欢迎各位兄弟 发布技术文章
这里的技术是共享的
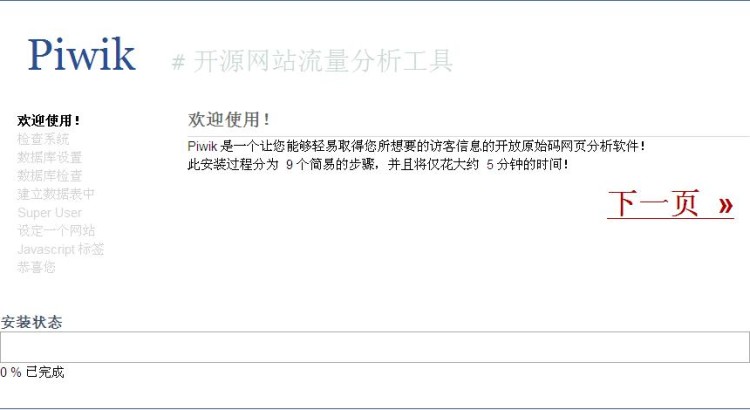
无论是要进行著名的五分钟安装,还是希望更详细的安装指导,下面的资料都会提供一定帮助。
该文档根据piwik的官方文档进行的翻译,由于英文水平有限,所以如果出错的话,希望能告知,有关插件开发的部分,本人根据示例已做过插件的开发,但有个问题还未解决,会尽快解决更新上来。Email:zhang845742658@126.com qq:845742658 所有标准统计报告:关键词和搜索引擎,网站页面url,页面标题,用户国家,供应商,操作系统,浏览器市场份额,屏幕分辨率,桌面和移动, 约束(每访问网站,页面上的时间,重复访问),关键活动,自定义变量,进入/退出页面,下载文件,和更多的,分为四个主要类别分析报告——游客行为,反向链接,目标/电子商务(30 +报告)。看到Piwik之旅。1. 实时数据更新。2. 可定制仪表盘3. 所有网站指示数据4. 行进化5. 电子商务分析6. 目标转换跟踪7. 事件跟踪8. 设置搜索系统9. 定位10. 页面转换11. 页面覆盖物
JavaScript 获取当前时间戳:
第一种方法:
如果您启用了“网络与应用活动记录”,系统会将您在其他 Google 服务中的搜索和活动记录保存到您的 Google 帐号,以便您获取最佳的搜索结果和建议。
实例显示按了哪个键: