写入字节数 : "+ len);
执行以上代码,输出结果为:
$node main.js
写入字节数 : 14
从缓冲区读取数据
语法
读取 Node 缓冲区数据的语法如下所示:
buf.toString([encoding[, start[, end]]])
参数
参数描述如下:
返回值
解码缓冲区数据并使用指定的编码返回字符串。
实例
buf = new Buffer(26);
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97;
}
console.log( buf.toString('ascii')); // 输出: abcdefghijklmnopqrstuvwxyz
console.log( buf.toString('ascii',0,5)); // 输出: abcde
console.log( buf.toString('utf8',0,5)); // 输出: abcde
console.log( buf.toString(undefined,0,5)); // 使用 'utf8' 编码, 并输出: abcde
执行以上代码,输出结果为:
$ node main.js
abcdefghijklmnopqrstuvwxyz
abcde
abcde
abcde
将 Buffer 转换为 JSON 对象
语法
将 Node Buffer 转换为 JSON 对象的函数语法格式如下:
buf.toJSON()
返回值
返回 JSON 对象。
实例
var buf = new Buffer('www.runoob.com');
var json = buf.toJSON(buf);
console.log(json);
执行以上代码,输出结果为:
[ 119, 119, 119, 46, 114, 117, 110, 111, 111, 98, 46, 99, 111, 109 ]
缓冲区合并
语法
Node 缓冲区合并的语法如下所示:
Buffer.concat(list[, totalLength])
参数
参数描述如下:
返回值
返回一个多个成员合并的新 Buffer 对象。
实例
var buffer1 = new Buffer('菜鸟教程 ');
var buffer2 = new Buffer('www.runoob.com');
var buffer3 = Buffer.concat([buffer1,buffer2]);
console.log("buffer3 内容: " + buffer3.toString());
执行以上代码,输出结果为:
buffer3 内容: 菜鸟教程 www.runoob.com
缓冲区比较
语法
Node Buffer 比较的函数语法如下所示, 该方法在 Node.js v0.12.2 版本引入:
buf.compare(otherBuffer);
参数
参数描述如下:
返回值
返回一个数字,表示 buf 在 otherBuffer 之前,之后或相同。
实例
var buffer1 = new Buffer('ABC');
var buffer2 = new Buffer('ABCD');
var result = buffer1.compare(buffer2);
if(result < 0) {
console.log(buffer1 + " 在 " + buffer2 + "之前");
}else if(result == 0){
console.log(buffer1 + " 与 " + buffer2 + "相同");
}else {
console.log(buffer1 + " 在 " + buffer2 + "之后");
}
执行以上代码,输出结果为:
ABC在ABCD之前
拷贝缓冲区
语法
Node 缓冲区拷贝语法如下所示:
buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
参数
参数描述如下:
targetBuffer - 要拷贝的 Buffer 对象。
targetStart - 数字, 可选, 默认: 0
sourceStart - 数字, 可选, 默认: 0
sourceEnd - 数字, 可选, 默认: buffer.length
返回值
没有返回值。
实例
var buffer1 = new Buffer('ABC');
// 拷贝一个缓冲区
var buffer2 = new Buffer(3);
buffer1.copy(buffer2);
console.log("buffer2 content: " + buffer2.toString());
执行以上代码,输出结果为:
buffer2 content: ABC
缓冲区裁剪
Node 缓冲区裁剪语法如下所示:
buf.slice([start[, end]])
参数
参数描述如下:
返回值
返回一个新的缓冲区,它和旧缓冲区指向同一块内存,但是从索引 start 到 end 的位置剪切。
实例
var buffer1 = new Buffer('runoob');
// 剪切缓冲区
var buffer2 = buffer1.slice(0,2);
console.log("buffer2 content: " + buffer2.toString());
执行以上代码,输出结果为:
buffer2 content: ru
缓冲区长度
语法
Node 缓冲区长度计算语法如下所示:
buf.length;
返回值
返回 Buffer 对象所占据的内存长度。
实例
var buffer = new Buffer('www.runoob.com');
// 缓冲区长度
console.log("buffer length: " + buffer.length);
执行以上代码,输出结果为:
buffer length: 14
方法参考手册
以下列出了 Node.js Buffer 模块常用的方法(注意有些方法在旧版本是没有的):
| 序号 | 方法 & 描述 |
|---|
| 1 | new Buffer(size)
分配一个新的 size 大小单位为8位字节的 buffer。 注意, size 必须小于 kMaxLength,否则,将会抛出异常 RangeError。 |
| 2 | new Buffer(buffer)
拷贝参数 buffer 的数据到 Buffer 实例。 |
| 3 | new Buffer(str[, encoding])
分配一个新的 buffer ,其中包含着传入的 str 字符串。 encoding 编码方式默认为 'utf8'。 |
| 4 | buf.length
返回这个 buffer 的 bytes 数。注意这未必是 buffer 里面内容的大小。length 是 buffer 对象所分配的内存数,它不会随着这个 buffer 对象内容的改变而改变。 |
| 5 | buf.write(string[, offset[, length]][, encoding])
根据参数 offset 偏移量和指定的 encoding 编码方式,将参数 string 数据写入buffer。 offset 偏移量默认值是 0, encoding 编码方式默认是 utf8。 length 长度是将要写入的字符串的 bytes 大小。 返回 number 类型,表示写入了多少 8 位字节流。如果 buffer 没有足够的空间来放整个 string,它将只会只写入部分字符串。 length 默认是 buffer.length - offset。 这个方法不会出现写入部分字符。 |
| 6 | buf.writeUIntLE(value, offset, byteLength[, noAssert])
将value 写入到 buffer 里, 它由offset 和 byteLength 决定,支持 48 位计算,例如:
var b = new Buffer(6);
b.writeUIntBE(0x1234567890ab, 0, 6);
// <Buffer 12 34 56 78 90 ab>
noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| 7 | buf.writeUIntBE(value, offset, byteLength[, noAssert])
将value 写入到 buffer 里, 它由offset 和 byteLength 决定,支持 48 位计算。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| 8 | buf.writeIntLE(value, offset, byteLength[, noAssert])
将value 写入到 buffer 里, 它由offset 和 byteLength 决定,支持 48 位计算。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| 9 | buf.writeIntBE(value, offset, byteLength[, noAssert])
将value 写入到 buffer 里, 它由offset 和 byteLength 决定,支持 48 位计算。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| 10 | buf.readUIntLE(offset, byteLength[, noAssert])
支持读取 48 位以下的数字。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 11 | buf.readUIntBE(offset, byteLength[, noAssert])
支持读取 48 位以下的数字。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 12 | buf.readIntLE(offset, byteLength[, noAssert])
支持读取 48 位以下的数字。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 13 | buf.readIntBE(offset, byteLength[, noAssert])
支持读取 48 位以下的数字。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 14 | buf.toString([encoding[, start[, end]]])
根据 encoding 参数(默认是 'utf8')返回一个解码过的 string 类型。还会根据传入的参数 start (默认是 0) 和 end (默认是 buffer.length)作为取值范围。 |
| 15 | buf.toJSON()
将 Buffer 实例转换为 JSON 对象。 |
| 16 | buf[index]
获取或设置指定的字节。返回值代表一个字节,所以返回值的合法范围是十六进制0x00到0xFF 或者十进制0至 255。 |
| 17 | buf.equals(otherBuffer)
比较两个缓冲区是否相等,如果是返回 true,否则返回 false。 |
| 18 | buf.compare(otherBuffer)
比较两个 Buffer 对象,返回一个数字,表示 buf 在 otherBuffer 之前,之后或相同。 |
| 19 | buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
buffer 拷贝,源和目标可以相同。 targetStart 目标开始偏移和 sourceStart 源开始偏移默认都是 0。 sourceEnd 源结束位置偏移默认是源的长度 buffer.length 。 |
| 20 | buf.slice([start[, end]])
剪切 Buffer 对象,根据 start(默认是 0 ) 和 end (默认是 buffer.length ) 偏移和裁剪了索引。 负的索引是从 buffer 尾部开始计算的。 |
| 21 | buf.readUInt8(offset[, noAssert])
根据指定的偏移量,读取一个有符号 8 位整数。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 如果这样 offset 可能会超出buffer 的末尾。默认是 false。 |
| 22 | buf.readUInt16LE(offset[, noAssert])
根据指定的偏移量,使用特殊的 endian 字节序格式读取一个有符号 16 位整数。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 23 | buf.readUInt16BE(offset[, noAssert])
根据指定的偏移量,使用特殊的 endian 字节序格式读取一个有符号 16 位整数。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 24 | buf.readUInt32LE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian 字节序格式读取一个有符号 32 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 25 | buf.readUInt32BE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian 字节序格式读取一个有符号 32 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 26 | buf.readInt8(offset[, noAssert])
根据指定的偏移量,读取一个 signed 8 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 27 | buf.readInt16LE(offset[, noAssert])
根据指定的偏移量,使用特殊的 endian 格式读取一个 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 28 | buf.readInt16BE(offset[, noAssert])
根据指定的偏移量,使用特殊的 endian 格式读取一个 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 29 | buf.readInt32LE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian 字节序格式读取一个 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 30 | buf.readInt32BE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian 字节序格式读取一个 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 31 | buf.readFloatLE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian 字节序格式读取一个 32 位浮点数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer的末尾。默认是 false。 |
| 32 | buf.readFloatBE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian 字节序格式读取一个 32 位浮点数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer的末尾。默认是 false。 |
| 33 | buf.readDoubleLE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian字节序格式读取一个 64 位double。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 34 | buf.readDoubleBE(offset[, noAssert])
根据指定的偏移量,使用指定的 endian字节序格式读取一个 64 位double。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 35 | buf.writeUInt8(value, offset[, noAssert])
根据传入的 offset 偏移量将 value 写入 buffer。注意:value 必须是一个合法的有符号 8 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则不要使用。默认是 false。 |
| 36 | buf.writeUInt16LE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的有符号 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 37 | buf.writeUInt16BE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的有符号 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 38 | buf.writeUInt32LE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式(LITTLE-ENDIAN:小字节序)将 value 写入buffer。注意:value 必须是一个合法的有符号 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着value 可能过大,或者offset可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 39 | buf.writeUInt32BE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式(Big-Endian:大字节序)将 value 写入buffer。注意:value 必须是一个合法的有符号 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者offset可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 40 | buf.writeInt8(value, offset[, noAssert])
根据传入的> |
| 41 | buf.writeInt16LE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false 。 |
| 42 | buf.writeInt16BE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false 。 |
| 43 | buf.writeInt32LE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 44 | buf.writeInt32BE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 45 | buf.writeFloatLE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer 。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 46 | buf.writeFloatBE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer 。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 47 | buf.writeDoubleLE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个有效的 64 位double 类型的值。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成value被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 48 | buf.writeDoubleBE(value, offset[, noAssert])
根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个有效的 64 位double 类型的值。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成value被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 49 | buf.fill(value[, offset][, end])
使用指定的 value 来填充这个 buffer。如果没有指定 offset (默认是 0) 并且 end (默认是 buffer.length) ,将会填充整个buffer。 |
10)
Node.js Stream(流)
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。
Node.js,Stream 有四种流类型:
所有的 Stream 对象都是 EventEmitter 的实例。常用的事件有:
本教程会为大家介绍常用的流操作。
从流中读取数据
创建 input.txt 文件,内容如下:
菜鸟教程官网地址:www.runoob.com
创建 main.js 文件, 代码如下:
var fs = require("fs");
var data = '';
// 创建可读流
var readerStream = fs.createReadStream('input.txt');
// 设置编码为 utf8。
readerStream.setEncoding('UTF8');
// 处理流事件 --> data, end, and error
readerStream.on('data', function(chunk) {
data += chunk;
});
readerStream.on('end',function(){
console.log(data);
});
readerStream.on('error', function(err){
console.log(err.stack);
});
console.log("程序执行完毕");
以上代码执行结果如下:
程序执行完毕
菜鸟教程官网地址:www.runoob.com
写入流
创建 main.js 文件, 代码如下:
var fs = require("fs");
var data = '菜鸟教程官网地址:www.runoob.com';
// 创建一个可以写入的流,写入到文件 output.txt 中
var writerStream = fs.createWriteStream('output.txt');
// 使用 utf8 编码写入数据
writerStream.write(data,'UTF8');
// 标记文件末尾
writerStream.end();
// 处理流事件 --> data, end, and error
writerStream.on('finish', function() {
console.log("写入完成。");
});
writerStream.on('error', function(err){
console.log(err.stack);
});
console.log("程序执行完毕");
以上程序会将 data 变量的数据写入到 output.txt 文件中。代码执行结果如下:
$ node main.js
程序执行完毕
写入完成。
查看 output.txt 文件的内容:
$ cat output.txt
菜鸟教程官网地址:www.runoob.com
管道流
管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。

如上面的图片所示,我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程。
以下实例我们通过读取一个文件内容并将内容写入到另外一个文件中。
设置 input.txt 文件内容如下:
菜鸟教程官网地址:www.runoob.com
管道流操作实例
创建 main.js 文件, 代码如下:
var fs = require("fs");
// 创建一个可读流
var readerStream = fs.createReadStream('input.txt');
// 创建一个可写流
var writerStream = fs.createWriteStream('output.txt');
// 管道读写操作
// 读取 input.txt 文件内容,并将内容写入到 output.txt 文件中
readerStream.pipe(writerStream);
console.log("程序执行完毕");
代码执行结果如下:
$ node main.js
程序执行完毕
查看 output.txt 文件的内容:
$ cat output.txt
菜鸟教程官网地址:www.runoob.com
管道流操作实例
链式流
链式是通过连接输出流到另外一个流并创建多个对个流操作链的机制。链式流一般用于管道操作。
接下来我们就是用管道和链式来压缩和解压文件。
创建 compress.js 文件, 代码如下:
var fs = require("fs");
var zlib = require('zlib');
// 压缩 input.txt 文件为 input.txt.gz
fs.createReadStream('input.txt')
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream('input.txt.gz'));
console.log("文件压缩完成。");
代码执行结果如下:
$ node compress.js
文件压缩完成。
执行完以上操作后,我们可以看到当前目录下生成了 input.txt 的压缩文件 input.txt.gz。
接下来,让我们来解压该文件,创建 decompress.js 文件,代码如下:
var fs = require("fs");
var zlib = require('zlib');
// 解压 input.txt.gz 文件为 input.txt
fs.createReadStream('input.txt.gz')
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream('input.txt'));
console.log("文件解压完成。");
代码执行结果如下:
$ node decompress.js
文件解压完成。
11)
Node.js模块系统
为了让Node.js的文件可以相互调用,Node.js提供了一个简单的模块系统。
模块是Node.js 应用程序的基本组成部分,文件和模块是一一对应的。换言之,一个 Node.js 文件就是一个模块,这个文件可能是JavaScript 代码、JSON 或者编译过的C/C++ 扩展。
创建模块
在 Node.js 中,创建一个模块非常简单,如下我们创建一个 'main.js' 文件,代码如下:
var hello = require('./hello');
hello.world();
以上实例中,代码 require('./hello') 引入了当前目录下的hello.js文件(./ 为当前目录,node.js默认后缀为js)。
Node.js 提供了exports 和 require 两个对象,其中 exports 是模块公开的接口,require 用于从外部获取一个模块的接口,即所获取模块的 exports 对象。
接下来我们就来创建hello.js文件,代码如下:
exports.world = function() {
console.log('Hello World');
}
在以上示例中,hello.js 通过 exports 对象把 world 作为模块的访问接口,在 main.js 中通过 require('./hello') 加载这个模块,然后就可以直接访 问 hello.js 中 exports 对象的成员函数了。
有时候我们只是想把一个对象封装到模块中,格式如下:
module.exports = function() {
// ...
}
例如:
//hello.js
function Hello() {
var name;
this.setName = function(thyName) {
name = thyName;
};
this.sayHello = function() {
console.log('Hello ' + name);
};
};
module.exports = Hello;
这样就可以直接获得这个对象了:
//main.js
var Hello = require('./hello');
hello = new Hello();
hello.setName('BYVoid');
hello.sayHello();
模块接口的唯一变化是使用 module.exports = Hello 代替了exports.world = function(){}。 在外部引用该模块时,其接口对象就是要输出的 Hello 对象本身,而不是原先的 exports。
服务端的模块放在哪里
也许你已经注意到,我们已经在代码中使用了模块了。像这样:
var http = require("http");
...
http.createServer(...);
Node.js中自带了一个叫做"http"的模块,我们在我们的代码中请求它并把返回值赋给一个本地变量。
这把我们的本地变量变成了一个拥有所有 http 模块所提供的公共方法的对象。
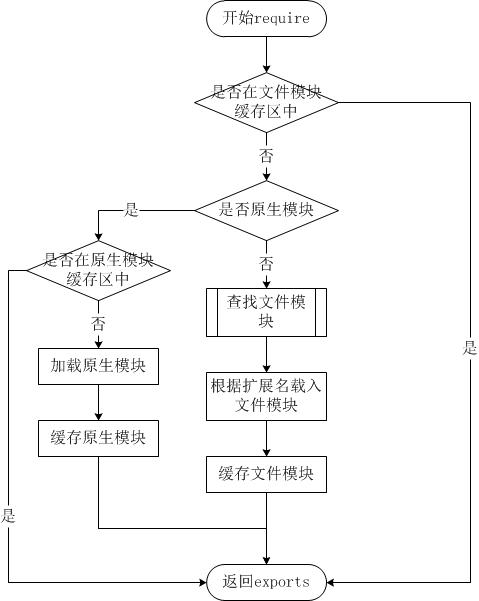
Node.js 的 require方法中的文件查找策略如下:
由于Node.js中存在4类模块(原生模块和3种文件模块),尽管require方法极其简单,但是内部的加载却是十分复杂的,其加载优先级也各自不同。如下图所示:
从文件模块缓存中加载
尽管原生模块与文件模块的优先级不同,但是都不会优先于从文件模块的缓存中加载已经存在的模块。
从原生模块加载
原生模块的优先级仅次于文件模块缓存的优先级。require方法在解析文件名之后,优先检查模块是否在原生模块列表中。以http模块为例,尽管在目录下存在一个http/http.js/http.node/http.json文件,require("http")都不会从这些文件中加载,而是从原生模块中加载。
原生模块也有一个缓存区,同样也是优先从缓存区加载。如果缓存区没有被加载过,则调用原生模块的加载方式进行加载和执行。
从文件加载
当文件模块缓存中不存在,而且不是原生模块的时候,Node.js会解析require方法传入的参数,并从文件系统中加载实际的文件,加载过程中的包装和编译细节在前一节中已经介绍过,这里我们将详细描述查找文件模块的过程,其中,也有一些细节值得知晓。
require方法接受以下几种参数的传递:
12)
Node.js 函数
在JavaScript中,一个函数可以作为另一个函数的参数。我们可以先定义一个函数,然后传递,也可以在传递参数的地方直接定义函数。
Node.js中函数的使用与Javascript类似,举例来说,你可以这样做:
function say(word) {
console.log(word);
}
function execute(someFunction, value) {
someFunction(value);
}
execute(say, "Hello");
以上代码中,我们把 say 函数作为execute函数的第一个变量进行了传递。这里返回的不是 say 的返回值,而是 say 本身!
这样一来, say 就变成了execute 中的本地变量 someFunction ,execute可以通过调用 someFunction() (带括号的形式)来使用 say 函数。
当然,因为 say 有一个变量, execute 在调用 someFunction 时可以传递这样一个变量。
匿名函数
我们可以把一个函数作为变量传递。但是我们不一定要绕这个"先定义,再传递"的圈子,我们可以直接在另一个函数的括号中定义和传递这个函数:
function execute(someFunction, value) {
someFunction(value);
}
execute(function(word){ console.log(word) }, "Hello");
我们在 execute 接受第一个参数的地方直接定义了我们准备传递给 execute 的函数。
用这种方式,我们甚至不用给这个函数起名字,这也是为什么它被叫做匿名函数 。
函数传递是如何让HTTP服务器工作的
带着这些知识,我们再来看看我们简约而不简单的HTTP服务器:
var http = require("http");
http.createServer(function(request, response) {
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}).listen(8888);
现在它看上去应该清晰了很多:我们向 createServer 函数传递了一个匿名函数。
用这样的代码也可以达到同样的目的:
var http = require("http");
function onRequest(request, response) {
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);13)
Node.js 路由
我们要为路由提供请求的URL和其他需要的GET及POST参数,随后路由需要根据这些数据来执行相应的代码。
因此,我们需要查看HTTP请求,从中提取出请求的URL以及GET/POST参数。这一功能应当属于路由还是服务器(甚至作为一个模块自身的功能)确实值得探讨,但这里暂定其为我们的HTTP服务器的功能。
我们需要的所有数据都会包含在request对象中,该对象作为onRequest()回调函数的第一个参数传递。但是为了解析这些数据,我们需要额外的Node.JS模块,它们分别是url和querystring模块。
url.parse(string).query
|
url.parse(string).pathname |
| |
| |
------ -------------------
http://localhost:8888/start?foo=bar&hello=world
--- -----
| |
| |
querystring(string)["foo"] |
|
querystring(string)["hello"]
当然我们也可以用querystring模块来解析POST请求体中的参数,稍后会有演示。
现在我们来给onRequest()函数加上一些逻辑,用来找出浏览器请求的URL路径:
var http = require("http");
var url = require("url");
function start() {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
好了,我们的应用现在可以通过请求的URL路径来区别不同请求了--这使我们得以使用路由(还未完成)来将请求以URL路径为基准映射到处理程序上。
在我们所要构建的应用中,这意味着来自/start和/upload的请求可以使用不同的代码来处理。稍后我们将看到这些内容是如何整合到一起的。
现在我们可以来编写路由了,建立一个名为 router.js 的文件,添加以下内容:
function route(pathname) {
console.log("About to route a request for " + pathname);
}
exports.route = route;
如你所见,这段代码什么也没干,不过对于现在来说这是应该的。在添加更多的逻辑以前,我们先来看看如何把路由和服务器整合起来。
我们的服务器应当知道路由的存在并加以有效利用。我们当然可以通过硬编码的方式将这一依赖项绑定到服务器上,但是其它语言的编程经验告诉我们这会是一件非常痛苦的事,因此我们将使用依赖注入的方式较松散地添加路由模块。
首先,我们来扩展一下服务器的start()函数,以便将路由函数作为参数传递过去,server.js 文件代码如下
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
route(pathname);
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
同时,我们会相应扩展index.js,使得路由函数可以被注入到服务器中:
var server = require("./server");
var router = require("./router");
server.start(router.route);
在这里,我们传递的函数依旧什么也没做。
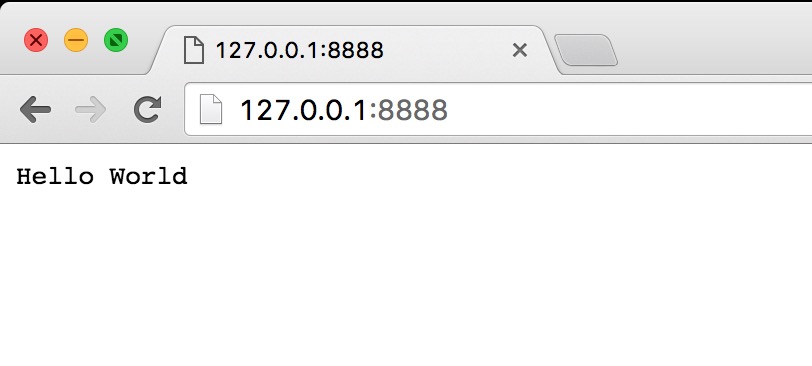
如果现在启动应用(node index.js,始终记得这个命令行),随后请求一个URL,你将会看到应用输出相应的信息,这表明我们的HTTP服务器已经在使用路由模块了,并会将请求的路径传递给路由:
$ node index.js
Server has started.
以上输出已经去掉了比较烦人的/favicon.ico请求相关的部分。
浏览器访问 http://127.0.0.1:8888/,输出结果如下:
14)
Node.js 全局对象
JavaScript 中有一个特殊的对象,称为全局对象(Global Object),它及其所有属性都可以在程序的任何地方访问,即全局变量。
在浏览器 JavaScript 中,通常 window 是全局对象, 而 Node.js 中的全局对象是 global,所有全局变量(除了 global 本身以外)都是 global 对象的属性。
在 Node.js 我们可以直接访问到 global 的属性,而不需要在应用中包含它。
全局对象与全局变量
global 最根本的作用是作为全局变量的宿主。按照 ECMAScript 的定义,满足以下条 件的变量是全局变量:
在最外层定义的变量;
全局对象的属性;
隐式定义的变量(未定义直接赋值的变量)。
当你定义一个全局变量时,这个变量同时也会成为全局对象的属性,反之亦然。需要注 意的是,在 Node.js 中你不可能在最外层定义变量,因为所有用户代码都是属于当前模块的, 而模块本身不是最外层上下文。
注意: 永远使用 var 定义变量以避免引入全局变量,因为全局变量会污染 命名空间,提高代码的耦合风险。
__filename
__filename 表示当前正在执行的脚本的文件名。它将输出文件所在位置的绝对路径,且和命令行参数所指定的文件名不一定相同。 如果在模块中,返回的值是模块文件的路径。
实例
创建文件 main.js ,代码如下所示:
// 输出全局变量 __filename 的值
console.log( __filename );
执行 main.js 文件,代码如下所示:
$ node main.js
/web/com/runoob/nodejs/main.js
__dirname
__dirname 表示当前执行脚本所在的目录。
实例
创建文件 main.js ,代码如下所示:
// 输出全局变量 __dirname 的值
console.log( __dirname );
执行 main.js 文件,代码如下所示:
$ node main.js
/web/com/runoob/nodejs
setTimeout(cb, ms)
setTimeout(cb, ms) 全局函数在指定的毫秒(ms)数后执行指定函数(cb)。:setTimeout() 只执行一次指定函数。
返回一个代表定时器的句柄值。
实例
创建文件 main.js ,代码如下所示:
function printHello(){
console.log( "Hello, World!");
}
// 两秒后执行以上函数
setTimeout(printHello, 2000);
执行 main.js 文件,代码如下所示:
$ node main.js
Hello, World!
clearTimeout(t)
clearTimeout( t ) 全局函数用于停止一个之前通过 setTimeout() 创建的定时器。 参数 t 是通过 setTimeout() 函数创建的定时器。
实例
创建文件 main.js ,代码如下所示:
function printHello(){
console.log( "Hello, World!");
}
// 两秒后执行以上函数
var t = setTimeout(printHello, 2000);
// 清除定时器
clearTimeout(t);
执行 main.js 文件,代码如下所示:
$ node main.js
setInterval(cb, ms)
setInterval(cb, ms) 全局函数在指定的毫秒(ms)数后执行指定函数(cb)。
返回一个代表定时器的句柄值。可以使用 clearInterval(t) 函数来清除定时器。
setInterval() 方法会不停地调用函数,直到 clearInterval() 被调用或窗口被关闭。
实例
创建文件 main.js ,代码如下所示:
function printHello(){
console.log( "Hello, World!");
}
// 两秒后执行以上函数
setInterval(printHello, 2000);
执行 main.js 文件,代码如下所示:
$ node main.js
Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! ……
以上程序每隔两秒就会输出一次"Hello, World!",且会永久执行下去,直到你按下 ctrl + c 按钮。
console
console 用于提供控制台标准输出,它是由 Internet Explorer 的 JScript 引擎提供的调试工具,后来逐渐成为浏览器的事实标准。
Node.js 沿用了这个标准,提供与习惯行为一致的 console 对象,用于向标准输出流(stdout)或标准错误流(stderr)输出字符。
console 方法
以下为 console 对象的方法:
| 序号 | 方法 & 描述 |
|---|
| 1 | console.log([data][, ...])
向标准输出流打印字符并以换行符结束。该方法接收若干 个参数,如果只有一个参数,则输出这个参数的字符串形式。如果有多个参数,则 以类似于C 语言 printf() 命令的格式输出。 |
| 2 | console.info([data][, ...])
该命令的作用是返回信息性消息,这个命令与console.log差别并不大,除了在chrome中只会输出文字外,其余的会显示一个蓝色的惊叹号。 |
| 3 | console.error([data][, ...])
输出错误消息的。控制台在出现错误时会显示是红色的叉子。 |
| 4 | console.warn([data][, ...])
输出警告消息。控制台出现有黄色的惊叹号。 |
| 5 | console.dir(obj[, options])
用来对一个对象进行检查(inspect),并以易于阅读和打印的格式显示。 |
| 6 | console.time(label)
输出时间,表示计时开始。 |
| 7 | console.timeEnd(label)
结束时间,表示计时结束。 |
| 8 | console.trace(message[, ...])
当前执行的代码在堆栈中的调用路径,这个测试函数运行很有帮助,只要给想测试的函数里面加入 console.trace 就行了。 |
| 9 | console.assert(value[, message][, ...])
用于判断某个表达式或变量是否为真,接手两个参数,第一个参数是表达式,第二个参数是字符串。只有当第一个参数为false,才会输出第二个参数,否则不会有任何结果。 |
console.log():向标准输出流打印字符并以换行符结束。
console.log 接受若干 个参数,如果只有一个参数,则输出这个参数的字符串形式。如果有多个参数,则 以类似于C 语言 printf() 命令的格式输出。
第一个参数是一个字符串,如果没有 参数,只打印一个换行。
console.log('Hello world');
console.log('byvoid%diovyb');
console.log('byvoid%diovyb', 1991);
运行结果为:
Hello world
byvoid%diovyb
byvoid1991iovyb
console.trace();
运行结果为:
Trace:
at Object.<anonymous> (/home/byvoid/consoletrace.js:1:71)
at Module._compile (module.js:441:26)
at Object..js (module.js:459:10)
at Module.load (module.js:348:31)
at Function._load (module.js:308:12)
at Array.0 (module.js:479:10)
at EventEmitter._tickCallback (node.js:192:40)
实例
创建文件 main.js ,代码如下所示:
console.info("程序开始执行:");
var counter = 10;
console.log("计数: %d", counter);
console.time("获取数据");
//
// 执行一些代码
//
console.timeEnd('获取数据');
console.info("程序执行完毕。")
执行 main.js 文件,代码如下所示:
$ node main.js
程序开始执行:
计数: 10
获取数据: 0ms
程序执行完毕
process
process 是一个全局变量,即 global 对象的属性。
它用于描述当前Node.js 进程状态的对象,提供了一个与操作系统的简单接口。通常在你写本地命令行程序的时候,少不了要 和它打交道。下面将会介绍 process 对象的一些最常用的成员方法。
| 序号 | 事件 & 描述 |
|---|
| 1 | exit
当进程准备退出时触发。 |
| 2 | beforeExit
当 node 清空事件循环,并且没有其他安排时触发这个事件。通常来说,当没有进程安排时 node 退出,但是 'beforeExit' 的监听器可以异步调用,这样 node 就会继续执行。 |
| 3 | uncaughtException
当一个异常冒泡回到事件循环,触发这个事件。如果给异常添加了监视器,默认的操作(打印堆栈跟踪信息并退出)就不会发生。 |
| 4 | Signal 事件
当进程接收到信号时就触发。信号列表详见标准的 POSIX 信号名,如 SIGINT、SIGUSR1 等。 |
实例
创建文件 main.js ,代码如下所示:
process.on('exit', function(code) {
// 以下代码永远不会执行
setTimeout(function() {
console.log("该代码不会执行");
}, 0);
console.log('退出码为:', code);
});
console.log("程序执行结束");
执行 main.js 文件,代码如下所示:
$ node main.js
程序执行结束
退出码为: 0
退出状态码
退出状态码如下所示:
| 状态码 | 名称 & 描述 |
|---|
| 1 | Uncaught Fatal Exception
有未捕获异常,并且没有被域或 uncaughtException 处理函数处理。 |
| 2 | Unused
保留 |
| 3 | Internal JavaScript Parse Error
JavaScript的源码启动 Node 进程时引起解析错误。非常罕见,仅会在开发 Node 时才会有。 |
| 4 | Internal JavaScript Evaluation Failure
JavaScript 的源码启动 Node 进程,评估时返回函数失败。非常罕见,仅会在开发 Node 时才会有。 |
| 5 | Fatal Error
V8 里致命的不可恢复的错误。通常会打印到 stderr ,内容为: FATAL ERROR |
| 6 | Non-function Internal Exception Handler
未捕获异常,内部异常处理函数不知为何设置为on-function,并且不能被调用。 |
| 7 | Internal Exception Handler Run-Time Failure
未捕获的异常, 并且异常处理函数处理时自己抛出了异常。例如,如果 process.on('uncaughtException') 或 domain.on('error') 抛出了异常。 |
| 8 | Unused
保留 |
| 9 | Invalid Argument
可能是给了未知的参数,或者给的参数没有值。 |
| 10 | Internal JavaScript Run-Time Failure
JavaScript的源码启动 Node 进程时抛出错误,非常罕见,仅会在开发 Node 时才会有。 |
| 12 | Invalid Debug Argument
设置了参数--debug 和/或 --debug-brk,但是选择了错误端口。 |
| 128 | Signal Exits
如果 Node 接收到致命信号,比如SIGKILL 或 SIGHUP,那么退出代码就是128 加信号代码。这是标准的 Unix 做法,退出信号代码放在高位。 |
Process 属性
Process 提供了很多有用的属性,便于我们更好的控制系统的交互:
| 序号. | 属性 & 描述 |
|---|
| 1 | stdout
标准输出流。 |
| 2 | stderr
标准错误流。 |
| 3 | stdin
标准输入流。 |
| 4 | argv
argv 属性返回一个数组,由命令行执行脚本时的各个参数组成。它的第一个成员总是node,第二个成员是脚本文件名,其余成员是脚本文件的参数。 |
| 5 | execPath
返回执行当前脚本的 Node 二进制文件的绝对路径。 |
| 6 | execArgv
返回一个数组,成员是命令行下执行脚本时,在Node可执行文件与脚本文件之间的命令行参数。 |
| 7 | env
返回一个对象,成员为当前 shell 的环境变量 |
| 8 | exitCode
进程退出时的代码,如果进程优通过 process.exit() 退出,不需要指定退出码。 |
| 9 | version
Node 的版本,比如v0.10.18。 |
| 10 | versions
一个属性,包含了 node 的版本和依赖. |
| 11 | config
一个包含用来编译当前 node 执行文件的 javascript 配置选项的对象。它与运行 ./configure 脚本生成的 "config.gypi" 文件相同。 |
| 12 | pid
当前进程的进程号。 |
| 13 | title
进程名,默认值为"node",可以自定义该值。 |
| 14 | arch
当前 CPU 的架构:'arm'、'ia32' 或者 'x64'。 |
| 15 | platform
运行程序所在的平台系统 'darwin', 'freebsd', 'linux', 'sunos' 或 'win32' |
| 16 | mainModule
require.main 的备选方法。不同点,如果主模块在运行时改变,require.main可能会继续返回老的模块。可以认为,这两者引用了同一个模块。 |
实例
创建文件 main.js ,代码如下所示:
// 输出到终端
process.stdout.write("Hello World!" + "\n");
// 通过参数读取
process.argv.forEach(function(val, index, array) {
console.log(index + ': ' + val);
});
// 获取执行路径
console.log(process.execPath);
// 平台信息
console.log(process.platform);
执行 main.js 文件,代码如下所示:
$ node main.js
Hello World!
0: node
1: /web/www/node/main.js
/usr/local/node/0.10.36/bin/node
darwin
方法参考手册
Process 提供了很多有用的方法,便于我们更好的控制系统的交互:
| 序号 | 方法 & 描述 |
|---|
| 1 | abort()
这将导致 node 触发 abort 事件。会让 node 退出并生成一个核心文件。 |
| 2 | chdir(directory)
改变当前工作进程的目录,如果操作失败抛出异常。 |
| 3 | cwd()
返回当前进程的工作目录 |
| 4 | exit([code])
使用指定的 code 结束进程。如果忽略,将会使用 code 0。 |
| 5 | getgid()
获取进程的群组标识(参见 getgid(2))。获取到得时群组的数字 id,而不是名字。
注意:这个函数仅在 POSIX 平台上可用(例如,非Windows 和 Android)。 |
| 6 | setgid(id)
设置进程的群组标识(参见 setgid(2))。可以接收数字 ID 或者群组名。如果指定了群组名,会阻塞等待解析为数字 ID 。
注意:这个函数仅在 POSIX 平台上可用(例如,非Windows 和 Android)。 |
| 7 | getuid()
获取进程的用户标识(参见 getuid(2))。这是数字的用户 id,不是用户名。
注意:这个函数仅在 POSIX 平台上可用(例如,非Windows 和 Android)。 |
| 8 | setuid(id)
设置进程的用户标识(参见setuid(2))。接收数字 ID或字符串名字。果指定了群组名,会阻塞等待解析为数字 ID 。
注意:这个函数仅在 POSIX 平台上可用(例如,非Windows 和 Android)。 |
| 9 | getgroups()
返回进程的群组 iD 数组。POSIX 系统没有保证一定有,但是 node.js 保证有。
注意:这个函数仅在 POSIX 平台上可用(例如,非Windows 和 Android)。 |
| 10 | setgroups(groups)
设置进程的群组 ID。这是授权操作,所有你需要有 root 权限,或者有 CAP_SETGID 能力。
注意:这个函数仅在 POSIX 平台上可用(例如,非Windows 和 Android)。 |
| 11 | initgroups(user, extra_group)
读取 /etc/group ,并初始化群组访问列表,使用成员所在的所有群组。这是授权操作,所有你需要有 root 权限,或者有 CAP_SETGID 能力。
注意:这个函数仅在 POSIX 平台上可用(例如,非Windows 和 Android)。 |
| 12 | kill(pid[, signal])
发送信号给进程. pid 是进程id,并且 signal 是发送的信号的字符串描述。信号名是字符串,比如 'SIGINT' 或 'SIGHUP'。如果忽略,信号会是 'SIGTERM'。 |
| 13 | memoryUsage()
返回一个对象,描述了 Node 进程所用的内存状况,单位为字节。 |
| 14 | nextTick(callback)
一旦当前事件循环结束,调用回到函数。 |
| 15 | umask([mask])
设置或读取进程文件的掩码。子进程从父进程继承掩码。如果mask 参数有效,返回旧的掩码。否则,返回当前掩码。 |
| 16 | uptime()
返回 Node 已经运行的秒数。 |
| 17 | hrtime()
返回当前进程的高分辨时间,形式为 [seconds, nanoseconds]数组。它是相对于过去的任意事件。该值与日期无关,因此不受时钟漂移的影响。主要用途是可以通过精确的时间间隔,来衡量程序的性能。
你可以将之前的结果传递给当前的 process.hrtime() ,会返回两者间的时间差,用来基准和测量时间间隔。 |
实例
创建文件 main.js ,代码如下所示:
// 输出当前目录
console.log('当前目录: ' + process.cwd());
// 输出当前版本
console.log('当前版本: ' + process.version);
// 输出内存使用情况
console.log(process.memoryUsage());
执行 main.js 文件,代码如下所示:
$ node main.js
当前目录: /web/com/runoob/nodejs
当前版本: v0.10.36
{ rss: 12541952, heapTotal: 4083456, heapUsed: 2157056 }15)
Node.js 常用工具
util 是一个Node.js 核心模块,提供常用函数的集合,用于弥补核心JavaScript 的功能 过于精简的不足。
util.inherits
util.inherits(constructor, superConstructor)是一个实现对象间原型继承 的函数。
JavaScript 的面向对象特性是基于原型的,与常见的基于类的不同。JavaScript 没有 提供对象继承的语言级别特性,而是通过原型复制来实现的。
在这里我们只介绍util.inherits 的用法,示例如下:
var util = require('util');
function Base() {
this.name = 'base';
this.base = 1991;
this.sayHello = function() {
console.log('Hello ' + this.name);
};
}
Base.prototype.showName = function() {
console.log(this.name);
};
function Sub() {
this.name = 'sub';
}
util.inherits(Sub, Base);
var objBase = new Base();
objBase.showName();
objBase.sayHello();
console.log(objBase);
var objSub = new Sub();
objSub.showName();
//objSub.sayHello();
console.log(objSub);
我们定义了一个基础对象Base 和一个继承自Base 的Sub,Base 有三个在构造函数 内定义的属性和一个原型中定义的函数,通过util.inherits 实现继承。运行结果如下:
base
Hello base
{ name: 'base', base: 1991, sayHello: [Function] }
sub
{ name: 'sub' }
注意:Sub 仅仅继承了Base 在原型中定义的函数,而构造函数内部创造的 base 属 性和 sayHello 函数都没有被 Sub 继承。
同时,在原型中定义的属性不会被console.log 作 为对象的属性输出。如果我们去掉 objSub.sayHello(); 这行的注释,将会看到:
node.js:201
throw e; // process.nextTick error, or 'error' event on first tick
^
TypeError: Object #<Sub> has no method 'sayHello'
at Object.<anonymous> (/home/byvoid/utilinherits.js:29:8)
at Module._compile (module.js:441:26)
at Object..js (module.js:459:10)
at Module.load (module.js:348:31)
at Function._load (module.js:308:12)
at Array.0 (module.js:479:10)
at EventEmitter._tickCallback (node.js:192:40)
util.inspect
util.inspect(object,[showHidden],[depth],[colors])是一个将任意对象转换 为字符串的方法,通常用于调试和错误输出。它至少接受一个参数 object,即要转换的对象。
showHidden 是一个可选参数,如果值为 true,将会输出更多隐藏信息。
depth 表示最大递归的层数,如果对象很复杂,你可以指定层数以控制输出信息的多 少。如果不指定depth,默认会递归2层,指定为 null 表示将不限递归层数完整遍历对象。 如果color 值为 true,输出格式将会以ANSI 颜色编码,通常用于在终端显示更漂亮 的效果。
特别要指出的是,util.inspect 并不会简单地直接把对象转换为字符串,即使该对 象定义了toString 方法也不会调用。
var util = require('util');
function Person() {
this.name = 'byvoid';
this.toString = function() {
return this.name;
};
}
var obj = new Person();
console.log(util.inspect(obj));
console.log(util.inspect(obj, true));
运行结果是:
Person { name: 'byvoid', toString: [Function] }
Person {
name: 'byvoid',
toString:
{ [Function]
[length]: 0,
[name]: '',
[arguments]: null,
[caller]: null,
[prototype]: { [constructor]: [Circular] } } }
util.isArray(object)
如果给定的参数 "object" 是一个数组返回true,否则返回false。
var util = require('util');
util.isArray([])
// true
util.isArray(new Array)
// true
util.isArray({})
// false
util.isRegExp(object)
如果给定的参数 "object" 是一个正则表达式返回true,否则返回false。
var util = require('util');
util.isRegExp(/some regexp/)
// true
util.isRegExp(new RegExp('another regexp'))
// true
util.isRegExp({})
// false
util.isDate(object)
如果给定的参数 "object" 是一个日期返回true,否则返回false。
var util = require('util');
util.isDate(new Date())
// true
util.isDate(Date())
// false (without 'new' returns a String)
util.isDate({})
// false
util.isError(object)
如果给定的参数 "object" 是一个错误对象返回true,否则返回false。
var util = require('util');
util.isError(new Error())
// true
util.isError(new TypeError())
// true
util.isError({ name: 'Error', message: 'an error occurred' })
// false
更多详情可以访问 http://nodejs.org/api/util.html 了解详细内容。
来自 http://www.runoob.com/nodejs/nodejs-tutorial.html